Agent Skills: Folders as Skills — Making AI Produce Precise, Template-Based Output

Agent Skills uses folder-based skill modules with on-demand loading to make AI output precise and template-driven.
Agent Skills solves the core problems of traditional AI agent development — cost explosion, hallucinations, and maintenance nightmares — by organizing AI capabilities into independent skill folders loaded dynamically on demand. Through a three-stage progressive disclosure mechanism (metadata indexing, intent matching, script execution), it reduces token consumption by 80% while significantly improving output quality and consistency.
When you give a large language model a complex task, it invariably makes all kinds of mistakes — fabricating content, missing details, producing messy formatting. You spend enormous amounts of time correcting the model, and efficiency plummets. Agent Skills is a technical solution designed to solve exactly this pain point: it breaks down AI capabilities into independent skill folders, dynamically loads them on demand, and lets the model generate final deliverables directly according to your templates.
Three Major Challenges in Traditional Agent Development
In traditional Agent development, developers need to provide AI with massive amounts of prompt text to align requirements. The typical approach is to dump all of an organization's documents, rules, and tool descriptions into the model at once, creating context windows that easily run into thousands of lines. This creates three serious problems:
Cost Explosion: Every API call must carry the full context, causing token costs to grow exponentially. A request that should cost a few cents can become dozens of times more expensive because it carries a huge amount of irrelevant information. To understand the severity of this problem, you need to understand how token pricing works: Tokens are the basic units that large language models use to process text — in Chinese, roughly every 1–2 characters correspond to one token, while in English, approximately every 4 characters correspond to one token. Current mainstream models like GPT-4o and Claude 3.5 support context windows of 128K tokens or even longer, but token consumption is directly tied to API call costs. Taking GPT-4o as an example, input tokens cost approximately $2.50 per million tokens, while output tokens cost about $10. More critically, research has shown that models exhibit a "Lost in the Middle" phenomenon when processing very long contexts: information located in the middle of the context is more likely to be ignored. This means stuffing in more information not only increases costs but can actually reduce output quality.
Amplified Hallucinations: Information overload severely scatters the model's attention. When AI faces thousands of lines of documentation, it actually becomes more likely to fabricate content, and output quality drops sharply. This isn't a matter of insufficient model capability — it's that we've placed too heavy a burden on it. From a technical perspective, LLM hallucination refers to the model generating content that appears plausible but is actually incorrect or entirely fabricated. The root cause lies in the fact that large language models work by probabilistically predicting the next token, rather than performing true knowledge retrieval. When a model faces too much information, the Attention Mechanism must distribute weights across a massive number of tokens, diluting its focus on key information. A 2023 Stanford study showed that as input context length increases, model accuracy on factual tasks exhibits a clear downward trend. This is also the underlying reason why "precision feeding" strategies like RAG (Retrieval-Augmented Generation) and Agent Skills are more effective than "full dump" strategies.
Maintenance Nightmare: Thousands of lines of prompts are difficult to manage, and every business change requires manual modifications. Conflicts arise frequently during team collaboration, making efficient coordination nearly impossible.

The Core Design of Agent Skills: Folders as Skills
The core idea behind Agent Skills is elegantly simple — break AI capabilities into independent skill folders and load them dynamically on demand. Only when the AI needs a particular skill does it load the corresponding content.
Standard Skill Folder Structure
A standard Skill folder contains the following components:
- skill.md (required): A skill specification written in Markdown, containing metadata, usage scenarios, and execution workflows
- scripts/: Stores Python code or scripts that provide utility functions for the model
- references/: Stores detailed documentation and examples for the model to consult when needed
- assets/: A static resources folder for images, configuration files, etc.
Take an "Order Coffee" skill as an example: after the model decides to use this skill, it first reads skill.md to understand the overall workflow. When the workflow mentions "For ordering steps, see references/order_coffee.md," only then does the model read that detailed document. This is the essence of on-demand loading.
Team Collaboration and Version Management
This folder structure naturally supports team division of labor: developers are responsible for writing utility functions and API wrappers in scripts; product managers or domain experts are responsible for writing skill.md and organizing reference materials; the AI model is responsible for reading instructions, calling tools, consulting references, and executing tasks. More importantly, the entire skill set can be version-controlled with Git, allowing multiple people to develop in parallel without conflicts. This approach of "codifying" AI capabilities gives prompt engineering software-engineering-level maturity for the first time — enabling Code Review, branch management, rollback operations, and even automated testing to verify Skill output quality.
Progressive Disclosure: Dual Optimization of Token Cost and Output Quality
Some might ask: aren't Skills essentially just prompts? Why wouldn't they cause context overload too? The answer lies in the "Progressive Disclosure" mechanism.
Progressive Disclosure was originally a classic design principle in human-computer interaction, proposed by IBM researcher John M. Carroll in the 1980s. Its core idea is to "only present information when the user needs it." This principle is widely applied in software interface design — for example, Photoshop's menu hierarchy, or the tiered expansion of phone settings. Agent Skills migrates this concept to AI prompt engineering: instead of stuffing all instructions and reference materials into the model at once, it establishes a layered index structure that lets the model progressively "unfold" the information it needs based on the task at hand. This is analogous to the "Lazy Loading" strategy in computer science — only allocating resources when they're actually needed.
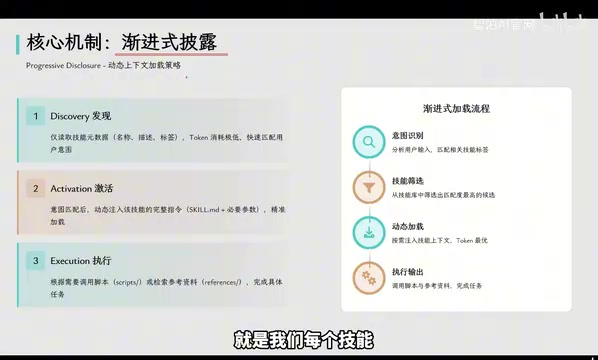
Three-Stage Loading Strategy in Detail
Stage 1: Metadata Indexing. The first line of each Skill's skill.md contains metadata with only the skill name and trigger conditions (e.g., "When the user needs to place a coffee order"). At system startup, the model only reads the metadata of all Skills to understand what capabilities are available. The metadata is extremely brief, with minimal token consumption.
Stage 2: Intent Matching and Activation. When a user says "Order me an Americano," the model recognizes that the intent matches the "Place Coffee Order" skill, and only then fully loads that Skill's skill.md specification and necessary parameters. The intent matching at this stage is essentially similar to a search engine's query-document matching process — the model uses semantic understanding to compare user input against trigger conditions in skill metadata and selects the most relevant skill to activate.
Stage 3: Script Execution. When a task requires code execution (such as calling an ordering API), the model only needs to express the intent "I want to execute this script." The system runs the code in an isolated virtual environment and returns the results to the model. Throughout this process, the model never sees the code content and it consumes zero tokens. This design cleverly separates "decision-making" from "execution" — the model handles understanding requirements and orchestrating workflows (what it's good at), while actual code execution is handled by a deterministic runtime environment (avoiding errors the model might make in code generation).
The results of this mechanism: token usage reduced by 80%, LLM hallucinations significantly decreased, and output quality markedly improved.
Hands-On Demo: Building a Chip Review Skill from Scratch

Quickly Generating Skill Files with Kimi
You don't need to write all files from scratch. Here's a practical workflow for quickly building a Skill:
- Go to the agentskills.io website, navigate to the Specification page, and click "Copy Page" to copy the complete Skill development specification
- Open Kimi (using the K2.5 Agent feature) and tell it your requirements: "Help me write an Agent Skill for generating professional tech product chip review documents"
- Paste the specification document to Kimi and have it generate the complete Skill files in the standard format
Kimi is a large language model product launched by Moonshot AI. Its K2.5 version features an Agent mode capable of autonomous web searching, information synthesis, and multi-step task execution. In this hands-on case, Kimi's Agent capabilities are demonstrated on two levels: first, it can understand the Agent Skills specification document and generate structured output in the standard format; second, it proactively searches the internet for chip review articles, learning real-world review methodologies and writing paradigms to generate more professional and realistic Skill templates. This "learn first, then generate" working pattern is itself a typical application of Agent capabilities.
Kimi will automatically search relevant web pages to understand how real chip reviews are done, then generate a complete Skill folder structure for you: the skill.md main skill document, detailed CPU documentation, detailed GPU documentation, architecture analysis documentation, power consumption and thermal analysis documentation, and more.
Deploying and Testing in a Dify Workflow
After downloading the generated Skill files, simply upload them to the Dify workflow platform to complete the "skill installation." Dify is an open-source LLM application development platform that provides a visual workflow orchestration interface, allowing developers to build complex AI application flows by dragging and dropping nodes. It supports integration with OpenAI, Anthropic, locally deployed models, and various other LLM backends, with built-in features for knowledge base management, tool invocation, and variable passing. In the Agent Skills use case, Dify serves as the "skill runtime" — developers upload Skill files as knowledge base documents and use workflow nodes to automate the process of intent recognition, skill matching, and result generation. Compared to pure code development, Dify significantly lowers the barrier to deploying AI applications.
During testing, input "Please write a chip review document for the RTX 3060," and the AI will automatically match the skill, read the guidance materials in references, and generate a standardized review report — complete with chip specifications, architecture analysis, technical highlights, performance benchmarks, gaming test data, power consumption and thermal analysis, and other comprehensive sections.
The key point is: this Skill completely locks down the AI's working method, ensuring it always generates standardized results, fundamentally preventing content fabrication and formatting chaos.
Conclusion: Best Practices for Structured Prompt Engineering
The value of Agent Skills can be summarized in one sentence: achieving extremely high task accuracy at extremely low token cost. It's not an entirely new technical paradigm, but rather a structured upgrade to prompt engineering — through folder organization, progressive disclosure, and on-demand loading, it transforms "one massive blob of a Prompt" into manageable, collaborative, and reusable skill modules.
From a broader perspective, Agent Skills represents an important step in AI application development moving from "artisan workshop" to "industrial production." Just as software engineering evolved from early spaghetti code to modular, object-oriented architectures, prompt engineering is undergoing a similar paradigm shift. By introducing clear file structures, separation of concerns, and version management, Agent Skills makes it possible for the first time to develop and maintain AI capabilities with true engineering rigor.
Currently, Agent Skills can be used across multiple platforms including Cloud Code, VS Code extensions, Cursor IDE, Dify workflows, and the LangChain framework. For teams that frequently collaborate with AI, this technology is worth adopting into daily workflows as early as possible.
Related articles

AI Agent Development: A Complete 6-Week Systematic Learning Roadmap
A 6-week systematic learning roadmap for AI Agent development, covering core architecture, ReAct principles, multi-agent collaboration, RAG integration, and deployment.
Four Core Advantages Frontend Developers Have When Transitioning to AI Agent Development
Frontend developers have key advantages for AI Agent development: TypeScript ecosystem fit, low-barrier full-stack bridging, and state management isomorphism. Learn the transition path here.
DiffusionGemma: Google's Open-Source Diffusion Language Model Exceeding 500 Tokens/s
Google releases DiffusionGemma, an open-source diffusion language model with Apache 2.0 license. The 26B-parameter MoE model achieves over 500 tokens/s in real-world tests.