#多模态
共 676 篇相关文章
·6 分钟
Cherry Studio:统一接入300+大模型的开源AI生产力工具详解
深入解析Cherry Studio开源AI客户端,支持统一接入OpenAI、Claude、Gemini等300+大模型,集成自主代理与预置助手功能,GitHub近4.7万Star。本文详解其核心功能、技术架构及适用场景。
阅读全文 →

·5 分钟
Gemini macOS版新功能:双击Command键即可分析屏幕内容
Google为Gemini macOS应用推出屏幕感知新功能,用户双击Command键即可将当前窗口内容附加到AI对话中,无需截图即可获得上下文相关的智能帮助,大幅简化AI交互流程。
阅读全文 →

·4 分钟
Gemini Live图像创建功能详解:实时对话生成与编辑图片
Google Gemini Live新增实时图像创建与编辑功能,支持在对话中通过语音和摄像头完成图片生成、室内装饰测试、数学辅助等任务,了解功能亮点与使用方法。
阅读全文 →

·7 分钟
AI基准测试:当前最被低估的技术创业机会
AI基准测试正成为巨大的创业机会。传统评测被刷爆、供需严重失衡,谁能构建高质量公共AI基准测试,谁就掌握行业话语权。本文解析为何AI评测基础设施是高回报的差异化路径。
阅读全文 →

·4 分钟
iOS 28与iPhone二十周年:苹果即将迎来史诗级大变革
苹果iOS 28系统更新将配合iPhone二十周年发布,带来全面重新设计的硬件与软件协同革新。了解为何28系列更新远超27系列,以及这次大变革对开发者和消费者意味着什么。
阅读全文 →

·3 分钟
Runway实时视频角色新增工具调用能力,从对话迈向智能执行
Runway实时视频角色功能升级,新增工具调用能力,AI视频代理可执行信息查询、任务操作等实际指令,标志着视频AI从内容生成向智能代理平台的关键跨越。
阅读全文 →
·4 分钟
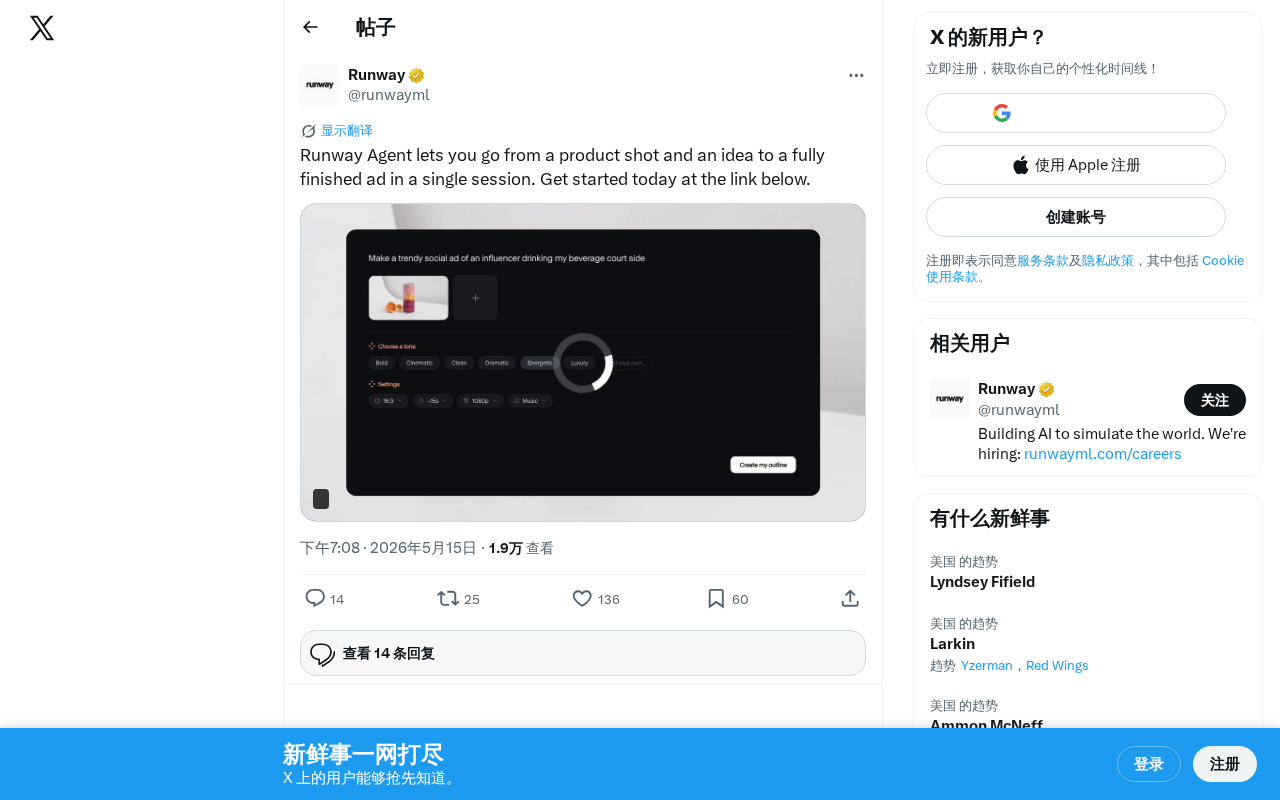
Runway Agent功能详解:一张产品照片自动生成完整广告视频
深度解析Runway Agent的AI视频生成能力,了解如何通过一张产品照片和创意描述,在单次会话中自动完成广告视频制作,以及这一功能对广告行业的实际影响。
阅读全文 →

·4 分钟
Gemini Omni详解:多模态理解与视频编辑的重大突破
深入解析Google Gemini Omni的核心能力:支持图片、视频、音频多模态输入,实现交互式视频生成与编辑,从理解到创造的全模态AI如何改变内容创作流程。
阅读全文 →

·3 分钟
Gemini Omni一句提示词生成史诗级电影预告片
Google Gemini Omni模型仅用一个提示词生成罗马史诗《埃涅阿斯纪》电影预告片,并展示视频编辑能力——直接修改已生成画面中的错误元素,无需重新生成。这种生成+迭代编辑的工作流程正在重新定义AI视频创作的可能性。
阅读全文 →

·3 分钟
Gemini 3.5 Flash早期体验:速度与能力的平衡之道
开发者抢先体验Google最新Gemini 3.5 Flash模型,实测显示其速度快、编码能力强且具备自我纠错能力。本文深度解析这款轻量级模型的核心表现、实际测试与产品定位,助你判断它是否值得纳入开发工具箱。
阅读全文 →

·5 分钟
Gemini Omni多模态理解力测试:荒诞场景提示词挑战AI极限
Google Gemini Omni模型通过一个极其荒诞的提示词测试,展示了在复杂多模态理解方面的惊人能力。本文解析这一创意压力测试背后的语义理解、跨领域知识整合与创意生成能力边界。
阅读全文 →

·5 分钟
Ben James谈创造力:荒诞想法为何是创新的关键
创客Ben James分享为什么荒诞的想法(silly ideas)对创造力至关重要。探讨在AI时代如何通过实验精神、玩乐心态和无目的探索来激发真正的创新突破。
阅读全文 →

·4 分钟
OpenAI Showcase暗藏玄机:隐藏功能预告全解读
OpenAI发布神秘推文暗示Showcase中隐藏未公开新功能。本文深度解读这条预告的可能方向,分析OpenAI悬念营销策略,并提供后续动态关注建议。
阅读全文 →

·6 分钟
AI产品的"魔法疲劳"效应:用户期望管理的隐形挑战
探讨AI产品中的"魔法疲劳"效应:用户为何觉得AI变笨了?如何区分真实性能退化与期望攀升?AI团队应对用户期望管理的策略与实践。
阅读全文 →

·5 分钟
Gemini Omni是什么?Google AI故事创作工具深度解析
Google推出Gemini Omni,定位为多模态AI故事创作工具。本文解析Gemini Omni的核心功能、多模态叙事能力及其在AI创作领域的差异化优势,探讨从构思到呈现的端到端创作体验。
阅读全文 →

·6 分钟
谷歌Gemini 3.5 Flash发布:主打智能体与编程能力的代际升级
谷歌正式发布Gemini 3.5系列首款模型Flash,跳过3.0版本实现代际飞跃,主打智能体和编程两大核心能力,定位为连接前沿智能与现实世界行动的新一代AI模型。
阅读全文 →

·6 分钟
Google Flow接入Gemini Omni:AI视频创作迎来重大升级
Google I/O大会上,AI视频创作工具Flow与Gemini Omni模型深度整合,带来批量编辑、角色一致性提升等核心更新,降低电影级内容创作门槛。详解三大升级亮点与行业竞争格局。
阅读全文 →

·2 分钟
ChatGPT图像生成在印度爆发:已创建超10亿张图片
OpenAI CEO Sam Altman透露ChatGPT Images 2.0在印度已创建超10亿张图片。印度成为AI图像生成最大市场之一,GPT-4o原生图像能力获得市场充分验证,新兴市场正重塑全球AI应用格局。
阅读全文 →

