9 Failure Modes and Best Practices Guide for the GrillMe Skill

A guide to the 9 most common GrillMe failure modes and best practices for effective AI-assisted engineering planning.
This guide analyzes 9 common failure modes when using GrillMe and GrillWithDocs skills for AI-assisted engineering planning. It covers critical topics including question fidelity levels, scope control, balancing proactiveness, preserving decision context, choosing the right model, and running parallel sessions to boost throughput—helping developers get the most out of Socratic-style AI questioning workflows.
Introduction: GrillMe Is a Conversation, Not an Interview
GrillMe and GrillWithDocs, as alternatives to PlanMode in AI Agents, have been widely adopted by developers around the world. GrillMe and GrillWithDocs are custom modes within the Roo Code AI coding assistant ecosystem, created by community developers and widely shared. Unlike PlanMode, which has the AI generate an implementation plan before executing, GrillMe uses a Socratic questioning approach—continuously asking the developer questions to force them to clarify requirements, edge cases, and technical decisions. It's essentially a structured requirements clarification process. GrillWithDocs builds on this by adding document context, allowing the AI to ask more targeted questions based on the existing codebase and documentation.
However, many users have encountered various issues in practice—some report being asked 200 consecutive questions by the AI, creating enormous psychological pressure.
The core philosophy behind these skills is: the AI will relentlessly question you until both sides reach consensus on a topic. But the key is that it depends on the person answering the questions. In other words, when using GrillMe, you need to be good at planning, understanding scope, knowing which questions should be asked, and the level of fidelity required for answers.
These skills are designed to help you as an engineer, not to replace your role as one. Here are the 9 most common failure modes when using these skills, along with their solutions.
Understanding Question Fidelity Levels
The Difference Between High-Fidelity and Low-Fidelity Questions
Borrowing from Ryan Singer's concept in Shape Up, questions can be divided into two categories. Shape Up is a product development methodology incubated within Basecamp (now 37signals), published as a free ebook in 2019. The core idea is to perform "Shaping" before a project kicks off—defining the solution outline at an abstract level rather than jumping straight into high-fidelity wireframes or detailed specifications. Singer's concept of "fidelity" emphasizes that different stages call for different levels of precision: rough sketches and written descriptions suffice during the low-fidelity stage, while interactive prototypes or actual code are needed to validate assumptions during the high-fidelity stage.
-
High-fidelity questions: Questions that can only be answered by zooming into the details. For example, "What does this interface actually feel like in use?" or "Should the form fields be split across multiple pages or combined into one large form?" These questions can only be truly answered through high-fidelity prototypes or actual implementation.
-
Low-fidelity questions: Questions that don't require a high-fidelity prototype to answer. For example, "Which URL should this feature live at?" can be resolved with a simple Q&A exchange.
Failure Mode 1: Trying to Answer High-Fidelity Questions During a Grilling Session
The first and most common failure mode is attempting to answer questions during a Grilling session that inherently require higher fidelity to clarify. Some questions are well-suited for "grilling" (they can be answered in conversation), while others simply cannot be resolved through dialogue.

When you encounter a question that can't be clarified through Grilling, the correct approach is to use the Handoff skill to transfer the conversation to a prototyping session. The Handoff skill is a coordination mechanism in AI Agent workflows that packages the current session's context, decisions made, and unresolved questions and passes them to another specialized session or mode—similar to a work handoff document in software teams. It preserves the complete decision chain and reasoning process, preventing information loss during mode switches. In the prototyping session, you explore the question at higher fidelity, then bring what you've learned back to the original Grilling session to continue with questions that are appropriate for conversational inquiry.
Scope Control Is the Key to GrillMe Success
Failure Mode 2: Grilling Scope Is Too Large
If the scope of what you're grilling is too large, you'll run into two problems:
-
Hidden high-fidelity questions: The larger the scope, the more likely you are to hit questions that are difficult to answer without actually seeing the full picture. It's always easier to build on an existing foundation—you know it works and it's already in good shape. Rather than trying to plan endlessly into the future, take it step by step.
-
Context window limitations: If the scope is too broad, you'll eventually hit the model's "Dumb Zone." The context window is the maximum number of tokens a large language model can process at once. Although current frontier models (such as Claude, GPT-4, Gemini) claim to support 128K or even 200K tokens, research shows that model performance is not uniformly distributed across the entire window. Multiple "Needle in a Haystack" tests have found that when context fills beyond approximately 60-70% capacity, the model's ability to retrieve and reason about information in the middle positions drops significantly—a phenomenon known as "Lost in the Middle." Around 120K tokens is the empirical threshold where most frontier models enter the performance degradation zone. Even though models can theoretically handle longer inputs, their effective reasoning ability noticeably declines beyond this point, manifesting as forgetting earlier decisions, repeating questions, and logical incoherence.
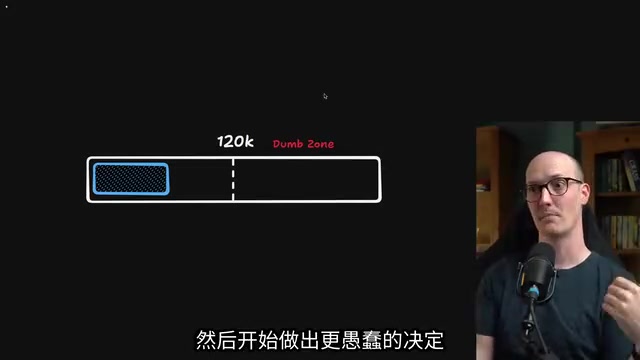
Solution: When facing large-scope work, have the AI agent break it down into smaller sub-scopes upfront, then grill each part separately.
Balancing Proactiveness: Avoiding Two Extremes
Failure Mode 3: Being Too Passive
Many excessively long Grilling sessions stem from the user being too passive. Remember, this is a conversation, not an interview. The AI is asking you questions, but it's your responsibility to figure out the direction, define the scope, and ensure everything stays on track.
If you're too passive, the AI will easily ask you 540 questions, blow the scope wide open, and ask questions at inappropriate fidelity levels.
Failure Mode 4: Being Too Proactive
The other extreme is being overly aggressive—obsessively drilling into a low-fidelity topic when what you actually need is to start building to see how things work.
Key principle: Constantly assess where you fall on the passive-proactive spectrum. Be proactive in steering the direction, but don't be so stubborn that you ignore signals that it's time to move into the coding phase.
Treasure the Decision Outcomes from Grilling Sessions
Failure Mode 5: Discarding the Context from Grilling Sessions

A frustratingly common mistake is when users make numerous excellent design decisions during a Grilling session (potentially consuming 100K tokens), then clear the context and open a new window to run 2PRD.
This is an absolute waste! Every decision made during a Grilling session is incredibly valuable and should be documented and eventually translated into code, or placed in a handoff document for future reference.
The right approach:
- If the context window still has enough room, start implementing directly in the current session
- If you need to exit, use the 2PRD skill to create a handoff document (PRD) rather than starting from scratch. 2PRD can compress what might be tens of thousands of tokens of unstructured conversation—full of exploration, rejections, corrections, and final confirmed decisions—into a structured Product Requirements Document containing feature descriptions, user stories, technical constraints, and acceptance criteria. This document can serve as input for subsequent coding sessions (avoiding the need to re-consume context window to rebuild the decision chain) and as a shared knowledge artifact for team collaboration
- Always preserve the decisions you've made and create some form of handoff artifact for them
How Model Selection Affects Grilling Quality
Failure Mode 6: Using a Model That's Too Weak for Grilling
A model's knowledge comes from two sources:
- Contextual knowledge: Files, prompts, and tool call results you pass to it
- Parametric knowledge: The intrinsic understanding the model learned during training
Grilling relies heavily on parametric knowledge—we depend on the model's intrinsic understanding of systems and applications to surface good ideas and "out-of-the-box" suggestions that we haven't thought of yet. Parametric knowledge is the knowledge learned from massive corpora during pre-training and encoded in billions to trillions of parameter weights, covering programming paradigms, architectural patterns, common pitfalls, best practices, and more. This knowledge is "internalized," allowing the model to perform analogical reasoning and make creative suggestions—for instance, when you describe a data synchronization requirement, it might proactively raise concurrency conflict handling, idempotency design, or eventual consistency strategies you may have overlooked.
When you rely on parametric knowledge this way, you need a frontier model with a large parameter count and top-tier training.
Interestingly, you can use smaller models during the implementation phase, because at that point most information is provided through context (detailed implementation plans, relevant code files, etc.). Specific code modifications primarily rely on the code files and implementation plans provided in context, with relatively lower dependence on parametric knowledge, so you can use more cost-effective and faster models to handle the execution work.
Parallel Grilling to Boost Throughput
Failure Mode 7: Running Only One Session Sequentially

The way to boost efficiency is to run multiple Grilling sessions simultaneously. Here's how: after answering questions in one session, switch to another session (which usually has new questions ready), and alternate back and forth.
This isn't true "context switching"—it's more like managing two independent Slack threads. Traditional context switching is costly because humans need to reload the task state in working memory. But GrillMe's parallel mode is different: the state of each session is maintained by the AI, and the developer only needs to read the latest question and provide an answer. The cognitive load is similar to switching between two chat channels. The core efficiency gain comes from eliminating wait time—when one session is processing your answer and generating the next question (typically 10-30 seconds), you can work in the other session.
The general recommendation is to run at most two sessions simultaneously. Beyond that, the cognitive cost of maintaining decision consistency across sessions rises sharply. You might try three if one of them is performing a time-consuming task (like research). This approach directly doubles your throughput, and as you become more proficient, you can further increase parallelism.
GrillMe Best Practices Checklist
- Distinguish question fidelity: Resolve low-fidelity questions in conversation; hand off high-fidelity questions to prototyping sessions
- Control scope: Break large tasks into smaller scopes to avoid hitting context window limits (empirical threshold of ~120K tokens)
- Stay moderately proactive: Steer the conversation direction, but don't fixate on low-fidelity questions
- Treasure decision outcomes: Don't discard context from Grilling sessions; use 2PRD to create handoff documents
- Use frontier models: The Grilling phase relies on parametric knowledge and needs a smart model; the implementation phase can switch to more economical models
- Work in parallel: Run two sessions simultaneously to boost throughput, leveraging AI response gaps to eliminate wait time
- Exit at the right time: When you need to see actual results, decisively move into the coding phase
Master these principles, and GrillMe will truly become a powerful ally in your engineering planning—rather than a question machine that leaves you exhausted.
Related articles
OpenAI CFO Sarah Fryer on How AI Is Reshaping Finance
OpenAI CFO Sarah Fryer shares real-world AI applications in finance teams, including investor relations GPTs, full-coverage auditing, tax automation, and career advice for the AI era.
GDScript Beginner's Guide: Learning Godot Game Development with AI Assistance
GDScript is Godot's native scripting language with clean syntax and broad platform support. Learn GDScript basics, Cursor AI setup, and effective AI-assisted game development workflows.

Three Forms of AI: From Chat Windows to Collaborative Work to Command Line
AI isn't just a chat window. This article explains AI's three forms: Chatbox, Cowork, and CLI, with selection advice for Claude, Codex, Kimi, and DeepSeek.