#Multi-Token Prediction
共 11 篇相关文章
 深度解读
深度解读·6 分钟
大模型设计的"差就好"哲学:简单粗暴为何胜过精致复杂
解析大模型架构设计中的"差就好"哲学:为什么DeepSeek V4弃用N-gram?为什么Transformer统治AI领域?从硬件对齐、快速迭代、统一架构三条铁律,揭示简单高效的模型设计为何总能胜过精致复杂的方案。
阅读全文 →
 教程攻略
教程攻略·10 分钟
llama.cpp MTP加速部署指南:配置步骤与性能实测
详解llama.cpp如何启用MTP多Token预测加速技术,涵盖CUDA环境配置、桌面端设置、模型选择及实测性能数据,Qwen3 27B实测近60 Token/s。
阅读全文 →
 教程攻略
教程攻略·9 分钟
oMLX+MTP+Qwen3.6:本地AI编程速度突破新极限
使用oMLX推理引擎结合MTP多令牌预测技术和Qwen3.6 35B模型,在Apple Silicon Mac上实现86.7 tokens/s的本地编程速度,5分钟内完成全栈应用开发的完整实战解析。
阅读全文 →
 科技前沿
科技前沿·6 分钟
SGLang v0.5.12.post1发布:DeepSeek V4稳定性修复与Blackwell适配
SGLang v0.5.12.post1稳定性补丁详解,包含12项关键修复,涵盖DeepSeek V4乱码与崩溃问题、NIXL PD分离式推理逻辑修复、Blackwell B300架构适配及冷启动性能优化。
阅读全文 →
 行业洞察
行业洞察·7 分钟
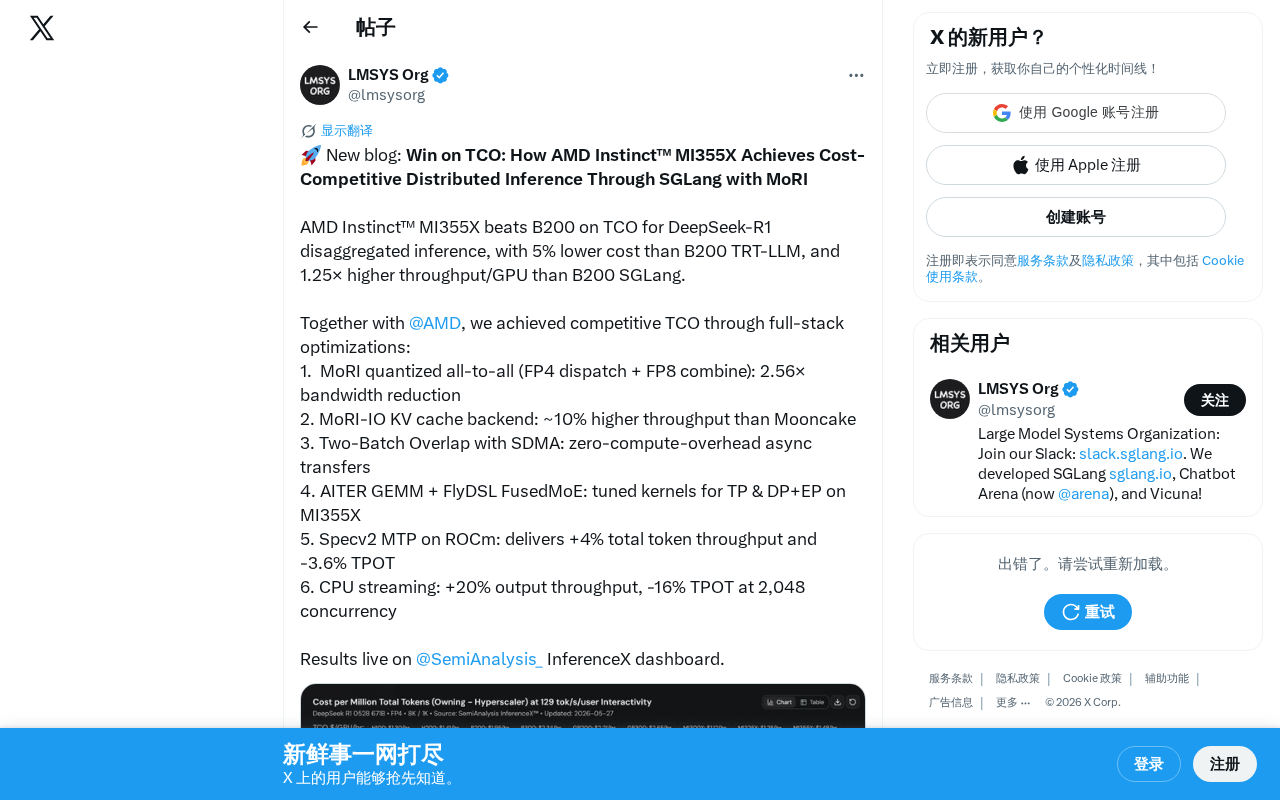
AMD MI355X击败B200:DeepSeek-R1推理TCO低5%的全栈优化解析
AMD Instinct MI355X通过SGLang+MoRI全栈优化,在DeepSeek-R1分离式推理中实现TCO比NVIDIA B200低5%,每GPU吞吐量高1.25倍。深度解析MoRI量化通信、KV Cache优化及推测解码等核心技术突破。
阅读全文 →
 教程攻略
教程攻略·8 分钟
DeepSeek V4 Flash MTP推测解码实测:本地推理提速20%指南
实测DeepSeek V4 Flash开启MTP推测解码后的性能表现:代码生成场景提速约20%,文本生成提升有限。详解内存开销、准确性差异、Q4与Q3量化对比,以及通过Inference应用和OpenAI兼容API的完整部署教程。
阅读全文 →
 科技前沿
科技前沿·8 分钟
xAI与SpaceX合并、GPT-5.5-Cyber预览、Gemini 3.1 Flash发布
马斯克宣布xAI与SpaceX合并更名SpaceX AI,OpenAI推出GPT-5.5-Cyber安全模型,Google发布Gemini 3.1 Flash轻量模型,Airbnb透露AI编写60%新代码。全方位解读AI产业最新动态。
阅读全文 →
 产品体验
产品体验·7 分钟
4×3080Ti本地部署千问3.6 27B跑OpenCode编程实测
使用4张3080Ti 16G魔改显卡本地部署千问3.6 27B FP8模型,配合OpenCode完成系统管理工具开发的完整实测。涵盖硬件配置、推理速度、上下文管理经验及开发效率对比。
阅读全文 →
 科技前沿
科技前沿·4 分钟
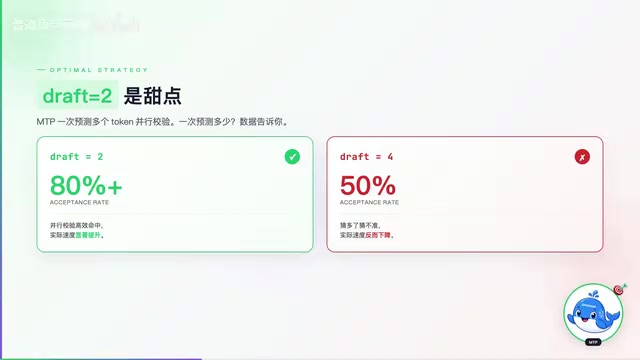
Qwen3.6 MTP加速实测:单GPU推理飙到220 token/s
Qwen3.6实验性MTP-GGUF版本实测,单GPU将35B-A3B模型推理速度提升至220 token/s,比原版快1.4倍且精度零损失。详解MTP原理、最优Draft Tokens策略及RTX 5090实测数据。
阅读全文 →
 产品体验
产品体验·2 分钟
Qwen 3.6 MTP实测:三行参数提速20%的秘密
实测Qwen 3.6多Token预测(MTP)技术,通过ik_llama.cpp仅需三个参数即可将推理速度从34.2提升至41 tokens/s,零质量损失、零额外模型的免费提速方案。附MTP与DFlash对比及完整配置教程。
阅读全文 →
 科技前沿
科技前沿·10 分钟
Step 3.5 Flash深度解析:1960亿参数开源模型击败Gemini的秘密
深度解析阶跃星辰Step 3.5 Flash开源模型:1960亿参数MoE架构仅激活110亿,编码速度350 token/秒,支持256K上下文窗口,可本地部署。详解其如何在Agent和编码任务中击败Gemini 3 Flash。
阅读全文 →