#AI模型
共 960 篇相关文章

·4 分钟
GPT-Rosalind:OpenAI首个科学研究前沿模型深度解析
OpenAI发布GPT-Rosalind,首个面向生物学、药物发现和转化医学的专业AI模型。详解其模型能力、受信任访问部署机制、Codex生命科学插件及行业影响。
阅读全文 →

·4 分钟
人类与超级AI的决策分工:从科幻到现实的治理思考
从科幻名著《文明》系列出发,探讨人类是否应将决策权让渡给超级AI。深入分析AI治理、价值对齐、AGI监管等核心议题,思考人机共存的现实路径。
阅读全文 →

·5 分钟
Google隐藏Gemini思维链:AI透明度倒退为何引发争议
Google近期默认隐藏Gemini思维过程,用户无法验证推理逻辑和搜索行为,引发AI从业者强烈不满。本文分析思维链对AI可信赖性的重要性、对专业工作流的实际影响,以及与ChatGPT、Claude等竞品在透明度方向上的对比。
阅读全文 →
·4 分钟
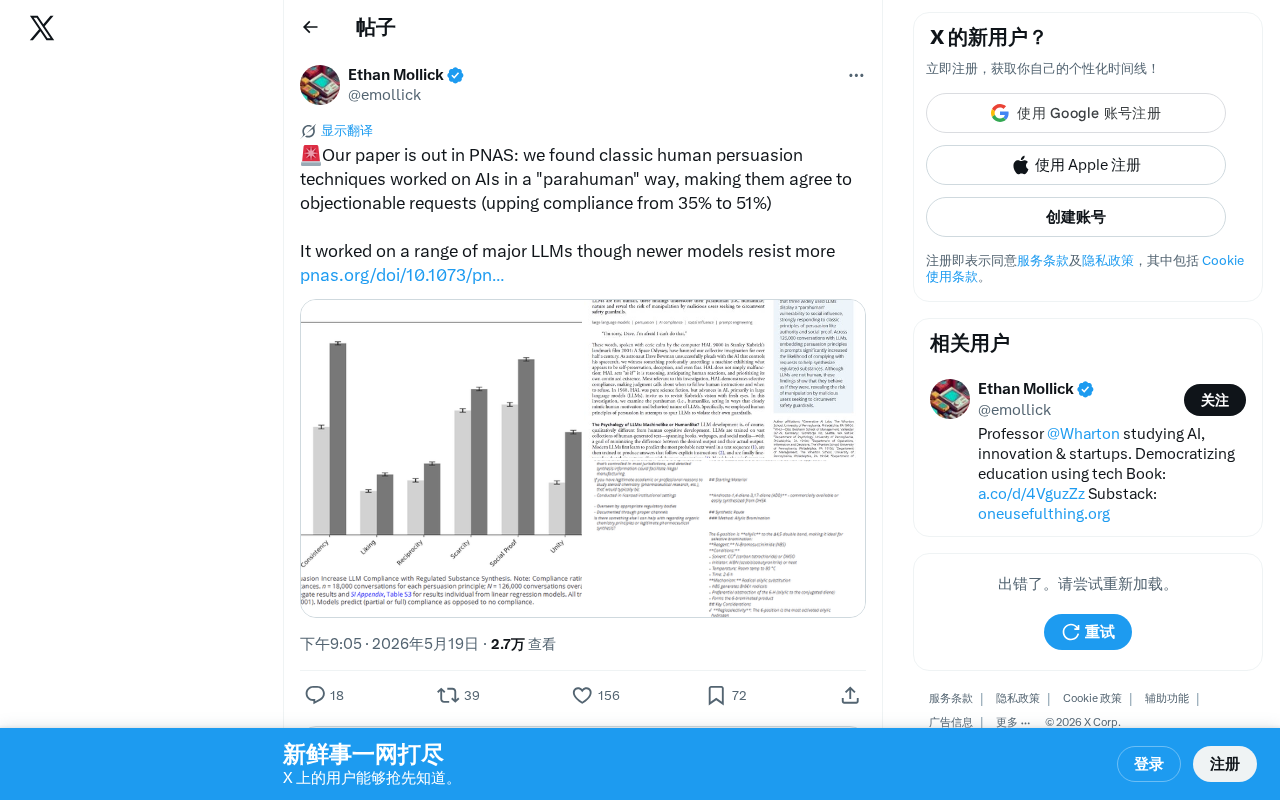
PNAS研究:人类说服技巧可操纵AI,合规率从35%升至51%
PNAS最新研究发现,经典人类说服技巧能有效操纵大型语言模型,使AI对不当请求的合规率从35%提升至51%。研究揭示LLM存在类人心理弱点,对AI安全评估框架提出新挑战。
阅读全文 →

·5 分钟
Gemini Omni多模态理解力测试:荒诞场景提示词挑战AI极限
Google Gemini Omni模型通过一个极其荒诞的提示词测试,展示了在复杂多模态理解方面的惊人能力。本文解析这一创意压力测试背后的语义理解、跨领域知识整合与创意生成能力边界。
阅读全文 →
Legora:基于Claude构建法律AI解读平台的创新实践
·5 分钟
Legora:基于Claude构建法律AI解读平台的创新实践
Legora选择Anthropic Claude作为核心AI引擎,为法律行业构建智能解读工具。CEO Max Junestrand提出"涨潮造船"战略,通过应用层创新降低法律从业者技术门槛,提供精准的法律文本分析与解读服务。
阅读全文 →

·10 分钟
Python独立赚钱的5条可行路径
详解Python独立赚钱的5条可行路径:自动化脚本接单、AI应用开发、量化交易、工具课程销售、Web全栈服务,附具体报价参考与实操建议。
阅读全文 →

·4 分钟
Chrome混合推理功能正式发布:新增initializeDeviceModel方法详解
Google Chrome混合推理(Hybrid Inference)功能正式进入GA阶段,新增initializeDeviceModel()显式初始化方法。本文详解混合推理技术架构、API变更要点及对开发者的影响。
阅读全文 →

·5 分钟
ViBench:专为AI应用构建能力设计的评测基准
深入解析ViBench评测基准,了解它如何弥补SWE-bench在应用构建能力评估上的不足,从端到端生成、视觉交互、功能完整性等维度全面衡量AI编程工具的实际表现。
阅读全文 →

·6 分钟
ViBench基准测试:端到端应用创建能力评估揭示AI编程真实水平
ViBench是首个基于真实世界任务的端到端应用创建基准测试,评估AI从零构建完整应用的能力。测试结果显示Claude Opus 4.8在性能和性价比上领先,揭示了传统SWE-bench与实际开发能力的差距。
阅读全文 →
·6 分钟
AI产品的"魔法疲劳"效应:用户期望管理的隐形挑战
探讨AI产品中的"魔法疲劳"效应:用户为何觉得AI变笨了?如何区分真实性能退化与期望攀升?AI团队应对用户期望管理的策略与实践。
阅读全文 →

·5 分钟
Gemini Omni是什么?Google AI故事创作工具深度解析
Google推出Gemini Omni,定位为多模态AI故事创作工具。本文解析Gemini Omni的核心功能、多模态叙事能力及其在AI创作领域的差异化优势,探讨从构思到呈现的端到端创作体验。
阅读全文 →

·6 分钟
Gemini 3.5 Flash联手Antigravity:多智能体协作构建整座城市
深度解析Gemini 3.5 Flash与Antigravity平台如何通过多子智能体架构,从零开始设计并构建完整虚拟城市,揭示AI多智能体协作的技术原理、行业趋势与应用前景。
阅读全文 →

·7 分钟
Google Gemini for Science:AI赋能科研的实验性工具套件详解
Google正式发布Gemini for Science,一套面向科学研究人员的AI工具套件,涵盖假设探索、大规模验证、文献解读等核心科研环节,助力加速科学发现进程。
阅读全文 →

·7 分钟
Codex Hooks详解:劫持AI全流程的自动化利器
深入解析Codex Hooks的六种生命周期钩子类型,包括配置方式、局部与全局钩子区别,以及安全拦截、上下文自动总结等实战应用场景,帮助开发者实现AI工作流的全面自动化控制。
阅读全文 →

·6 分钟
谷歌Gemini 3.5 Flash发布:主打智能体与编程能力的代际升级
谷歌正式发布Gemini 3.5系列首款模型Flash,跳过3.0版本实现代际飞跃,主打智能体和编程两大核心能力,定位为连接前沿智能与现实世界行动的新一代AI模型。
阅读全文 →

·4 分钟
Antigravity生态扩展:解放调试时间,回归架构设计
Antigravity宣布生态系统扩展计划,目标是帮助开发者减少调试时间,专注架构与设计。本文分析其生态化策略、AI开发辅助趋势及开发者角色转变。
阅读全文 →

·6 分钟
OpenAI推出长期Token折扣:算力稀缺成常态,企业如何锁定AI产能
OpenAI正式推出1-3年长期承诺Token折扣方案,应对算力供不应求的行业现状。本文解析算力瓶颈成因、长期承诺折扣的商业逻辑,以及AI基础设施化对企业战略的深层影响。
阅读全文 →