110K PRs Tested: Which of 5 AI Coding Agents Is Most Reliable?

110K PR study reveals AI coding agents' code quality lags humans, with only ~50% one-year survival rate
A large-scale MSR 2026 empirical study covering 110K PRs and 5 mainstream coding agents shows AI coding agents significantly trail senior human developers in PR merge rates and long-term code survival. AI code has a 3-month churn rate 40% higher than human code, a one-year survival rate of only ~50%, and core module survival as low as 30%. The study recommends teams establish differentiated review standards for AI code, assign non-core tasks to AI while keeping core logic human-led, and implement long-term quality monitoring.
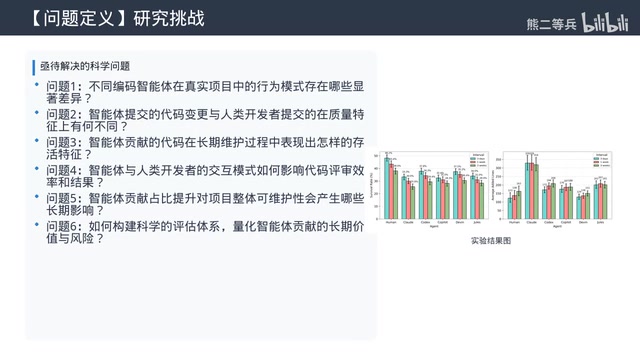
Research Background: AI Coding Agents Have Penetrated Real Development Workflows
From auto-completion to independently submitting PRs, autonomous coding agents have truly embedded themselves in the core software development workflow. Tools like GitHub Copilot, Devin, and Claude Code are contributing an ever-growing share of code in open-source communities, but a critical question remains unanswered: How good is the quality of these agents' contributions? How do they differ from human developers?
Notably, autonomous coding agents have evolved through three distinct phases: The first phase was the "code completion" mode represented by early versions of GitHub Copilot, providing line-level or function-level completions based on the Codex model. The second phase was "conversational programming," where developers described requirements in natural language and models generated complete code snippets. The third phase is the current "autonomous agent" mode, where systems can independently plan tasks, invoke tools (such as terminals, browsers, code search), execute multi-step operations, and submit complete PRs. Devin is a quintessential representative of this third phase, with its core architecture comprising a task planner, tool-calling module, and self-reflection mechanism, capable of independently completing the entire workflow from requirement understanding to code submission in a sandboxed environment. This capability leap means evaluation frameworks must also upgrade from "code snippet quality" to "full software engineering lifecycle contribution quality."
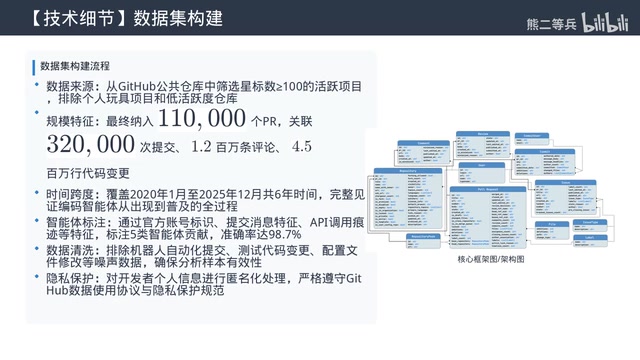
A latest study from MSR 2026 provides the most systematic answer to date. The team led by Rezvan Mihai Popescu collected 110,000 open-source PR data points, covering 5 mainstream coding agents, not only comparing current contribution differences horizontally but also tracking long-term code evolution longitudinally. The conclusions challenge many common assumptions.
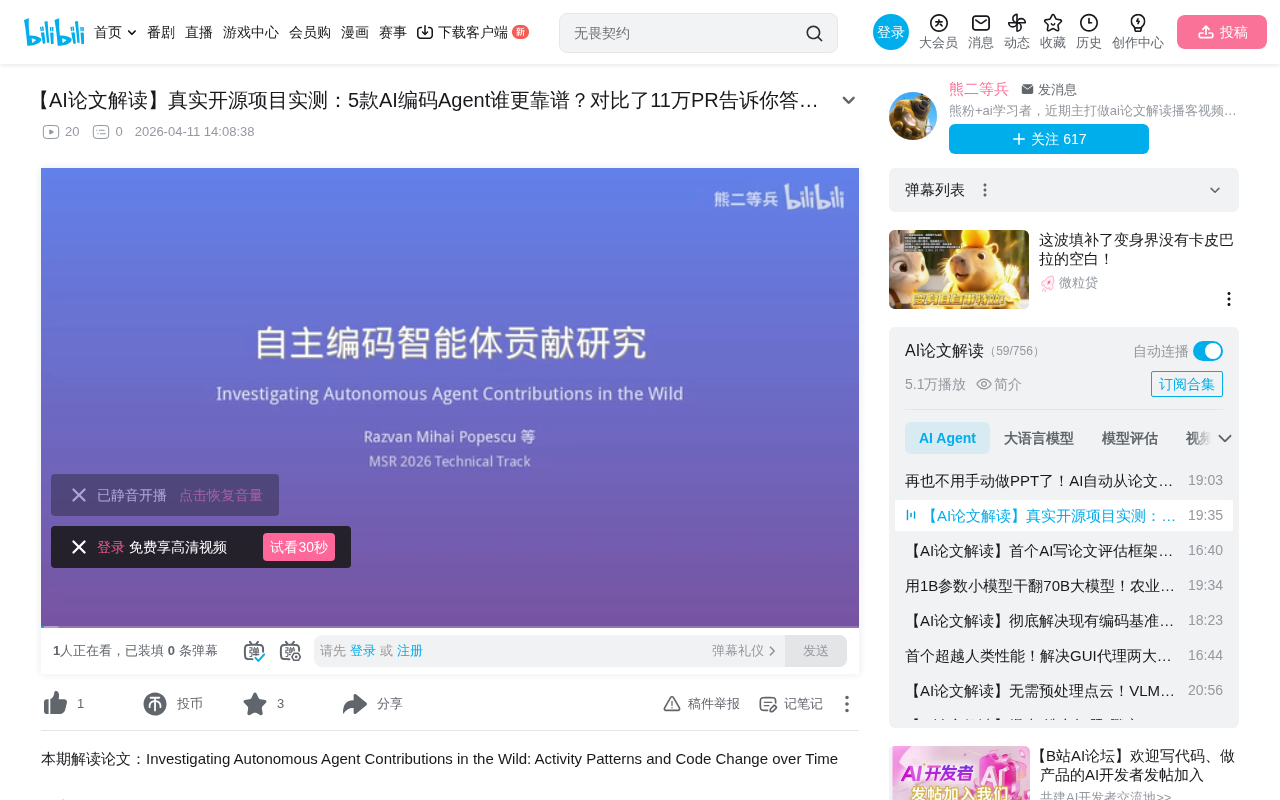
Research Design: A Rigorous Six-Layer Progressive Framework
The experimental design of this study is textbook-level, with the entire framework progressing through six layers:
- Data Collection Layer: Crawling PR submission records, comments, reviews, Issues, and file change data from major open-source platforms
- Agent Identification Layer: Identifying AI vs. human submissions through multiple dimensions including commit messages, account characteristics, and content features
- Horizontal Comparison Layer: Conducting statistical tests comparing various metrics across different agents and human developers
- Longitudinal Analysis Layer: Tracking code survival and churn rates at 1 month, 3 months, 6 months, and 1 year
- Statistical Validation Layer: Controlling for confounding variables such as project activity level and developer experience
- Conclusion Output Layer: Drawing conclusions based on results after strict variable control
The most commendable aspect is how well confounding variables were controlled. The control group consisted of senior developers with years of open-source contribution experience, not beginners, avoiding the common pitfall of "comparing AI against novices."
5 AI Coding Agents and Evaluation Dimensions
The 5 coding agents compared include: OpenAI Codex/CL, Claude Code, GitHub Copilot, Google Gemini, and Devin. The evaluation dimensions cover six core metrics: PR merge rate, change size, file type preference, developer interaction signals, short-term churn rate (3 months), and long-term survival rate (1 year).
Horizontal Comparison: Significant Differences in Merge Rates and Behavioral Patterns
PR Merge Rate: Copilot Leads, Devin Trails
Pull Request (PR) merge rate is the core proxy metric for measuring code contribution quality in open-source communities. A PR must pass through multiple gates from submission to merge—code review, CI/CD automated testing, and manual maintainer review—so merge rate naturally integrates signals from multiple dimensions including code correctness, style consistency, and requirement alignment. This study mitigated bias from differing merge standards across projects by controlling for project activity level.
Merge rates differ significantly across agents. GitHub Copilot has the highest merge rate, approximately 60%, essentially on par with senior human developers; while Devin's merge rate is below 40%. This relates to their design positioning—Copilot is fundamentally an assistive tool where humans write the main code and it supplements portions. Human developers have already filtered and modified Copilot-generated code before submission, effectively completing a round of manual filtering before the PR is created, hence the higher merge rate. Devin is designed to autonomously complete entire tasks, resulting in higher PR complexity and naturally lower merge rates.
Change Size: AI Prefers Small Modifications
The average change size of agent-submitted PRs is notably smaller than human submissions, mostly consisting of small changes of a few dozen lines. Human developer PRs frequently contain feature submissions of hundreds or even thousands of lines.
File Type Preference: AI Excels at "Peripheral" Work
Agents generally tend to modify documentation, configuration files, test cases, and other non-core code files, while human developers more frequently modify core business logic and architecture-related code.
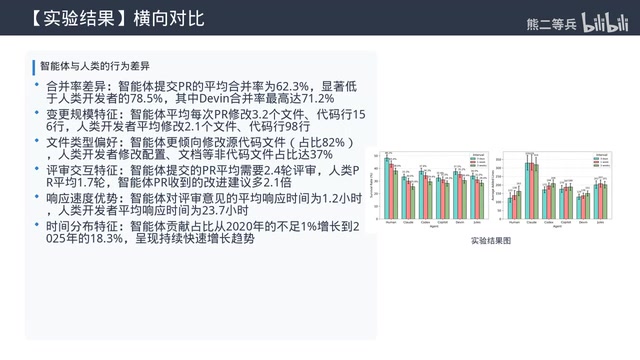
Review Interaction: AI Code Requires More Scrutiny
Agent-submitted PRs receive approximately 30% more comments and review feedback on average than human PRs, indicating that human reviewers are more cautious when examining AI code. One reason is that agent-written code tends to have lower consistency with the project's existing style.
Another noteworthy finding: Agent PRs have significantly lower Issue resolution rates than human PRs. Although PRs may pass review, they don't fully resolve the corresponding requirements, necessitating subsequent human supplementary modifications.
Longitudinal Tracking: Long-Term Maintainability of AI Code Is Concerning
If horizontal comparison reveals current differences, the longitudinal tracking results are even more alarming.
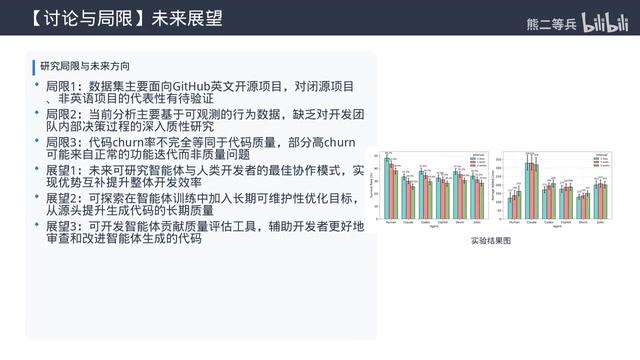
Short-Term Churn Rate: AI Code Is 40% Higher
Within 3 months after PR merge, the churn rate (proportion modified, refactored, or deleted) of agent-generated code is on average 40% higher than human code. Specific figures: human code has a 3-month churn rate of approximately 25%, while agents average 35%, with some exceeding 40%.
Long-Term Survival Rate: Half of AI Code Doesn't Survive a Year
Code Survival Rate is a classic metric in software evolution research, typically measured through Git blame analysis—by comparing code attribution at different time points, it calculates the proportion of code from a given commit that remains in subsequent versions. Low survival rates mean code is frequently refactored or deleted, which directly corresponds to Technical Debt accumulation in engineering practice. The concept of technical debt was introduced by Ward Cunningham in 1992, described as "the implicit cost incurred by sacrificing code quality for short-term delivery speed."
One year after submission, approximately 70% of code written by senior human developers remains in the project, while agent-generated code has an average survival rate of only around 50%, with the lowest falling below 40%. If the hidden costs of subsequent maintenance and refactoring are factored into ROI calculations, the actual benefits of AI coding tools shrink dramatically—this has direct financial implications for enterprises formulating AI tool procurement and usage strategies.
The more critical finding: The more central the module, the lower the agent's survival rate. In core business logic code, human one-year survival rates reach 80%, while agents manage only around 30%. Conversely, for documentation, configuration files, and other non-core components, agent survival rates are comparable to humans.
This means: using AI to write code may save a few days initially, but the subsequent time spent on refactoring and bug fixes can be even greater—the total cost may not be worthwhile.
Root Causes: Why Does AI Code "Not Last"?
The research team identified six core reasons:
- Limited Context Understanding: While mainstream LLM context windows have expanded from the early 4K tokens to 128K or even 200K tokens, large production-grade codebases often far exceed these limits. The deeper challenge is that code understanding involves not just text comprehension but also structural knowledge like Call Graphs, Data Flow Graphs, and module dependency relationships—information that cannot simply be "stuffed into" a context window. Core modules are often deeply coupled with the entire system's historical evolution, and this "tacit knowledge" cannot be fully conveyed to models through current context mechanisms.
- Training Objective Misalignment: Training objectives emphasize "writing correct code for the present" rather than long-term maintainability and extensibility
- Hidden Errors Are Hard to Detect: AI code sometimes contains subtle bugs that current tests can't catch, only manifesting after running in production for some time
- Lack of Domain Knowledge: Industry-specific business logic and unwritten rules lack sufficient training data for AI
- Insufficient Creativity: In scenarios requiring innovative design (such as new architectural approaches), AI falls short of human developers
- Communication Gaps: Unlike humans, AI cannot discuss requirement details with product managers and colleagues before coding—it can only rely on written documentation
Practical Implications: How to Use AI Coding Tools Scientifically
Based on this research, development teams can optimize their AI coding tool usage strategies across three dimensions:
Establish Differentiated Code Review Standards
Don't review AI code using exactly the same standards as human code. For AI-written core module code, conduct more rigorous checks focusing on logical correctness, architectural compatibility, and long-term maintainability.
Allocate Tasks Based on Each Tool's Strengths
Assign tasks that AI excels at and where churn has minimal impact—such as documentation updates, writing test cases, and modifying configuration files—to AI. Core business logic and architectural design should remain with human developers for maximum efficiency and reliability. While current technologies like RAG (Retrieval-Augmented Generation) and Code Graph Embedding extend AI's code comprehension capabilities to some degree, they still have significant shortcomings in capturing cross-file implicit dependencies and historical design decisions. Therefore, human leadership on core modules remains the optimal strategy at this stage.
Establish Long-Term Monitoring Mechanisms for AI Code
Don't just check whether there are issues at submission time—continuously track the churn rate and bug rate of AI-generated code. If you discover that maintenance costs actually increase after using AI for certain types of tasks, adjust your strategy promptly to avoid accumulating technical debt for short-term efficiency gains.
Conclusion
The greatest value of this research lies in not stopping at the surface-level question of "can AI write code," but extending the perspective to the complete software engineering lifecycle. Empirical data from 110,000 PRs tells us: AI is an excellent assistive tool, but long-term quality of core code still requires human oversight. As AI coding tools become increasingly prevalent, rationally understanding their strengths and limitations is the only way to truly maximize their benefits.
Key Takeaways
- The study covers 110K PR data points and 5 mainstream coding agents, making it one of the largest empirical studies in this area to date
- GitHub Copilot has the highest merge rate (~60%), on par with senior human developers; Devin's merge rate is below 40%
- AI-generated code has a 3-month churn rate 40% higher than human code, a one-year survival rate of only ~50%, and core module survival rates as low as 30%
- Agents excel at modifying documentation, configuration files, and other non-core code; core business logic still requires human developer leadership
- Teams should establish differentiated review standards for AI code, allocate tasks based on strengths, and build long-term code quality monitoring mechanisms
Related articles
New Species Discovered in New York's C…
New Species Discovered in New York's Central Park? Inside the Urban Insect Hunting Project
Scientists set up insect traps in NYC's Central Park and Prospect Park to discover unknown species. With 90% of Earth's species still unnamed, urban biodiversity research is becoming a new trend in ecology.
The Full Story of the Higgs Boson Disc…
The Full Story of the Higgs Boson Discovery: An Insider's Account of the 'God Particle'
A Fermilab physicist's insider account of the Higgs boson discovery: the transatlantic race with CERN, behind-the-scenes details of the 2012 announcement, 14 years of verification, and the true origin of the 'God Particle' name.
 Research
ResearchSciMDR: How a 7B Small Model Rivals GPT-5 in Scientific Reasoning
Yale and other institutions introduce SciMDR, a two-stage data synthesis pipeline enabling a 7B model to match GPT-5 level performance in scientific literature comprehension.