Claude Opus 4.8 Released: Comprehensive Upgrades in Judgment, Honesty, and Autonomous Work Capabilities
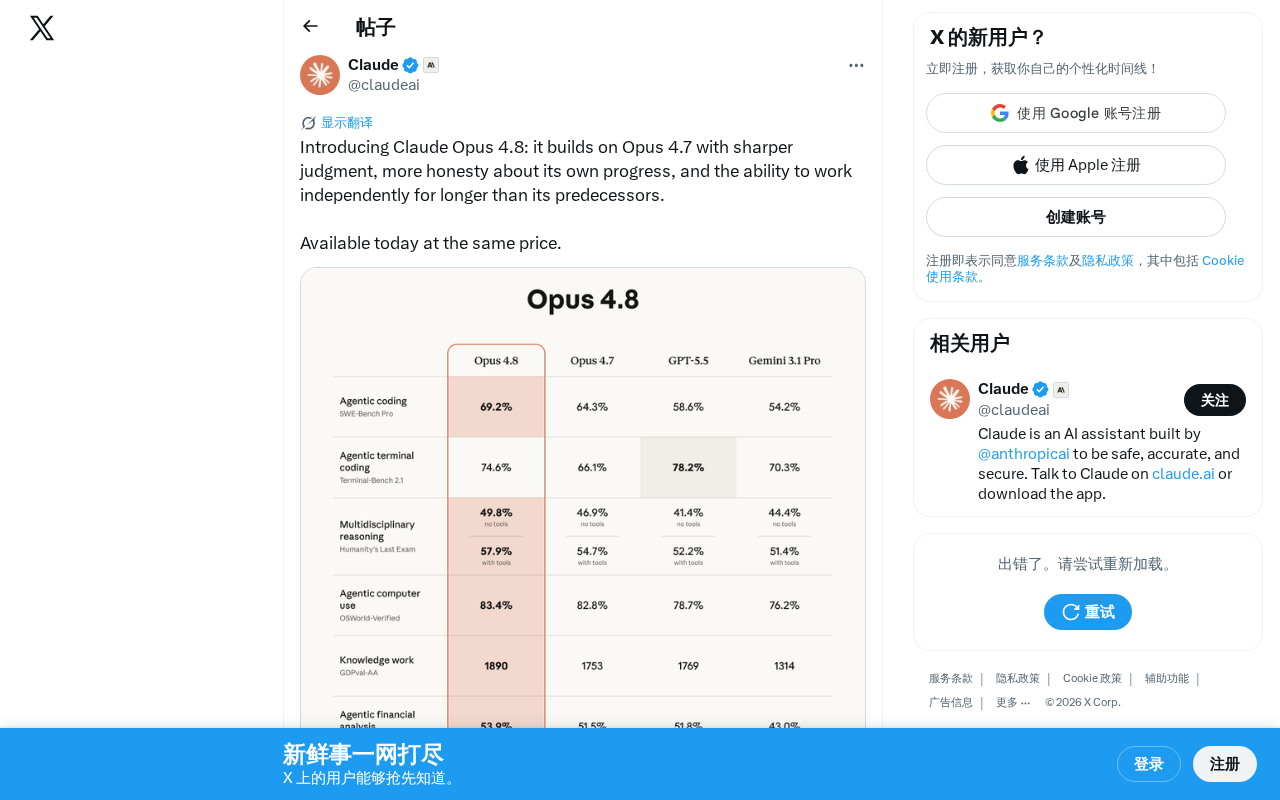
Claude Opus 4.8 upgrades judgment, honesty, and autonomous work duration at unchanged pricing.
Anthropic has released Claude Opus 4.8, featuring three core upgrades: sharper judgment for more precise decision-making in complex tasks, greater honesty about its own capability boundaries to reduce hallucinations, and longer independent work duration for AI Agent scenarios. The model maintains the same pricing as its predecessor, reflecting the industry trend of delivering stronger capabilities without price increases as inference efficiency improves.
Overview
Anthropic has officially released Claude Opus 4.8, the latest iterative upgrade following Opus 4.7. According to the official announcement, the new version features significant improvements in judgment, self-awareness honesty, and independent work duration, while maintaining the same pricing as its predecessor.
Anthropic was founded in 2021 by former OpenAI Research VP Dario Amodei and his sister Daniela Amodei. The company's core mission is to develop safe, controllable AI systems. Anthropic introduced the "Constitutional AI" training method, which enables models to self-correct based on a set of explicit principles rather than relying entirely on human annotation feedback. The company has raised over $7 billion in funding from investors including Google, Salesforce, and Amazon. Anthropic has consistently prioritized safety and honesty over raw performance in its product design, which explains why Opus 4.8 features "self-awareness honesty" as one of its core upgrade areas.
Three Core Upgrades in Claude Opus 4.8
Before diving into the specific upgrades, it's worth understanding Opus's position within Anthropic's model lineup. The Claude model family is organized into three tiers by capability, from highest to lowest: Opus, Sonnet, and Haiku, each corresponding to different use cases and pricing tiers. Opus is positioned for professional scenarios requiring the strongest reasoning capabilities and highest output quality, such as complex programming, deep research, and high-stakes decision support. The incremental version numbering from 4.7 to 4.8 reflects Anthropic's gradual versioning strategy, distinct from the major version jumps seen from Claude 3 to Claude 4.
Sharper Judgment
Claude Opus 4.8 features targeted optimizations in reasoning and judgment capabilities. "Sharper Judgment" means the model can make more precise decisions when facing complex, ambiguous, or trade-off-heavy tasks. This is particularly important for scenarios requiring deep thinking, such as debugging code, analyzing documents, and providing strategic recommendations.
On the technical level, improvements in judgment typically involve enhancements to the quality of the model's Chain of Thought reasoning. Chain of Thought refers to the intermediate reasoning steps the model unfolds before arriving at a final answer. Higher-quality reasoning chains mean the model can more systematically consider multiple dimensions of a problem, identify hidden assumptions, evaluate the pros and cons of different approaches, and make more reasonable trade-offs when confronted with conflicting information. This is fundamentally different from simple knowledge retrieval — it requires the model to possess "comprehensive assessment" capabilities similar to those of human experts.
Looking at Anthropic's recent product iteration cadence, the Opus series is evolving toward becoming a "reliable AI collaborator" rather than simply chasing higher benchmark scores. Enhanced judgment means the model is less likely to make errors in real-world applications, and its outputs are more trustworthy.
Greater Honesty About Its Own Capability Boundaries
This is a noteworthy feature of Claude Opus 4.8. An AI model's awareness of its own capability boundaries has long been an industry challenge — overconfidence leads to "hallucination" outputs, while excessive caution reduces practical utility. Opus 4.8 has made clear improvements in this area, enabling more accurate self-assessment of whether it truly understands a problem and whether it's capable of completing a task.
AI Hallucination refers to the phenomenon where large language models generate factually incorrect or entirely fabricated information with a highly confident tone. The root cause lies in the fact that language models are fundamentally based on statistical probability for text prediction, rather than truly "understanding" the veracity of information. Metacognition in the AI domain refers to a model's ability to perceive its own reasoning process and capability boundaries. Traditional models lack this self-assessment mechanism and often generate plausible-sounding answers even in areas of knowledge blindness. Anthropic uses training techniques to teach models to recognize their own uncertainty and express hesitation or refuse to answer when appropriate — this is considered one of the key pathways to improving AI reliability.
Notably, achieving this "Well-Calibrated Uncertainty" is technically extremely challenging. The model needs to learn during training to distinguish between three states: "I'm confident I know the answer," "I roughly know but am not entirely sure," and "I actually don't know." Current mainstream approaches in the industry include: training honest behavior through Reinforcement Learning from Human Feedback (RLHF), using adversarial evaluation to discover scenarios where models are overconfident, and self-constraining through honesty principles in the Constitutional AI framework. Opus 4.8's progress in this area suggests that Anthropic may have achieved new breakthroughs in training data strategy and reward model design.
This improvement in "metacognitive" capability reflects Anthropic's continued investment in AI safety and reliability. An AI that can honestly say "I'm not sure" is often more trustworthy than one that always provides seemingly confident answers.
Longer Independent Work Duration
Compared to its predecessor, Claude Opus 4.8 can maintain independent working states for longer periods. This improvement is directly tied to the AI Agent use cases that Anthropic has been actively promoting.
An AI Agent is an AI system capable of autonomously perceiving its environment, formulating plans, executing multi-step tasks, and adjusting behavior based on feedback. Unlike traditional single-turn conversational AI, Agents need capabilities such as task decomposition, tool invocation, error recovery, and long-term memory. Since 2024, AI Agents have become one of the hottest directions in the industry, with major players like OpenAI, Google, and Microsoft all investing heavily. One of the core challenges for Agents is "long-horizon reliability" — maintaining decision quality without degradation or goal deviation during extended autonomous operation. Claude Opus 4.8's emphasis on "longer independent work duration" directly addresses this pain point.
From a technical perspective, improving long-duration independent work capability involves optimization across multiple dimensions. First is effective utilization of the context window — as task execution time increases, accumulated contextual information grows, and the model needs to efficiently manage and retrieve key information within a limited context window. Second is mitigating "Goal Drift" — in long-sequence tasks, the model may gradually deviate from the original objective, getting caught in irrelevant subtasks or repetitive loops. Additionally, there's the control of error accumulation — small deviations in each decision step can be amplified across a long chain, causing final results to severely deviate from expectations. Opus 4.8's improvements in these areas make it more suitable as a reliable automation work engine.
Longer independent work capability means:
- Less frequent manual intervention needed when handling large projects
- Higher completion rates for complex multi-step tasks
- More stable performance in automated workflows
This aligns closely with the broader industry trend of transitioning from "conversational AI" to "task-execution AI."
Claude Opus 4.8 Pricing and Availability
Interestingly, Anthropic explicitly stated that Opus 4.8 maintains the same price as its predecessor (Available today at the same price). This "performance upgrade, price unchanged" strategy is highly competitive in the current AI landscape, lowering migration costs and decision barriers for users.
For developers and enterprise users already using the Claude Opus series, they can seamlessly switch to the new version without adjusting budgets. This pricing strategy also reflects an important trend in the AI industry: as training and inference efficiency continue to improve, model providers can deliver stronger capabilities without raising prices. The competitive focus is shifting from "who's cheaper" to "who's stronger at the same price."
Specifically, improvements in inference efficiency come from several areas: model architecture optimizations (such as more efficient attention mechanisms and sparsification techniques), inference infrastructure improvements (such as better GPU utilization and batching strategies), and advances in model compression techniques like distillation and quantization. These technological dividends enable model providers to continuously reduce per-unit inference costs, creating room to offer stronger models while maintaining stable pricing. For enterprise customers, this means the ROI on their AI investments is naturally growing — they can achieve better results without additional spending.
Industry Observation: Large Model Iteration Enters a Fast-Paced Era
Anthropic's rapid iteration cadence (from 4.7 to 4.8) indicates that large model updates are shifting from "major version jumps" to "continuous small, fast steps." The advantages of this approach include:
- Smoother user adaptation: Each upgrade is moderate in scope, avoiding drastic changes to usage habits
- More controllable risk: Small iterations make it easier to quickly identify and fix issues
- Shorter feedback loops: Enables more timely responses to user needs and market changes
This iteration model borrows from the "Continuous Delivery" philosophy in software engineering, closely mirroring the evolution from waterfall development to agile development in the traditional software industry. In the AI model domain, this strategy offers an additional advantage: it allows providers to target specific issues in each minor version update (such as this release's focus on judgment and honesty) rather than attempting to solve all problems simultaneously in a single major release, thereby reducing the risk of introducing new issues. At the same time, rapid iteration places higher demands on model evaluation systems — providers need to establish comprehensive automated evaluation pipelines to ensure that each update doesn't cause regression in other capabilities while improving certain ones (the so-called "capability regression" problem).
From a competitive standpoint, the release of Claude Opus 4.8 further solidifies Anthropic's position in the high-end AI model market, particularly in enterprise-grade AI Agent application scenarios that require high reliability and extended autonomous operation. As AI Agents become an industry focal point, the Opus series' continuous strengthening of autonomous work capabilities is building a differentiated competitive advantage for Anthropic.
Key Takeaways
Related articles
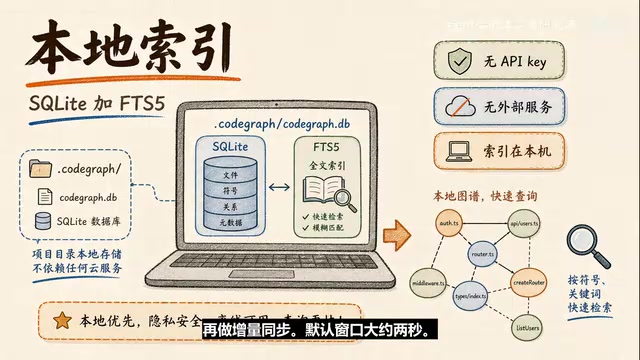
CodeGraph: Give Your Coding Agent a Code Map, Save 47% Tokens
CodeGraph is an open-source project with ~40K GitHub stars that uses Tree-sitter to build a local queryable code map, helping Claude Code and Cursor reduce 47% token usage and 58% tool calls.
AI Finishes Writing Code, Automatically Strikes a Gong to Alert You: Open-Source Physical Feedback Tool DAgent
A developer built a physical feedback device with chopsticks and a small gong that auto-strikes when AI finishes coding. Now open-sourced as DAgent, it also simulates IPO bell-ringing when creating new files.

Level Up Claude Code: Building an Enhanced Plan Mode with Grill Me
Learn how to install and use the Grill Me Skill for Claude Code, replacing AI guesswork with structured questioning to clarify requirements before generating execution plans.