#多Token预测
共 7 篇相关文章
 教程攻略
教程攻略·10 分钟
llama.cpp MTP加速部署指南:配置步骤与性能实测
详解llama.cpp如何启用MTP多Token预测加速技术,涵盖CUDA环境配置、桌面端设置、模型选择及实测性能数据,Qwen3 27B实测近60 Token/s。
阅读全文 →
 教程攻略
教程攻略·8 分钟
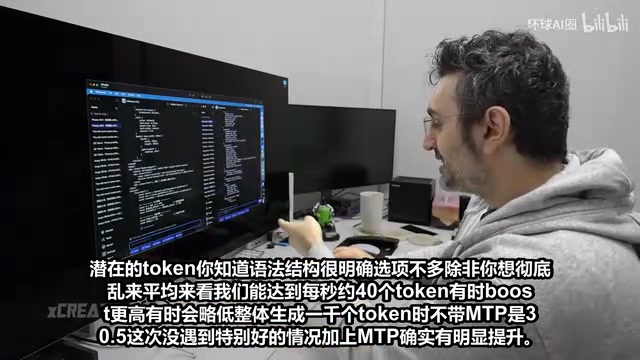
DeepSeek V4 Flash MTP推测解码实测:本地推理提速20%指南
实测DeepSeek V4 Flash开启MTP推测解码后的性能表现:代码生成场景提速约20%,文本生成提升有限。详解内存开销、准确性差异、Q4与Q3量化对比,以及通过Inference应用和OpenAI兼容API的完整部署教程。
阅读全文 →
 产品体验
产品体验·7 分钟
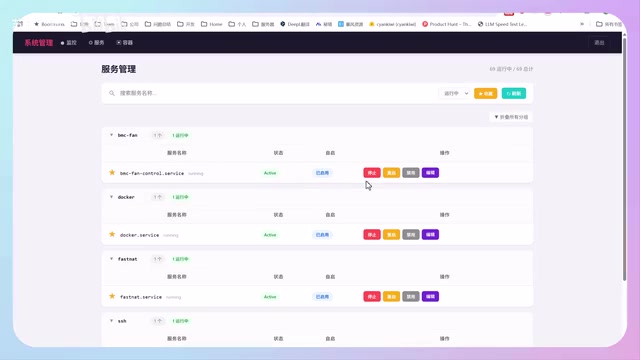
4×3080Ti本地部署千问3.6 27B跑OpenCode编程实测
使用4张3080Ti 16G魔改显卡本地部署千问3.6 27B FP8模型,配合OpenCode完成系统管理工具开发的完整实测。涵盖硬件配置、推理速度、上下文管理经验及开发效率对比。
阅读全文 →
 产品体验
产品体验·4 分钟
Qwen3.6 27B三大邪修量化模型实测:代码暴增15.8PP、40B蒸馏、16GB适配
实测对比三款基于Qwen3.6 27B的社区邪修量化模型:OmniMerge V4代码能力提升15.8个百分点,40B OPUS蒸馏版支持角色扮演与创意写作,16GB特化版让小显存也能跑稠密模型。附显存要求、参数设置与选型建议。
阅读全文 →
 科技前沿
科技前沿·4 分钟
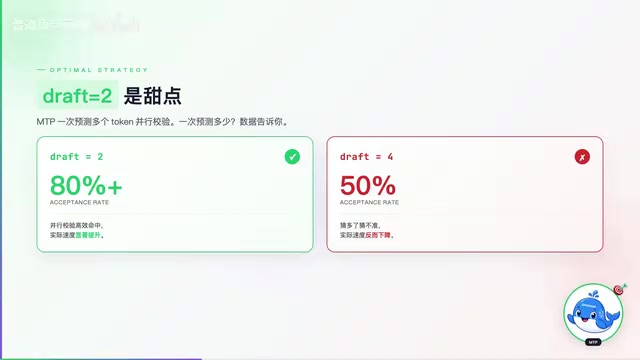
Qwen3.6 MTP加速实测:单GPU推理飙到220 token/s
Qwen3.6实验性MTP-GGUF版本实测,单GPU将35B-A3B模型推理速度提升至220 token/s,比原版快1.4倍且精度零损失。详解MTP原理、最优Draft Tokens策略及RTX 5090实测数据。
阅读全文 →
 产品体验
产品体验·2 分钟
Qwen 3.6 MTP实测:三行参数提速20%的秘密
实测Qwen 3.6多Token预测(MTP)技术,通过ik_llama.cpp仅需三个参数即可将推理速度从34.2提升至41 tokens/s,零质量损失、零额外模型的免费提速方案。附MTP与DFlash对比及完整配置教程。
阅读全文 →
