AI Benchmarks: The Most Underrated Technical Startup Opportunity Right Now

Public AI benchmarks represent a massive, underrated startup opportunity as traditional evaluations fail to keep pace.
As AI models rapidly outpace existing evaluation systems, creating high-quality public benchmarks has become one of the most underrated opportunities in tech. Traditional tests like MMLU and HumanEval are being maxed out, creating an evaluation vacuum. Those who build trusted, contamination-resistant benchmarks that reflect real-world use cases can gain outsized industry influence and clear commercialization paths — all without requiring massive compute budgets.
Why AI Benchmarks Are the Most Underrated Opportunity Today
In an era of rapid AI iteration, a seemingly inconspicuous yet critically important field is revealing enormous opportunity — public AI benchmarks. Recently, a tech insider stated bluntly on social media: "The alpha you can get from creating quality public AI benchmarks right now is insane — this is a massive opportunity."
This observation may seem simple, but it touches on a deep pain point in the current AI industry.
The Crisis in Current AI Evaluation Systems
Legacy Benchmarks Are Becoming Obsolete
As the capabilities of large models like GPT-4, Claude, and Gemini rapidly advance, traditional benchmarks are being "maxed out" at an unprecedented pace. On classic test sets like MMLU and HumanEval, model scores are approaching or even reaching perfect marks, rendering them unable to differentiate between models. This means the industry urgently needs new, more challenging AI evaluation standards.
MMLU (Massive Multitask Language Understanding) was introduced in 2020 by UC Berkeley and other institutions. It's a large-scale multitask language understanding test covering approximately 16,000 multiple-choice questions across 57 subject areas, ranging from elementary mathematics to professional law. HumanEval is a code generation evaluation set released by OpenAI in 2021, containing 164 programming problems. These benchmarks were considered extremely challenging at launch — MMLU's initial SOTA (State of the Art) score was only about 43%, while expert-level human performance was approximately 89.8%. However, by 2024, models like GPT-4 scored above 86% or higher on MMLU, and some models achieved pass@1 rates above 90% on HumanEval. This "ceiling effect" causes benchmarks to lose their statistical discriminative power — it's like using an elementary school exam to evaluate PhD candidates.
Lack of Evaluation Standards Creates Information Asymmetry
Without reliable public benchmarks, users cannot objectively compare the true capabilities of different models, and enterprises struggle to make informed technology selection decisions. This information asymmetry itself is a massive source of "alpha" — whoever can provide a trustworthy AI evaluation framework holds the power to shape industry narratives.
In finance, "alpha" refers to excess returns above the market average, typically derived from information advantages or unique insights. In the AI evaluation context, this alpha manifests as: those who possess reliable evaluation capabilities can identify truly excellent models and technical approaches earlier and more accurately, gaining first-mover advantages in investment, partnerships, and technology selection. The current market is flooded with self-serving "self-evaluation reports" from model vendors, lacking authoritative assessments from independent third parties — this is precisely when information asymmetry is at its most severe.
Why AI Benchmarks Represent a "Massive Startup Opportunity"
Severe Supply-Demand Imbalance
The pace of AI model releases far outstrips the update speed of evaluation systems. New models and capabilities are released every week, yet high-quality, widely recognized public benchmarks remain scarce. This supply-demand imbalance creates a clear market gap.
By rough estimates, in the first half of 2024 alone, major AI labs and open-source communities worldwide released hundreds of large language models spanning general conversation, code generation, multimodal understanding, and more. Yet the number of widely recognized next-generation benchmarks can be counted on one hand. This "model explosion, evaluation vacuum" situation has plunged the entire industry into a peculiar predicament: we have more and more AI systems, yet we're increasingly uncertain about how good they actually are.
The Leverage Effect of Influence
Once a good benchmark is adopted by the industry, its influence scales exponentially. It not only defines "what makes a good model" but also indirectly influences billions of dollars in R&D direction. Consider the impact GLUE/SuperGLUE had on NLP, or ImageNet's profound influence on computer vision — teams that create benchmarks often gain industry standing and influence far exceeding their investment.
GLUE (General Language Understanding Evaluation) and its successor SuperGLUE were jointly released in 2018 and 2019 by NYU, the University of Washington, and other institutions. They provided a unified arena for NLP research through a carefully designed set of natural language understanding tasks (such as textual entailment, sentiment analysis, coreference resolution, etc.). The GLUE leaderboard directly drove the creation of milestone models like BERT, RoBERTa, and T5 — researchers continuously innovated model architectures and training methods to achieve better leaderboard rankings. ImageNet is even more legendary — Professor Fei-Fei Li's team at Stanford began building this dataset of 14 million labeled images in 2007, and AlexNet's breakthrough performance in the 2012 ImageNet challenge (reducing error rates from 26% to 16%) is widely recognized as the starting point of the deep learning revolution. These cases demonstrate that benchmark creators, while not directly training models, profoundly shape the development trajectory of entire fields by defining the "rules of the game."
Clear Commercialization Paths
High-quality AI benchmarks can spawn multiple business models:
- Evaluation-as-a-Service: Providing standardized model evaluation for enterprises
- Custom Enterprise Evaluation: Designing proprietary test sets for specific industry scenarios
- Industry Reports and Consulting: Delivering insights based on evaluation data
LMSYS's Chatbot Arena has already demonstrated the enormous value of community-driven evaluation. LMSYS (Large Model Systems Organization) is an open-source organization founded by UC Berkeley researchers. Its Chatbot Arena employs an innovative "crowdsourced blind evaluation" mechanism: users submit questions to two anonymous models simultaneously, then vote on the better response. The system ranks models based on an Elo rating system (derived from chess rating systems). This approach elegantly solves multiple pain points of traditional benchmarks — it reflects real user preferences, updates continuously and dynamically, and is difficult to game through targeted optimization. As of 2024, Chatbot Arena has collected over one million human votes, and its rankings are widely cited by major AI labs including OpenAI, Google, and Anthropic, making it one of the de facto industry reference standards. This also proves that even without relying on traditional business models, a well-designed evaluation platform can accumulate tremendous industry influence and potential commercial value.
What Makes a "Good" Public AI Benchmark
Key Characteristics
- Contamination Resistance: Test data should not be easily covered by training sets, preventing "benchmark gaming"
- High Discriminative Power: Effectively distinguishing between models of different capability levels
- Real-World Relevance: Reflecting actual user needs rather than abstract academic tasks
- Sustainable Updates: Having dynamic update mechanisms to keep pace with model evolution
- Transparency and Openness: Open methodology, reproducible results, earning community trust
Data Contamination is one of the most severe challenges facing AI evaluation today and deserves special elaboration. Since large language models are typically trained on data crawled at scale from the internet, publicly available benchmark questions are very likely to already exist in training sets, causing models to have "seen the answers" rather than genuinely possessing problem-solving abilities. Multiple studies in 2023 revealed that some models' high scores on math tests like GSM8K may be partially attributable to data leakage. Countermeasures include: using dynamically generated questions (such as LiveBench updating its question bank monthly), maintaining private test sets, employing adversarial sample design, and detecting memorization effects through question variants. This is why "contamination resistance" is listed as the primary characteristic of quality benchmarks — a test that can be defeated by "memorizing answers" has essentially lost its evaluative meaning.
Most Needed AI Evaluation Directions
The following areas are severely underserved by existing benchmarks:
- Long-context understanding and information retrieval
- Multi-step complex reasoning
- Tool use and API calling
- Practical usability of code generation
- Multimodal fusion capabilities
- Agent task completion
These evaluation gaps reflect the critical transition of AI applications from "toy demos" to "production deployment." Long-context understanding involves a model's ability to retain information when processing inputs of 100,000 or even 1 million tokens. The existing "Needle in a Haystack" test — inserting a specific piece of information into an extremely long text and then asking the model about it — is intuitive but overly simplistic, failing to reflect real long-document analysis scenarios. Multi-step complex reasoning requires models to perform chain logical deduction rather than single-step pattern matching, which places higher demands on evaluation design: how to quantify "reasoning depth" itself is an open question. Tool use and API calling evaluation needs to measure a model's operational capabilities in real software environments — early attempts like ToolBench and API-Bank remain insufficiently mature. Agent task completion is the most cutting-edge direction — evaluating AI agents' ability to autonomously plan and execute multi-step tasks in open environments. SWE-bench (evaluating models' ability to solve real GitHub issues) and WebArena (evaluating models' ability to complete operational tasks on real websites) are exploring this space, but coverage and standardization remain far from adequate.
Implications for AI Practitioners and Entrepreneurs
For AI researchers, developers, and entrepreneurs, this signal deserves serious attention. While everyone is chasing "training bigger models," building AI evaluation infrastructure may be a differentiated and high-return path. It doesn't require hundreds of millions of dollars in compute investment, but it does demand deep understanding of AI capability boundaries and ingenious test design.
Historical experience shows that the value of the "infrastructure layer" in technology ecosystems is often severely underestimated. Just as search engines in the internet era gained enormous value by organizing information, AI-era evaluation systems have the potential to become indispensable infrastructure by organizing and quantifying model capabilities. More importantly, the entry barrier to this field is not capital-intensive — it relies more on domain expertise, creative test design, and community operations capabilities, which is precisely where small teams and independent researchers can leverage their strengths.
In the AI industry's "gold rush," those selling shovels often have the last laugh. And a good benchmark is one of the sharpest shovels of this era.
Key Takeaways
Related articles
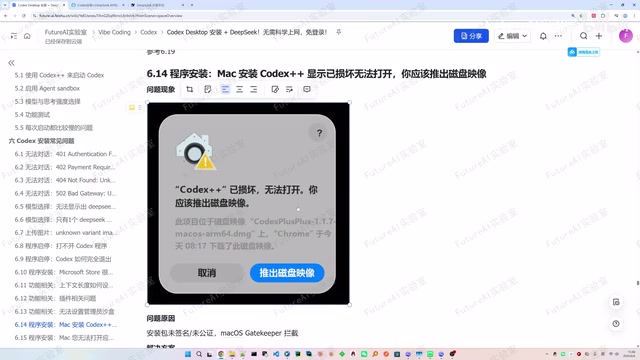
Complete Guide to Codex Installation & DeepSeek Integration Troubleshooting
Complete troubleshooting guide for Codex installation and DeepSeek API integration, covering 401/402/502 errors, model display issues, startup failures, and a universal fix.

Anthropic Sales Rep Builds AI Tools with Claude, Transforms from Account Executive to GTM Architect
Anthropic account exec Jared built Clasps, an AI email tool using Claude and RAG architecture, saving 2-3 hours daily and transforming into a GTM Architect.
v0 Snowflake Integration Enters Public Preview: Generate Data Dashboards with Natural Language
Vercel's v0 announces public preview of Snowflake integration, enabling users to connect data sources and auto-generate professional dashboards using natural language prompts.