#Qwen3
共 61 篇相关文章
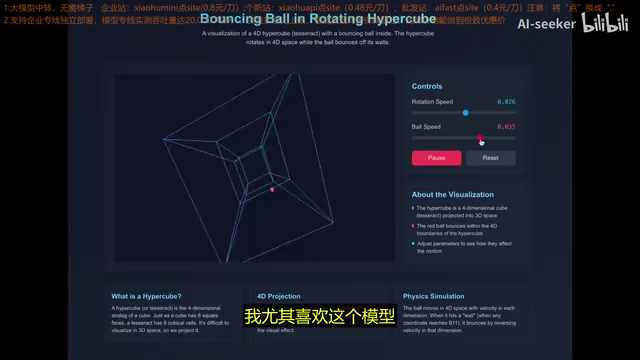 产品体验
产品体验·8 分钟
Qwen Code CLI实测:阿里开源AI编码代理安装配置全指南
详细实测阿里巴巴开源的Qwen Code CLI命令行编码工具,涵盖安装配置、API密钥设置、实际开发体验及与Claude Code对比。基于通义零码4800亿参数MoE模型,免费开源的AI编程助手。
阅读全文 →
 观点碰撞
观点碰撞·9 分钟
AI周报:Qwen3VL本地部署、Karpathy Agent观点与AI炒币实验
AI周报终章涵盖Qwen3VL多版本发布及M1 MacBook本地部署实测、Claude Haiku 4.5编程能力评测、Karpathy nano-chat开源项目与Agent十年论、Nof1让7个AI模型用真金白银炒币的社会实验,以及AI生成内容超越人类产出的深度观察。
阅读全文 →
 教程攻略
教程攻略·10 分钟
Claude Code安装教程:Windows环境配置+接入阿里云百炼免费模型
详细讲解Claude Code在Windows系统的完整安装配置流程,包括Git和Node.js环境准备、环境变量设置、绕过校验方法,以及接入阿里云百炼免费大模型的具体步骤,助你零成本搭建AI编程助手。
阅读全文 →
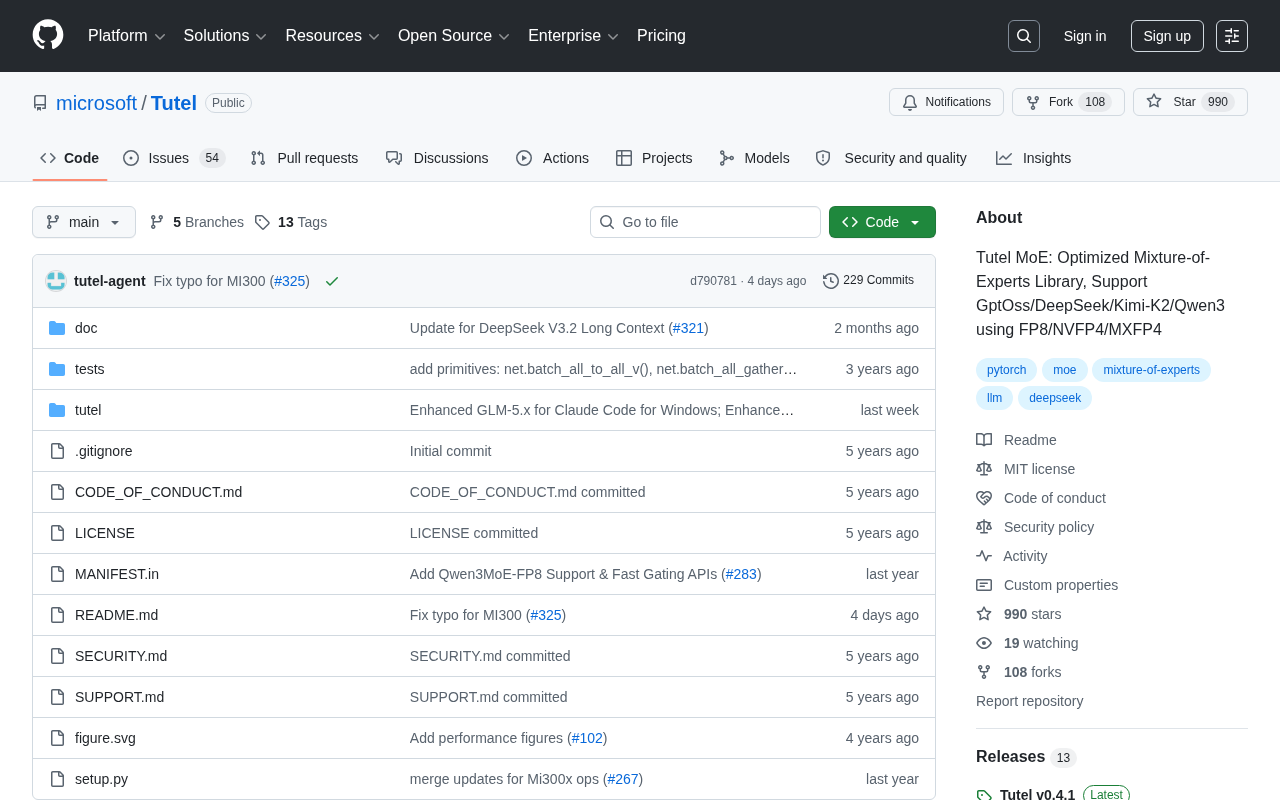 深度解读
深度解读·8 分钟
微软Tutel:MoE模型加速库深度解析,支持FP4/FP8低精度计算
深度解析微软开源Tutel MoE优化库,支持FP8、NVFP4、MXFP4多精度计算,适配DeepSeek、Kimi-K2、Qwen3等主流MoE模型,解决All-to-All通信瓶颈与显存管理难题。
阅读全文 →
 科技前沿
科技前沿·5 分钟
Qwen在SWE-bench持续领跑:开源AI编程模型的崛起
Qwen团队在SWE-bench基准测试中持续领跑开源模型,展现出强大的软件工程能力。本文解析SWE-bench评测标准、Qwen系列模型的进步历程,以及开源AI编程工具对开发者的实际价值。
阅读全文 →
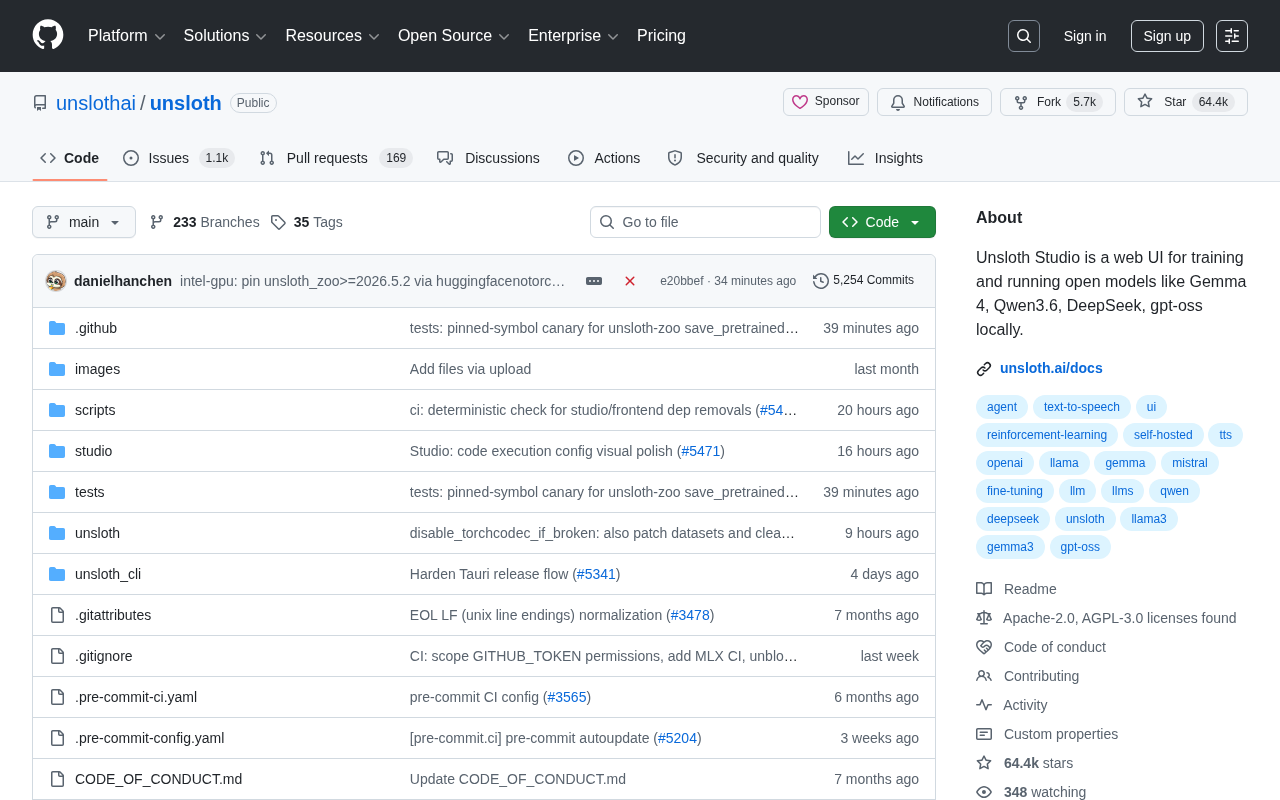 产品体验
产品体验·7 分钟
Unsloth:显存优化80%,本地微调大模型的最佳开源工具
Unsloth是GitHub 63K+ Star的开源大模型训练工具,支持Gemma 4、Qwen 3、DeepSeek等主流模型。通过显存优化降低50%-80%显存占用,让RTX 4090也能微调7B模型,提供Web UI一键训练。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Unsloth教程:本地微调大模型省显存提速5倍
详解Unsloth开源工具如何通过LoRA优化和Web UI界面,让消费级显卡也能高效微调Gemma 4、Qwen3、DeepSeek等主流大模型,训练速度提升2-5倍,显存降低50%-70%。
阅读全文 →
 教程攻略
教程攻略·7 分钟
Unsloth教程:本地微调大模型速度提升数倍,显存节省60%
Unsloth是GitHub 63K星标的开源大模型微调工具,支持Gemma 4、Qwen3、DeepSeek等模型。通过底层内核优化实现训练加速数倍、显存大幅降低,消费级GPU即可完成微调,提供Web UI图形界面,适合个人开发者和企业私有化部署。
阅读全文 →
 教程攻略
教程攻略·7 分钟
Unsloth教程:本地微调大模型省显存加速训练指南
详解Unsloth开源工具如何在本地高效微调大模型,支持Gemma 4、Qwen3、DeepSeek等主流模型,通过LoRA优化显著降低显存占用,提供Web UI界面降低训练门槛,适合个人开发者和中小团队使用。
阅读全文 →
 产品体验
产品体验·5 分钟
Unsloth:本地微调大模型的高效开源工具
Unsloth是GitHub上超63000星的开源项目,提供Web UI界面支持本地训练和微调Gemma 4、Qwen3、DeepSeek等主流大模型,大幅降低硬件门槛和技术难度,适合个人开发者和企业私有化部署。
阅读全文 →
 产品体验
产品体验·2 分钟
Unsloth:本地训练开源大模型的利器
阅读全文 →
 产品体验
产品体验·2 分钟
Unsloth:本地训练和运行开源大模型的利器
阅读全文 →
 教程攻略
教程攻略·8 分钟
Ollama教程:本地运行DeepSeek等大模型的最简方案
详解Ollama本地部署大模型的完整指南,支持DeepSeek、Qwen、Kimi-K2.5等主流模型。了解这款17万Star开源工具如何实现一键安装、离线推理,以及适用场景与生态集成方案。
阅读全文 →
 产品体验
产品体验·8 分钟
Unsloth:单卡微调大模型,显存省70%的开源神器
Unsloth 是 GitHub 63K+ Star 的开源大模型微调工具,支持 Gemma 4、Qwen 3、DeepSeek 等主流模型。通过显存优化技术,单张 RTX 3090 即可完成微调,训练速度提升2-5倍,附 Web UI 图形界面,零门槛上手。
阅读全文 →
 产品体验
产品体验·12 分钟
Unsloth:本地微调大模型速度提升5倍的开源利器
Unsloth是GitHub 63K+星标的开源大模型微调工具,支持Gemma 4、Qwen 3、DeepSeek等主流模型,通过LoRA/QLoRA技术将训练速度提升2-5倍,显存降低80%,提供Web UI界面让本地微调大模型变得简单高效。
阅读全文 →
 产品体验
产品体验·13 分钟
Unsloth:本地微调大模型速度提升5倍的开源神器
Unsloth 是 GitHub 63000+ Star 的开源大模型训练工具,支持 Gemma 4、Qwen3、DeepSeek 等主流模型的本地微调,提供 Web UI 界面、显存优化和 2-5 倍训练加速,让消费级 GPU 也能跑通模型微调全流程。
阅读全文 →
 产品体验
产品体验·7 分钟
Unsloth:免费本地训练大模型神器,6万星开源项目详解
Unsloth是GitHub上6.3万星的开源大模型本地训练工具,支持Gemma 4、Qwen 3、DeepSeek等主流模型微调,提供Web UI图形界面,大幅降低LLM微调门槛。本文详解其核心功能、技术优势与适用场景。
阅读全文 →
 产品体验
产品体验·11 分钟
Unsloth:本地训练开源大模型的高效工具,6万星标的秘密
深入解析Unsloth这款GitHub 6万+星标的开源大模型训练工具,支持Gemma 4、Qwen3、DeepSeek等主流模型的本地微调与推理,通过LoRA/QLoRA技术大幅降低显存需求,助力开发者在消费级显卡上高效训练大模型。
阅读全文 →
 产品体验
产品体验·8 分钟
Unsloth:本地微调大模型的最佳开源工具(2025指南)
Unsloth 是 GitHub 6.3万星标的开源大模型训练工具,支持 Gemma 4、Qwen3、DeepSeek 等主流模型的本地微调与部署。提供 Web UI 界面,显存占用降低50%,训练速度提升2-5倍,适合企业和个人开发者使用。
阅读全文 →
 教程攻略
教程攻略·7 分钟
Unsloth本地大模型微调工具:6万星标的Web UI如何让消费级显卡跑起Gemma 4、Qwen3.6和DeepSeek
深度解析Unsloth开源项目:通过Web UI实现本地大模型微调与推理,支持Gemma 4、Qwen3.6、DeepSeek等主流模型,显存降低70%,速度提升5倍。
阅读全文 →