Is Context Engineering the Core of Agent Development? A Deep Dive into a High-Frequency Interview Question
Is Context Engineering the Core of Age…
Agent development's core is context engineering: dynamically managing info flow for stateless LLMs.
This article deconstructs a high-frequency LLM interview question, arguing that the core of Agent development is context engineering. Since LLMs are fundamentally stateless functions, an Agent's intelligence stems from dynamically assembling context across five modules: system instructions, task planning, memory systems, tool space, and external observations. To address four critical pain points — lost-in-the-middle attention, noise-induced hallucinations, tool overload, and state desynchronization — the article proposes four advanced solutions: summary compression, hybrid retrieval with reranking, multi-agent architecture, and deterministic state machines.
Introduction: An Interview Question with Hidden Depth
"Some say the core of Agent development is context engineering. Do you agree?"
This seemingly simple interview question is actually a minefield. If you just answer "agree" or "disagree," you've already lost half the battle. On the surface, it's testing your understanding of prompts, but in reality, it's probing your foundational expertise in Agent architecture design.
Based on an in-depth breakdown by Bilibili creator Peng Yu, this article systematically deconstructs the complete answer path for this advanced LLM interview question, helping you thoroughly understand the underlying logic of Agent development.
Why I Strongly Agree: Understanding the True Nature of LLMs
At its core, a large language model is a stateless function — it has no memory, doesn't think proactively, and won't call tools on its own. All the "intelligence" you see an Agent display — planning, reflecting, researching — fundamentally exists because we precisely assemble the environmental state, historical memory, and task objectives into a context and feed it to the model at every moment.
Therefore, the core of Agent development is upgrading "writing prompts" from a trivial task into a dynamic state management engineering discipline.

The Five Core Modules of Context
A mature Agent's context is far more than a single sentence — it's dynamically assembled from five essential building blocks:
System Instructions: The Agent's Identity Card
These define the Agent's role, personality, and safety boundaries, determining its behavioral limits and fundamental persona. This is the most stable part of the context, yet also the most easily overlooked architectural cornerstone.
Task Planning: The Agent's Scratch Pad
This records which step the current task decomposition has reached, serving as the critical support for complex reasoning and multi-step execution. Without clear task planning, an Agent loses its way when facing complex problems.
Memory System: Short-Term and Long-Term Memory
This splits into short-term chat history and long-term historical information. Short-term memory maintains conversational coherence, while long-term memory needs to be dynamically retrieved from vector databases. The quality of memory management directly determines the Agent's "intelligence ceiling."
Tool Space: The Agent's Toolbox
This tells the Agent what "wrenches and screwdrivers" it currently has at hand — the descriptions, parameters, and invocation methods of available APIs. The quality of tool descriptions directly impacts the model's invocation accuracy.
External Observations: The Feedback Channel to the Real World
This includes things like freshly retrieved news, API return results, or error messages — the real-time feedback from the Agent's interaction with the real world. Without external observations, the Agent is essentially "driving blind."

All five of these components are constantly changing. How to efficiently fit them into the context window is the first step in context engineering.
Four Critical Pain Points: Why You Can't Just Stuff Everything In
Some might ask: Don't modern LLMs already have context windows of hundreds of thousands or even millions of tokens? Why not just stuff everything in?
Don't fall into that trap. This is precisely where you demonstrate real-world experience in an interview. Agent development faces four core pain points:
Pain Point 1: Lost in the Middle
When you stuff too much in, the model develops "intermittent amnesia" for information in the middle. Research shows that models pay the most attention to information at the beginning and end of the context, while the middle tends to be overlooked. Moreover, the longer the context, the slower the inference and the higher the cost.
Pain Point 2: Noise Interference Causing Hallucinations
If retrieved documents contain incorrect or irrelevant information, the model gets led astray and starts "confidently spouting nonsense." Garbage in, garbage out — this is especially fatal in RAG scenarios.
Pain Point 3: Tool Overload Triggering Choice Paralysis
If you give an Agent 100 tool descriptions, it gets overwhelmed and may even hallucinate non-existent parameters. The more tools there are, the worse the choice paralysis becomes, and invocation accuracy drops off a cliff.
Pain Point 4: State Desynchronization Causing Infinite Loops
The Agent thinks it executed successfully, but the external environment actually returned an error. If the context isn't updated in time, the Agent gets stuck in an infinite loop, repeatedly executing the same failed operation.

The Dynamic Assembly Engine: Four Advanced Solutions
This is the real substance interviewers want to hear — how to systematically solve the pain points above.
Solution 1: Context Compression — Say Goodbye to Redundancy
When conversations get too long, have the model generate its own summary and replace the full history with condensed information. The core idea is to preserve semantics while compressing tokens. In practice, you can set a token threshold that automatically triggers the summary compression process when exceeded.
Solution 2: Hybrid Retrieval and Reranking — Three-Layer Filtering for Purity
You can't rely solely on semantic search (embedding similarity); you also need a reranking model (Reranker) to ensure the information fed into the context is absolutely clean and relevant. Keyword retrieval + semantic retrieval + reranking — this three-layer filtering mechanism dramatically reduces noise interference.
Solution 3: Dynamic Tool Recall and Multi-Agent Architecture
When facing hundreds of tools, first use a lightweight model to select the 5 most relevant ones, then place those 5 into the main model's context. Or simply delegate tasks to different sub-Agents, achieving tool-level "physical isolation" where each sub-Agent only focuses on a small number of tools within its own domain.
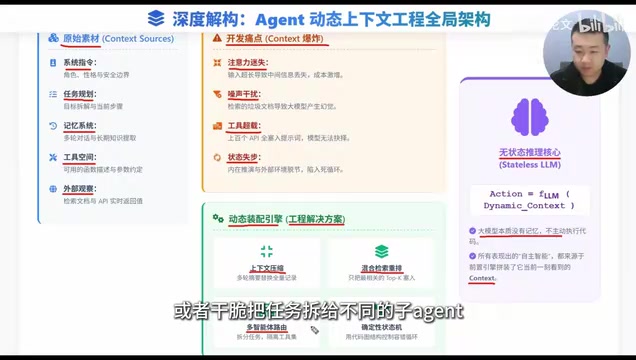
Solution 4: Deterministic State Machines — Code Manages Flow, Models Make Decisions
Don't rely entirely on the model to self-reason within prompts. Use graph-based frameworks (like LangGraph) to codify the logic, and use code to enforce error handling and loop control. The core principle is: use code for deterministic processes, and delegate uncertain decisions to the model.
The Complete Interview Answer Path
If an interviewer asks you this question, I recommend organizing your answer along the following path:
- Clearly agree: Compare context to the Agent's "bloodstream" and "short-term brain," explaining the stateless nature of LLMs
- Demonstrate structured thinking: Break down the five modules of context — system instructions, task planning, memory system, tool space, and external observations
- Address engineering pain points directly: Discuss lost-in-the-middle, noise-induced hallucinations, tool overload, and state desynchronization
- Present advanced solutions: Summary compression, hybrid retrieval with reranking, multi-agent isolation, and LangGraph state machine control
Walking through these four steps demonstrates both theoretical depth and practical experience — making it hard for the interviewer not to give you a high score.
Conclusion
Agent development is absolutely not a word game — it's building a complex information flow system. The essence of context engineering is dynamically assembling the optimal combination of information within a limited attention window, enabling a stateless LLM to make the best possible decision on every single call.
Once you understand this, you'll understand why more and more people in the industry are upgrading "Prompt Engineering" to "Context Engineering" — because real Agent development isn't about managing a single prompt, but an entire dynamically evolving information ecosystem.
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.