5 Models Coding Showdown: Claude, GPT, DeepSeek, M3 — Who's the Best Engineering Tool?
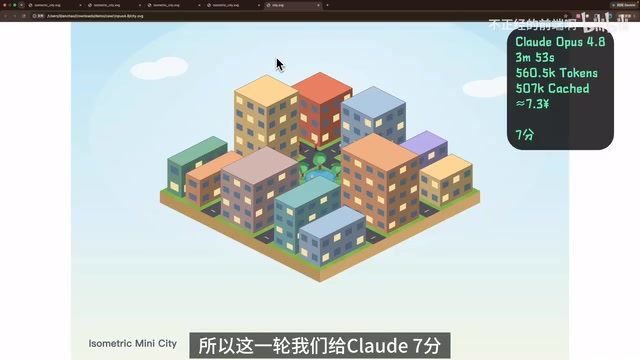
Real-world coding tests pit Claude, GPT, DeepSeek, M3, and Mimo across four engineering challenges.
A Bilibili creator tested five frontier models — Claude Opus 4.8, GPT 5.5, MiniMax M3, DeepSeek V4 Pro, and Mimo 2.5 Pro — across four coding challenges: SVG city drawing, 3D game generation, elevator dispatch simulation, and real production bug fixing. Claude led in stability and engineering completeness, M3 impressed with creativity and long-context efficiency via its MSA architecture, DeepSeek showed strong cost-effectiveness, GPT had a surprising total failure, and Mimo consistently underperformed.
Introduction: Beyond Benchmarks, Real-World Results Matter
With the release of MiniMax M3, yet another domestic model claiming "Coding SOTA" has entered the spotlight. The official marketing around its MSA architecture and Agent engineering optimizations sounds enticing, but the reality is — trust in benchmarks is at an all-time low. Today's leaderboard champion gets replaced tomorrow, and when it comes to actual work, whether a model can get things done often has little to do with benchmark scores.
Bilibili creator "不正经的前端" (Unconventional Frontend) designed four progressively challenging coding scenarios to conduct a hardcore head-to-head evaluation of Claude Opus 4.8, GPT 5.5, MiniMax M3, Mimo 2.5 Pro, and DeepSeek V4 Pro. All tests were conducted uniformly in the Claude Code environment, with scoring based solely on final completion quality. Price, speed, and token consumption are provided for reference only.
Case 1: Pure SVG Isometric Micro-City
The first task required models to draw an isometric micro-city using pure SVG code, including roads, buildings, parks, trees, vehicles, and pedestrians — no HTML, CSS, or JavaScript allowed. While this appears to be a drawing task, it actually tests spatial understanding, structural organization, and long code output capability.
Isometric Projection is an axonometric projection method with no perspective scaling, where the three coordinate axes are separated by 120-degree angles. This projection is widely used in classic games (like SimCity and Monument Valley) because it clearly expresses 3D spatial relationships on a 2D plane while avoiding the distortion caused by true perspective. Implementing isometric views in pure SVG means the model must manually calculate coordinate offsets and stacking order (z-index) for every element without 3D engine assistance — an extreme test of spatial reasoning ability.
Model performance varied significantly:
- DeepSeek V4 Pro (4/10): Core elements present, city structure recognizable, but suffered from clipping issues, proportion imbalances, and confused spatial relationships. Basic task completion.
- Mimo 2.5 Pro (2/10): Perspective relationships were chaotic, shadow handling was missing, colors were acceptable but lacked cohesion — didn't look like a complete city.
- MiniMax M3 (6/10): Richest in detail, proactively built atmospheric elements like sky and light halos, but clipping and layout chaos were also prominent — a typical "high ceiling, high risk" performer.
- GPT 5.5 (5/10): Decent number of elements but building layout felt random, shadow colors were uncoordinated. Looks okay from afar, problems emerge up close.
- Claude Opus 4.8 (7/10): Strongest overall design capability. The relationships between roads, buildings, and greenery felt natural, with clear layering and virtually no structural errors. Less detailed than M3, but more like a planned finished product.
Round Conclusion: M3 is the creative player, Claude is the engineering player. In code generation tasks, error rate matters more than creativity — Claude wins.
Case 2: Complete 3D Endless Runner Game Generation
The second task asked models to generate a complete 3D endless runner game, involving scene construction, render loops, physics logic, collision detection, and object lifecycle management — collectively known as the "crash zone" for large language models.
Implementing a 3D endless runner involves multiple tightly coupled technical modules: Infinite Scrolling requires dynamically generating and recycling terrain chunks as the player advances to create the illusion of an endless track; Collision Detection typically uses AABB bounding boxes or raycasting to determine character-obstacle interactions; object lifecycle management requires timely destruction of off-screen objects to prevent memory leaks. The render loop relies on requestAnimationFrame for per-frame updates, while physics logic must simulate gravity, jump parabolas, and landing detection. Any single module failing will cause the game to malfunction, hence the "crash zone" reputation.
- DeepSeek V4 Pro (7/10): Exceeded expectations. Scene looping, collision detection, and character controls all worked, plus camera following and sound effects — strong game feel.
- Mimo 2.5 Pro (4/10): Collision detection worked, but left/right controls were inverted. Most critically, there was no main runner object, severely impacting the experience.
- MiniMax M3 (7/10): Rich in detail as always, added running animations, coin particle effects, and even designed special ducking-through sections. But lacked camera following, which felt awkward in comparison.
- GPT 5.5 (0/10): Complete failure — both attempts produced blank screens, cause unknown.
- Claude Opus 4.8 (6/10): Overall framework was sound, but left/right controls were inverted, and the spacebar jump would refresh the game (up arrow jump worked fine) — a bug that hurt the experience.
Round Conclusion: DeepSeek and M3 tied for the lead — the former earned points for sound effects and camera following, the latter for detail and creativity. GPT 5.5 unexpectedly submitted a blank paper.
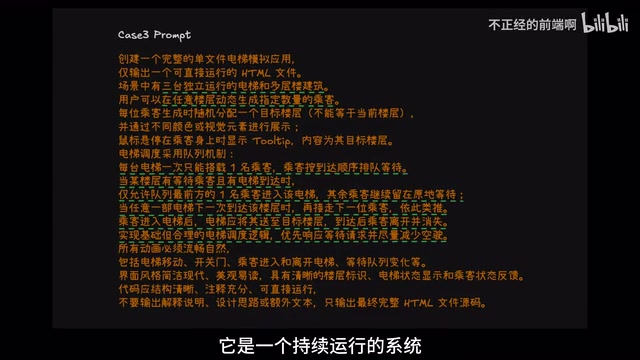
Case 3: Elevator Dispatch Simulator
The third task required generating a dispatch simulator with three independent elevators, supporting dynamic passenger generation and real-time scheduling. The core test was state management and scheduling algorithms — which floor is the elevator on, should it stop, who picks up the new passenger, should it take someone along the way? These logic chains are extremely bug-prone.
Elevator scheduling is a classic teaching case in operating systems and distributed systems. Common scheduling strategies include FCFS (First Come First Served), SCAN (the elevator algorithm, similar to disk seek — the elevator runs in one direction to the end before reversing), and LOOK (improved SCAN that reverses at the farthest request floor rather than always going to the top/bottom). Multi-elevator scenarios also require solving "resource contention" — multiple elevators simultaneously responding to the same request, causing resource waste. This is essentially a consistency problem in distributed systems, requiring lock mechanisms, state synchronization protocols, or a centralized dispatcher to coordinate multiple elevators' behavior, ensuring each passenger request is handled by only one elevator.
- DeepSeek V4 Pro (7/10): Scheduling logic was essentially correct. The full flow of passenger queuing, pickup, and delivery worked. UI wasn't stunning but core logic was sound.
- Mimo 2.5 Pro (2/10): Scheduling algorithm was wrong, UI interactions had issues — both logic and presentation failed.
- MiniMax M3 (6/10): Scheduling algorithm was basically correct, but had a resource contention problem — when only one passenger remained on a floor, two elevators would respond simultaneously; after one picked up the passenger, the other still traveled there for nothing. This is a classic Race Condition, indicating unclean scheduling state synchronization and missing mutual exclusion controls on shared state.
- GPT 5.5 (~5-6/10): Scheduling logic was fine, but passengers would fly in from the top-left corner of the page when entering the elevator, and the button area blocked the elevator shaft.
- Claude Opus 4.8 (7/10): Both scheduling logic and UI had no obvious issues — consistently stable.
Round Conclusion: DeepSeek and Claude achieved the highest completion quality. M3 and GPT followed closely but each had flaws. Mimo underperformed again.
Case 4: Real Engineering Project Bug Fix (Long-Context Task)
The first three cases were essentially demos with clear boundaries and limited code scale. The final case went straight to a real project — a large model gateway built on NewAPI, where the auto-group (intelligent circuit breaking) feature had production bugs: sometimes the system would return errors even when available groups remained; sometimes it couldn't find the target group to switch to.
The "intelligent circuit breaking" mentioned here is a critical fault-tolerance mechanism in API gateways. The Circuit Breaker Pattern borrows from electrical engineering: when a downstream service's error rate exceeds a threshold, the breaker "trips," and subsequent requests are no longer sent to that service but instead fail fast or switch to a backup channel. In the large model gateway scenario, this means when a model provider's API experiences failures (timeouts, rate limiting, service unavailability), the system should automatically route requests to other available providers. The difficulty lies in the timeliness of state judgment — circuit breakers typically have three states: Closed (normal pass-through), Open (block all), and Half-Open (tentatively allow a few requests to detect recovery). Transitions between these states require precise timeout control and health checks, and coupling in legacy code often makes state transitions unpredictable.
This task involved configuration reading, route selection, circuit breaking logic, error handling, model scheduling, and cache state — all intertwined with legacy design decisions. Models needed to continuously read files, analyze call relationships, and trace logic chains, causing context length to rapidly expand — precisely the core scenario where MiniMax promotes its MSA architecture advantage.
Due to the extreme time requirements, the creator only selected three models for comparison:
Mimo 2.5 Pro (4/10)
- ~1.5 hours, consumed 6.8M tokens (6.3M cache hits), cost ~¥10
- Found some issues, code modifications had no obvious errors, but the fix was incomplete, missing critical paths
- Felt more like making local patches on existing logic without addressing the root cause
MiniMax M3 (6/10)
- 56 minutes, consumed 16.6M tokens (16.1M cache hits), cost ~¥7
- Explicitly identified this as an architecture-level design issue (consistent with the creator's judgment), but chose a conservative approach — reducing exception probability through compensation logic and fallback mechanisms
- Reasoning: the system is already running in production, directly modifying the architecture carries too much risk. Sound thinking, but the problem wasn't thoroughly resolved
MiniMax M3's MSA (Multi-head Shared Attention) architecture is an improvement on the standard Transformer attention mechanism. In traditional Multi-Head Attention (MHA), each attention head independently maintains Query, Key, and Value matrices, with memory overhead growing quadratically with context length — a severe performance bottleneck for ultra-long contexts. MSA shares partial KV caches across multiple attention heads (similar in spirit to GQA/MQA but with differences), significantly reducing memory usage and computational cost during long-sequence inference while maintaining model expressiveness. This explains why M3's speed isn't outstanding in short tasks, but in Case 4 — where context rapidly expands to millions of tokens — it actually demonstrates efficiency advantages. The architectural dividend only truly materializes in long-tail scenarios.
Claude Opus 4.8 (8/10)
- 20 minutes, consumed 13.9M tokens (13.7M cache hits), cost ~¥45
- Also identified it as an architecture problem, but didn't make the choice for the user — instead provided multiple refactoring options with benefit and risk analysis
- The creator chose the recommended refactoring plan, which from a code review perspective is currently the most complete solution
Key Findings from the Long-Context Task
A noteworthy detail: in the first three simple cases, M3 was slightly slower than Mimo; but in this complex long-context task, M3 was actually much faster than Mimo (56 minutes vs. 90 minutes) with better results. Could this be the MSA architecture's advantage in long-context scenarios? While it can't be rigorously verified, at least from practical experience, M3 clearly demonstrated significant advantages in long-context multi-turn analysis scenarios.
Another dimension worth noting is the relationship between token consumption and cost. The Case 4 data reveals an important cost structure: M3 consumed 16.6M tokens with 16.1M cache hits (97% hit rate), costing only ¥7; while Claude consumed 13.9M tokens with 13.7M cache hits (98.6% hit rate), costing ¥45. This difference stems from two factors: first, pricing strategies differ across providers, with Claude's unit price significantly higher than domestic models; second, cached tokens are typically billed at far below the first-computation price (usually 1/10 to 1/4 of the original), making high cache hit rates crucial for controlling long-task costs. This is also why Prompt Caching technology — caching repeatedly occurring context prefixes to avoid redundant computation — has become one of the core competitive advantages of current LLM API services.
Overall Assessment and Industry Observations
| Model | Case 1 SVG | Case 2 3D Game | Case 3 Elevator | Case 4 Engineering Fix |
|---|---|---|---|---|
| Claude Opus 4.8 | 7 | 6 | 7 | 8 |
| DeepSeek V4 Pro | 4 | 7 | 7 | - |
| MiniMax M3 | 6 | 7 | 6 | 6 |
| GPT 5.5 | 5 | 0 | ~5 | - |
| Mimo 2.5 Pro | 2 | 4 | 2 | 4 |
Claude Opus 4.8 remains the strongest engineering-oriented model currently available, leading comprehensively in stability and completion quality — especially dominant in real engineering tasks — but also the most expensive.
MiniMax M3 was the most distinctive domestic model in this evaluation — rich in creativity, strong in detail, and demonstrating performance beyond peer domestic models in long-context tasks. The MSA architecture's efficiency advantage in long-context scenarios deserves continued attention.
DeepSeek V4 Pro performed solidly in demo-level tasks with outstanding cost-effectiveness, though unfortunately didn't participate in the final engineering-level test.
As the creator reflected: two years ago, discussions about domestic models centered on "can it write code at all?" and "is it only good for chatting?" Today, the conversation has shifted to "which is more stable," "which is better for Agents," and "which performs better in long contexts." When the discussion evolves from "can it be used" to "which is better to use," it signals that the entire industry has entered a new phase. Domestic models still trail Claude, but they've genuinely begun entering developers' workflows — and that fact alone may be more noteworthy than any single benchmark championship.
Related articles
Building a Cold Chain Logistics Optimization Research Project with Codex: A Complete Workflow from Scratch to PDF Paper
Learn how to use OpenAI Codex to build a complete cold chain logistics optimization research project from scratch, including simulated annealing implementation, experiments, figures, and LaTeX paper compilation.
Codex Beginner's Practical Guide: Master Core AI Programming Skills in One Weekend
OpenAI Codex beginner's practical guide covering environment setup, code generation, bug fixing, and project refactoring. Includes efficient learning tips and Prompt techniques for fast AI programming mastery.
AI Agent Systematic Learning Path: From Zero to Independent Development
A systematic AI Agent learning path covering core principles, Prompt engineering, RAG, multi-Agent collaboration, and hands-on projects for beginners.