A Beginner's Guide to Deep Agents: The Complete Evolution from Basic Agents to Deep Agents

A complete guide to the evolution from basic AI agents to Deep Agents with deep reasoning capabilities.
This article systematically explains the evolution from traditional AI agents to Deep Agents, covering the core three-component architecture (LLM, I/O, Tools), the four development stages of generative AI applications, and how Deep Agents achieve autonomous research through multi-round reasoning, self-reflection, and iterative information synthesis. It also reviews real-world implementations from OpenAI, Anthropic, and Google, and provides a practical learning path for developers.
Introduction: The Evolution of AI Agents
In today's rapidly evolving generative AI landscape, a new concept is sweeping across the industry — Deep Agents. From ChatGPT to Claude and Gemini, major AI companies have rolled out their own "deep research" features, and at the core of these capabilities lies deep agent technology.
Renowned AI educator Krish Naik systematically covered the complete evolution from traditional AI agents to deep agents in his latest long-form tutorial. This article distills the core concepts and key insights to help developers quickly grasp this cutting-edge direction.

What Is an AI Agent? A Review of the Fundamentals
Before diving into deep agents, let's revisit the basic architecture of traditional AI agents.
The Three Core Components of an Agent
A basic AI agent consists of three parts:
- Large Language Model (LLM): Serves as the core decision-making module — the agent's "brain"
- Input/Output Interface: Receives user instructions and returns processed results
- Tools: External APIs or services that extend the LLM's capabilities
It's worth understanding why LLMs can serve as the decision-making core of an agent. Modern large language models are built on the Transformer architecture and acquire powerful language understanding, logical reasoning, and instruction-following abilities through pre-training on massive text datasets. Frontier models like GPT-4, Claude 3.5, and Gemini range from tens of billions to trillions of parameters. After going through pre-training and instruction tuning, they can understand complex natural language instructions and generate structured outputs. More critically, these models possess in-context learning capabilities — without additional training, they can adapt to new task scenarios simply by providing examples or instructions in the prompt. This flexibility is what enables LLMs to act as a "dispatch hub" within agent architectures, dynamically deciding the next action based on user intent.
The workflow is quite intuitive: when a user submits a request, the LLM first determines whether it can generate an answer directly. If it can, it outputs the result immediately. If it can't (e.g., when real-time data is needed), it calls the appropriate external tools to retrieve information, then integrates the results before returning them to the user.
The Technical Implementation of Tool Calling
An agent's tool calling isn't a simple "concatenation" — it relies on a sophisticated Function Calling protocol. Taking OpenAI's implementation as an example, developers define each tool's name, functional description, and parameter structure in JSON Schema format. These definitions are passed to the LLM as part of the system prompt. When the model determines during inference that it needs external information, instead of generating a natural language response, it outputs a structured function call request (containing the tool name and parameter values). The application layer captures this request, executes the actual API call, and injects the returned result back into the conversation context for the LLM to produce the final natural language synthesis. The elegance of this mechanism lies in the fact that the LLM doesn't directly execute code or access the network — it merely "expresses intent" through text generation, while the actual execution is handled by external systems. This ensures both security and unlimited extensibility.
Classic Example: Real-Time Weather Query
Suppose a user asks: "What's the current temperature in Paris?" The LLM itself doesn't have real-time data retrieval capabilities — its training data has a cutoff date (for example, GPT-4's training data cuts off at the end of 2023, meaning it cannot know about any events or real-time data changes after that point). In this case, the agent needs to call a weather API (such as SERP API, OpenWeatherMap, or other third-party services) to fetch real-time weather information, then organize the result into natural language for the user.
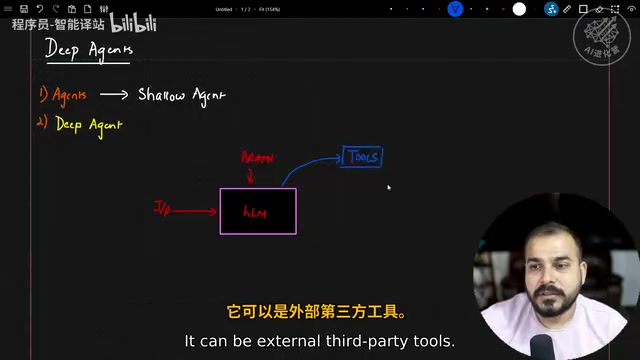
This is the most basic type of agent — a single-step tool-calling Agent. It can handle simple tasks, but falls short when facing complex, multi-step research questions.
The Four-Stage Evolution from Basic Agents to Deep Agents
The Development Stages of Generative AI Applications
Looking back at the entire generative AI development journey, we can clearly identify four stages:
| Stage | Characteristics | Typical Applications |
|---|---|---|
| Stage 1 | Direct LLM usage | Simple Q&A, text generation |
| Stage 2 | Standalone agents | Single agent with tool calling |
| Stage 3 | Multi-agent collaboration | Multi-Agent systems with division of labor |
| Stage 4 | Deep agents | Agents with deep reasoning and autonomous research capabilities |

Each stage represents a capability upgrade over the previous one. From simply calling an LLM to generate text, to equipping agents with tool-use capabilities, to enabling collaboration and division of labor among multiple agents, and finally evolving into today's deep agents.
From Single Agent to Multi-Agent: The Rise of Collaborative Architectures
Before understanding deep agents, it's essential to grasp Stage 3 — the design philosophy of Multi-Agent Systems — because deep agents largely inherit and deepen the architectural ideas of multi-agent systems.
The core idea of multi-agent systems is "divide and conquer": breaking down a complex task and assigning it to multiple specialized agents, each responsible for a specific subdomain. The industry currently has three main collaboration paradigms: Hierarchical — a "manager agent" coordinates multiple "executor agents"; Peer-to-Peer — multiple agents negotiate as equals, reaching consensus through message passing; Supervised — a reviewer agent performs quality control on other agents' outputs. Representative frameworks include Microsoft's AutoGen (supporting multi-agent conversational collaboration), CrewAI (a role-playing-based task division framework), and LangGraph from the LangChain ecosystem (a graph-structured state machine-style agent orchestration tool). These frameworks allow developers to organize multiple AI agents like assembling a team, where each agent has its own system prompt, toolset, and memory space, collaborating to accomplish complex tasks that a single agent couldn't handle alone.
The Fundamental Difference Between Deep Agents and Traditional Agents
The limitation of traditional agents is that they typically execute single-step or few-step task chains. The user asks a question, the agent calls a tool, and returns the result — the entire process is relatively linear and shallow.
Deep agents differ fundamentally in four ways:
- Multi-round deep reasoning: Rather than simply answering a question in one shot, they think, search, and verify iteratively — like a researcher
- Autonomous planning: They can decompose complex problems into multiple subtasks and autonomously plan the execution order
- Iterative information synthesis: They continuously accumulate and integrate information across multiple rounds, progressively converging on the final answer
- Self-reflection and error correction: They can evaluate their intermediate results and proactively conduct additional research when gaps are identified
These capabilities of deep agents didn't emerge from thin air — they're built on a series of breakthroughs in reasoning enhancement techniques in recent years. The most representative is Chain-of-Thought (CoT) — by guiding the model to "think step by step" in the prompt, it significantly improves LLM performance on complex reasoning tasks. Building on this, researchers proposed Tree-of-Thought (ToT) — allowing the model to generate multiple candidate solutions at each reasoning step and select the optimal path through evaluation and backtracking, similar to the human "trial-and-error-then-reflect" process. The more advanced ReAct framework (Reasoning + Acting) interleaves reasoning with action: the model first performs a reasoning step (Thought), then executes an action (Action), observes the result (Observation), and reasons about the next step based on that observation, forming a "think-act-observe" loop. Deep agents combine these reasoning paradigms with multi-round tool calling and long-term memory management to achieve truly autonomous research capabilities. The "deep thinking" mode introduced by OpenAI in its o1 and o3 series models, and the "Extended Thinking" implemented by Anthropic in Claude, are both productized manifestations of this technical approach.
This is also why major AI companies name their products "deep research" — they simulate the complete process of a human researcher conducting in-depth investigation on a topic.
Real-World Applications of Deep Agents
Deep agents have already been deployed in several mainstream AI products:
- OpenAI's Deep Research: A deep research feature integrated into ChatGPT that can spend several minutes conducting comprehensive research on a complex question. Powered by the o3 model's enhanced reasoning capabilities combined with web browsing tools, it can autonomously plan search strategies, read multiple web pages, cross-verify information, and ultimately generate a complete research report with cited sources
- Anthropic's Claude: Equipped with long-chain reasoning and multi-step task execution capabilities. The "Computer Use" feature introduced in the Claude 3.5 series extends the agent's capability boundary from API calls to GUI-level operations, allowing the agent to operate browsers and edit documents just like a human
- Google's Gemini Deep Research: A deep research agent that integrates Google Search capabilities. Leveraging Google's deep expertise in search, Gemini's deep research feature has a natural advantage in the breadth and timeliness of information retrieval, with access to billions of web pages indexed by Google
The common thread among these products is that they no longer prioritize "instant responses." Instead, they're willing to spend more time on deep thinking and multi-round information retrieval to ultimately deliver a more comprehensive and accurate research report. This shift in design philosophy is profoundly significant — it marks a paradigm shift in AI products from "instant-response assistants" to "deep research partners." Traditional AI interactions prioritize low latency, with users expecting replies within seconds. Deep agents redefine user expectations, making people accept the trade-off of "waiting 5-10 minutes for a high-quality research report" — an interaction model much closer to the experience of commissioning a professional analyst to conduct research.
How Developers Can Get Started with Deep Agent Development
Choosing Your Tech Stack
For developers looking to build their own deep agents, the LangChain ecosystem is an excellent starting point.
LangChain was originally created by Harrison Chase in late 2022 to simplify LLM-based application development. After more than two years of rapid iteration, it has grown into a vast ecosystem with multiple core sub-projects: the LangChain core library provides foundational abstractions like Chains, Prompt Templates, and Output Parsers; LangGraph is an orchestration framework specifically designed for agent development that models the agent's execution flow as a directed graph, where each node represents a processing step (such as LLM reasoning, tool calling, or conditional branching) and edges represent state transitions — this graph structure is naturally suited for expressing the complex cyclical reasoning and conditional branching logic in deep agents; LangSmith is the companion observability platform that provides tracing, debugging, and evaluation capabilities for agent execution processes, which is especially important for debugging multi-round reasoning in deep agents.
The LangChain ecosystem supports:
- Flexible tool definition and registration
- Multiple agent execution strategies (ReAct, Plan-and-Execute, etc.)
- Seamless integration with mainstream LLMs (OpenAI, Anthropic, Google, open-source models, and more)
- State management and memory mechanisms (short-term memory, long-term memory, vector database integration)
Beyond LangChain, developers should also consider other noteworthy frameworks: LlamaIndex excels at data indexing and RAG (Retrieval-Augmented Generation) scenarios, making it ideal for building deep agents that require extensive knowledge retrieval; Semantic Kernel is Microsoft's AI orchestration SDK with deep Azure ecosystem integration; and for developers seeking lightweight solutions, OpenAI's Assistants API and Anthropic's Tool Use API provide out-of-the-box agent capabilities without requiring additional frameworks.
Recommended Learning Path
- Build a solid foundation: Start by understanding how basic agents work (LLM + Tools + decision loop). Begin by implementing a simple ReAct Agent, manually writing the "think-act-observe" loop to deeply understand the agent's decision-making mechanism
- Master multi-agent collaboration: Learn how to coordinate multiple agents to complete complex tasks together. Try using LangGraph to build a collaborative system with a "Researcher Agent," a "Writer Agent," and a "Reviewer Agent"
- Dive into deep agents: Understand the implementation mechanisms of deep reasoning, autonomous planning, and iterative research. Focus on learning how to implement an agent's self-reflection loop and dynamic task re-planning
- Get hands-on: Build your own Deep Agent prototype using frameworks like LangChain. Start with a specific use case (such as automated competitive analysis or academic literature review generation) and refine the agent's reasoning depth and output quality through real-world problems
Conclusion and Outlook
Deep agents represent the latest direction in AI application development. They're not just an incremental technical upgrade — they represent a fundamental shift in the AI application paradigm, moving from "quick answers" to "deep research" and from "tool calling" to "autonomous reasoning."
From a broader perspective, the rise of deep agents also signals that the AI industry is shifting from a "model capability race" to a "systems engineering race." The marginal returns of simply scaling up model parameters and training data are diminishing. The new competitive frontier is how to transform model capabilities into reliable end-to-end solutions through sophisticated system design — including reasoning strategies, tool orchestration, memory management, and quality control. This also means that the core competency of future AI developers won't just be "knowing how to call APIs," but having the architectural ability to design complex agent systems.
For developers, now is the perfect time to learn and invest in deep agent technology. As major frameworks and toolchains continue to mature, building your own Deep Agent will become increasingly accessible. The key is understanding the core philosophy: enabling AI to think, plan, execute, and reflect like a human researcher.
Key Takeaways
Related articles
Claude Code Installation Guide & The Five Stages of AI Programming Tools Explained
Complete Claude Code installation guide with the five stages of AI programming tools, from manual coding to agents. Learn 0-to-1 project building and 1-to-100 iteration challenges.

Enterprise-Level AI Project Rules Files: 5 Hard Rules + 6 Writing Techniques
AI keeps messing up your code? Learn 5 hard rules and 6 writing techniques for enterprise-level Rules files in Claude Code, Cursor & more, with templates.
Building Cloud Computing Clusters from Old Phones: Google and UCSD Explore a New Path to Sustainable Computing
Google and UCSD explore building cloud clusters from old phones, leveraging ARM chip efficiency to cut e-waste and data center carbon footprints.