DiffusionGemma: Google's Open-Source Diffusion Language Model Exceeding 500 Tokens/s
Google open-sources DiffusionGemma, a diffusion-based language model achieving 500+ tokens/s generation speed.
Google has released DiffusionGemma, an open-weight diffusion language model under the Apache 2.0 license. Built on a 26B-parameter Mixture of Experts architecture with only 4B active parameters, it generates text by parallel denoising rather than sequential token prediction. Real-world API tests show speeds exceeding 500 tokens/s — several times faster than typical autoregressive models. Hosted free on NVIDIA NIM and available on Hugging Face, it marks a significant step toward practical diffusion-based text generation.
Google has quietly released a remarkable open-source model — DiffusionGemma — officially bringing last year's experimental Gemini Diffusion technology to life as an open-weight model under the Apache 2.0 license. This marks the transition of diffusion-based text generation from experiment to a usable open-source ecosystem.
From Experiment to Open Source: The Return of Gemini Diffusion
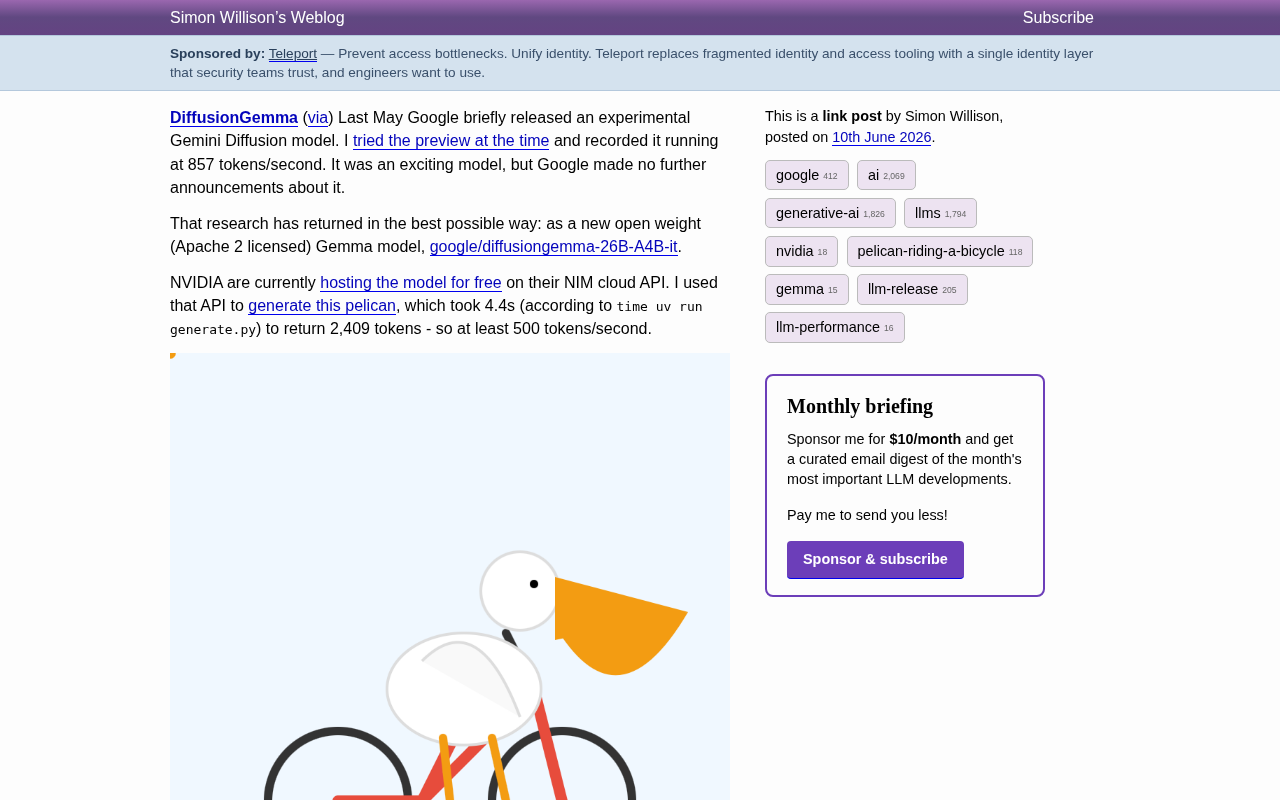
Last May, Google briefly released an experimental Gemini Diffusion model. At the time, developer Simon Willison tested it during the preview and recorded an astonishing generation speed of 857 tokens/s, but Google made no further announcements afterward, and the research seemed to go silent.
However, this research has returned in the best possible way — as a brand-new open-weight Gemma model officially released to the public. The full model name is google/diffusiongemma-26B-A4B-it, now publicly available on Hugging Face under the Apache 2.0 open-source license, meaning developers can freely use it for both commercial and non-commercial projects.
What Is a Diffusion Language Model?
Traditional large language models (such as GPT, Gemma, etc.) generate text using an autoregressive approach, predicting the next token one at a time in sequence. While this method produces good results, its speed is bottlenecked by serial generation. Specifically, the autoregressive model's serial generation mechanism means that generating the Nth token requires waiting for all N-1 preceding tokens to complete, causing generation latency to scale linearly with output length. Even on high-end GPUs, this sequential dependency cannot be overcome by simply adding more compute power. Although the industry has developed optimization techniques like KV Cache and Speculative Decoding to reduce redundant computation or predict multiple tokens, these methods don't fundamentally change the token-by-token generation paradigm.
Diffusion language models borrow the core idea from image generation (such as Stable Diffusion): instead of generating tokens one by one, they start from noise and generate multiple tokens simultaneously through a multi-step denoising process. This parallel generation capability enables dramatically faster inference speeds — and this is the key reason DiffusionGemma can achieve hundreds or even thousands of tokens per second.
It's worth noting that migrating diffusion models from the image domain to the text domain is far from a simple technical transplant. The success of diffusion models in image generation (from DDPM to Stable Diffusion) is built on denoising processes in continuous pixel space, but text is inherently a discrete token sequence, presenting fundamental technical challenges. Researchers have gradually addressed these issues through multiple innovative approaches: mapping discrete tokens to continuous embedding spaces for diffusion operations, designing noise scheduling strategies suitable for sequential data, and introducing techniques like Masked Diffusion — which, rather than adding Gaussian noise in continuous space, achieves a similar generation process by progressively masking and recovering tokens. DiffusionGemma's technical approach likely incorporates these cutting-edge research advances, enabling diffusion-based text generation to reach practical levels in both quality and speed.
Performance Testing: Generation Speed Exceeding 500 Tokens/s
DiffusionGemma's model specifications are 26B parameters with A4B (a Mixture of Experts architecture with approximately 4B active parameters), a design that significantly reduces inference costs while maintaining model capability.
The Mixture of Experts (MoE) architecture here deserves a deeper look. The core idea of MoE is to divide model parameters into multiple "expert" sub-networks, with a learnable gating mechanism activating only a small subset of experts to process the current input during each inference pass. Of DiffusionGemma's 26B total parameters, only about 4B are activated, meaning the model possesses the knowledge capacity and expressiveness of a large model while its actual computational load per inference is close to that of a 4B parameter small model. Google's Gemma series, Mistral AI's Mixtral, and DeepSeek's V3 all employ this architecture, which strikes an excellent balance between parameter efficiency and inference cost — especially suitable for deployment scenarios requiring high throughput.
NVIDIA currently hosts the model for free on its NIM cloud API, allowing developers to call and experience it directly. Simon Willison tested it using the API: generating a pelican-riding-a-bicycle illustration containing SVG code returned a total of 2,409 tokens in just 4.4 seconds — translating to at least 500 tokens/s generation speed.
For comparison, current mainstream autoregressive models on cloud APIs typically achieve speeds of 50–150 tokens/s, making DiffusionGemma's speed advantage very significant. While this test's 500 tokens/s is lower than last year's experimental version at 857 tokens/s, considering network latency and API overhead, the actual model inference speed is likely even higher.
An Important Step for the Open-Source Ecosystem
This release has several noteworthy highlights:
Apache 2.0 License: No Barriers to Commercial Use
Unlike some previous Gemma models that used custom licenses, DiffusionGemma directly adopts the highly permissive Apache 2.0 license. Apache 2.0 is one of the most permissive licenses in the open-source world, allowing commercial use, modification, and distribution without requiring derivative works to be open-sourced (in stark contrast to "copyleft" licenses like GPL). By comparison, Meta's LLaMA series initially used custom licenses restricting commercial use, and some of Google's earlier Gemma models also came with usage restriction clauses. DiffusionGemma's choice of Apache 2.0 means businesses of any size can build commercial products on top of it without additional authorization — a major benefit for enterprise applications and community-driven development, and one that will significantly accelerate the industrialization of diffusion language models.
Mixture of Experts Architecture: Lowering the Deployment Barrier
The MoE (Mixture of Experts) design with 26B total parameters and approximately 4B active parameters means this model could potentially run on consumer-grade hardware. While the full model weights require loading 26B parameters into VRAM (roughly 52GB in FP16, or less with quantization techniques), the computational load during inference is equivalent to only a 4B model. This means it could potentially run on consumer-grade GPUs with sufficient VRAM (such as an NVIDIA RTX 4090 with 24GB VRAM combined with quantization). This lowers the barrier for local deployment, enabling more developers to experience diffusion-based text generation on their own devices.
Deep NVIDIA Involvement: Hardware Ecosystem Is Ready
NVIDIA's immediate provision of free hosting on the NIM platform indicates that hardware vendors are already prepared for inference optimization of diffusion language models. NVIDIA NIM (NVIDIA Inference Microservices) is NVIDIA's model inference deployment platform, offering pre-optimized containerized inference services that automatically tune performance for the underlying GPU hardware.
The natural alignment between diffusion models' parallel generation characteristics and GPUs' parallel computing architecture deserves deeper understanding. Traditional autoregressive models produce only one token at a time during the decode phase, leaving most of the GPU's thousands of compute cores idle. The inference bottleneck is often memory bandwidth (repeatedly reading model weights) rather than compute power — known as being "memory-bandwidth bound." In contrast, diffusion models process all positions in the entire sequence simultaneously during each denoising step, fully utilizing the GPU's massively parallel compute units (CUDA cores and Tensor Cores), dramatically improving hardware utilization. This difference in computational characteristics means that the same GPU hardware may achieve far higher actual throughput when running diffusion models compared to autoregressive models, with potentially even greater optimization headroom in the future.
Future Outlook for Diffusion-Based LLMs
The release of DiffusionGemma may signal an important paradigm shift in large language model inference. If diffusion-based generation can approach or even match autoregressive models in quality, its multi-fold or even tenfold speed advantage could fundamentally transform LLM application scenarios — real-time conversation, streaming code generation, large-scale batch processing, and more would all directly benefit. Particularly in latency-sensitive applications (such as real-time voice assistant responses, interactive programming assistance, NPC dialogue generation in games, etc.), boosting generation speed from 100 tokens/s to 500+ tokens/s means users can experience near-instantaneous responses.
Of course, diffusion language models are still in a relatively early stage, and whether they can rival mature autoregressive models in complex reasoning and long-text coherence still requires extensive testing and validation by the community. An inherent challenge of diffusion models is that since all tokens are generated in parallel, the model may not maintain sequential dependencies as naturally as autoregressive models when handling tasks requiring strict sequential logic (such as multi-step mathematical reasoning or long-chain causal reasoning). Additionally, the number of diffusion steps is a critical quality-speed tradeoff parameter: more denoising steps generally mean higher generation quality but also reduce the speed advantage. Finding the optimal balance between these two will be an important direction for future research.
However, Google's decision to release this model as open source undoubtedly provides the entire research community with an important benchmark and starting point. This also continues the open-source trend in the large model space during 2024–2025 — from Meta's LLaMA series to Mistral, DeepSeek, and Google's Gemma family, leading labs are accelerating industry-wide technological iteration through open source.
For developers who want to try it out, you can call it for free directly through the NVIDIA NIM API or download the model weights from Hugging Face for local deployment. This may be the most convenient way to experience the "future of LLM inference" right now.
Related articles
AI Large Model Learning Roadmap Breakdown: Three Stages from Application Development to Model Fine-Tuning
Deep breakdown of a popular AI large model learning roadmap covering LangChain, RAG, Agent, and LoRA fine-tuning across three stages, with analysis of its strengths and limitations for career changers.

AI Agent Development: A Complete 6-Week Systematic Learning Roadmap
A 6-week systematic learning roadmap for AI Agent development, covering core architecture, ReAct principles, multi-agent collaboration, RAG integration, and deployment.
Four Core Advantages Frontend Developers Have When Transitioning to AI Agent Development
Frontend developers have key advantages for AI Agent development: TypeScript ecosystem fit, low-barrier full-stack bridging, and state management isomorphism. Learn the transition path here.