AI Coding Efficiency: A Complete Methodology for Writing Effective Skill Specifications
A complete methodology for writing Skill specs that constrain AI Agents and boost coding accuracy.
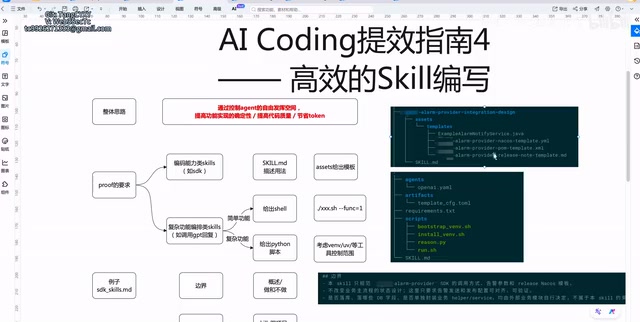
This article presents a comprehensive methodology for writing effective Skill specifications in AI-assisted programming. It covers two main Skill types — coding capability Skills using description-plus-template patterns, and complex orchestration Skills with dependency-isolated scripts — along with six core structural elements including responsibility boundaries, version management, SDK version association, trigger scenarios, frozen parameters, and validation checklists to make AI coding predictable and high-quality.
In the practice of AI-assisted programming, how do you get an AI Agent to complete coding tasks precisely instead of aimlessly "freestyling"? The answer lies in writing high-quality Skills. This is the fourth article in the AI Coding Efficiency series, focusing on the methodology for writing Skills to help you fundamentally improve AI coding accuracy, code quality, and effectively reduce Token consumption.
Core Idea: Constraining the Agent's Freestyle Space
The essence of a Skill is to define clear action boundaries for an AI Agent. In today's mainstream AI programming assistants (such as Cursor, GitHub Copilot, Devin, etc.), Agents typically generate code by reading project context and understanding user intent. But this "general understanding" mode introduces significant uncertainty — for the same requirement, the Agent might produce different implementations each time. A Skill is essentially a structured Prompt Engineering practice that organizes scattered prompts into reusable, version-controlled knowledge units, transforming the Agent's behavior from probabilistic output to deterministic execution.
There are three core goals for writing effective Skills:
- Improve accuracy of feature implementation: The AI no longer needs to guess what you want — it strictly follows the Skill's specifications.
- Improve code quality: Through templates and validation checklists, ensure the output code meets project standards.
- Save Tokens: Tokens are the basic unit of measurement for how large language models process text, and every API call consumes input and output Tokens. While current mainstream models (such as GPT-4, Claude, etc.) have expanded their context windows to 128K or even larger, Token consumption directly correlates with API call costs, and overly long contexts cause "attention dilution" — meaning the model may overlook critical details in a sea of information. By pre-organizing precise contextual information through Skills, the AI doesn't need to scan the entire project to understand context; it simply completes the task according to the Skill's requirements, reducing costs while improving output quality.
Put simply, the better the Skill is written, the less room the Agent has to "improvise," and the more controllable and stable the final output becomes.
Coding Capability Skills: Combining Usage Descriptions with Code Templates
The first common type of Skill is the coding capability Skill, with typical scenarios like SDK integration. The best practice for this type is: The Skill itself describes usage, provides code templates through Assets, and then tells the Agent how to modify and use those templates.
Here it's important to understand the role of Assets in the Skill system: Assets are the static resource layer in the Skill system, typically existing as files in the project repository. They form a "declaration + implementation" separation architecture with Skill description files — the Skill description file (e.g., skill.md) tells the Agent "what to do" and "how to do it," while Assets provide concrete code templates, configuration snippets, and reference implementations. This separation design draws from the classic software engineering principle of "separating interface from implementation," making Skill maintenance and upgrades more flexible.
Here's a concrete example — a Skill for integrating a Java service with a particular SDK. Its Assets typically contain the following template files:
- Java code template: The code skeleton for core integration logic
- Configuration modification template: Such as Maven dependency configurations
- Form reference template: Standard patterns for frontend Forms
- Release Note template: Format for version update notes
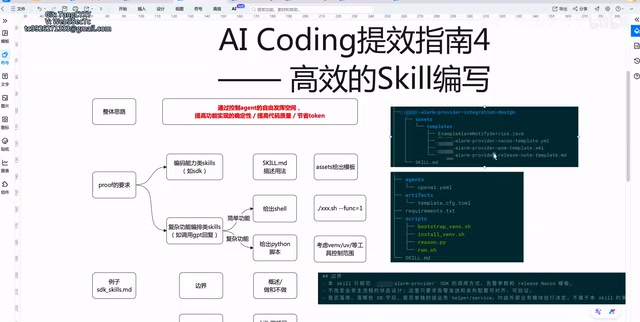
The benefits of this approach are obvious: when a service needs to integrate with an external SDK, the Agent simply copies and modifies the templates — there's no need to deeply read API design documentation. Templates are the specification, usage patterns are the constraints — this is the core design philosophy for coding-type Skills.
Complex Feature Orchestration Skills: Choosing Between Shell and Python Scripts
The second type is complex feature orchestration Skills, such as dispatching external AI Agents for response processing. These scenarios require choosing different implementation strategies based on complexity.
Simple Scenarios: Use Shell Scripts Directly
If the functional logic is fairly straightforward, a single Shell script is sufficient. For example, calling an external service, passing in parameters, and getting results — wrap it in Shell, and the Skill simply states "execute this Shell script."
Complex Scenarios: Use Python Scripts for Fine-Grained Control
When functionality involves state synchronization, multi-step requests, and other complex logic, Python scripts are needed for more fine-grained control.
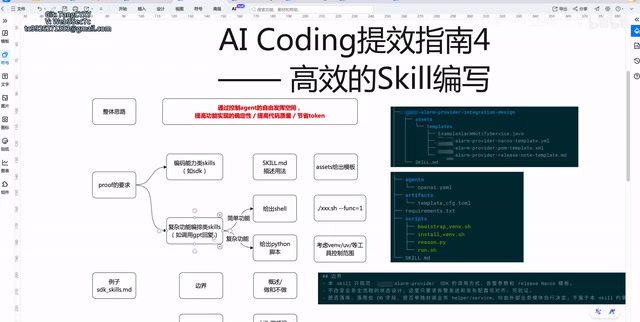
But there's a key issue that's easily overlooked: dependency isolation. Python's dependency management has always been a pain point in engineering practice. If the Agent calling this Skill is itself a Python project, the dependency versions in the Skill's Python scripts might conflict with the project's dependency versions. For example, the Python script executed by the Agent might depend on requests 2.31, while the host project might be locked to requests 2.28 — version incompatibility leads to runtime errors that are difficult to debug.
The solution is to use tools like venv or uv for virtual environment isolation. venv is a built-in virtual environment tool since Python 3.3+ that creates independent package installation directories for each project; uv is a next-generation Python package management tool from the Astral team (the developers of Ruff), written in Rust, with installation speeds 10-100x faster than pip — particularly suited for CI/CD and Agent scenarios that require frequent environment creation and teardown. Through virtual environment isolation, you ensure that the Skill's dependencies don't pollute the project's own dependencies.
A typical implementation structure looks like this:
- Core functionality is implemented through Python scripts
- The run entry point is wrapped in a
runner.shthat handles environment checks, dependency installation, and script startup - If the virtual environment doesn't exist, the Shell script automatically creates it and installs dependencies, achieving complete isolation from the project environment
Standardized Skill Structure: Six Core Elements
A high-quality Skill should contain the following six core elements:
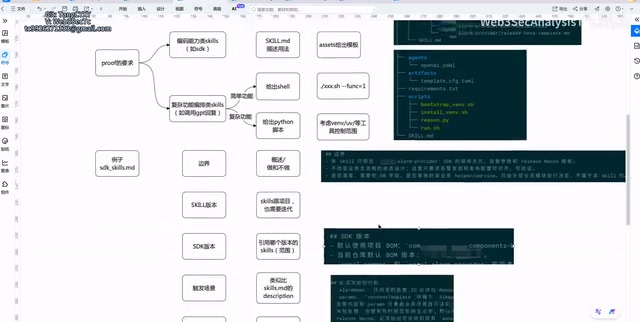
1. Clear Responsibility Boundaries: What to Do and What Not to Do
A Skill must clearly define its scope of responsibility — it does this one thing and nothing else. This aligns with the Prompt Engineering principle of "providing positive and negative examples to the Agent." In Prompt Engineering research, explicitly telling the model "what not to do" is often more effective than only saying "what to do," because large language models tend to over-generalize — when instructions have ambiguous areas, the model will "fill in the blanks" based on statistical patterns from training data, and this gap-filling often deviates from the developer's true intent. Clear boundaries effectively prevent the Agent from over-diverging.
2. Skill Version Management
Skills aren't static — they need version management. Different projects (Java projects, Go projects, frontend projects) use different Skills, and each Skill is continuously upgraded through iterations. Version numbers are written in the Meta information for easy tracking and management. This aligns with the Semantic Versioning concept in software engineering: major version numbers indicate incompatible changes, minor version numbers indicate backward-compatible feature additions, and patch numbers indicate backward-compatible bug fixes.
3. SDK Version Association
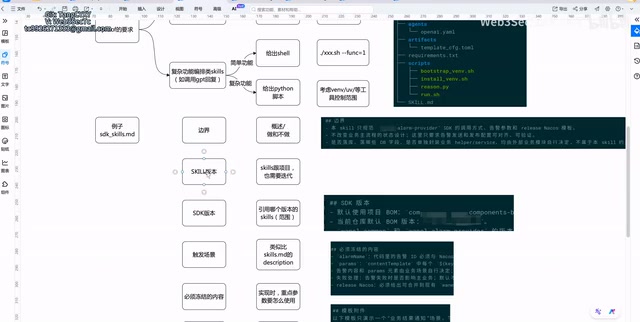
If a Skill serves a particular SDK, there's an association between the Skill version and the SDK version:
- SDK major version upgrade → The Skill also needs a major version upgrade (both versions bump in sync)
- SDK minor feature upgrade → Only a minor Skill version update is needed; the Skill's major version number stays the same
This version correspondence needs to be clearly documented. This dual-version linkage mechanism is critically important in practice: when an SDK undergoes a Breaking Change, old Skill templates might generate code that can't compile or run. Without a version association mechanism, the Agent might use old templates to integrate with a new SDK, producing compatibility issues that are extremely difficult to troubleshoot.
4. Trigger Scenario Description
Similar to the description field in skill.md, this explains under what scenarios the Skill should be triggered. This is the basis for the Agent to decide whether to use the Skill. The quality of trigger scenario descriptions directly affects the Skill's recall rate and precision — descriptions that are too broad cause the Skill to be falsely triggered, while descriptions that are too narrow may result in the Skill not being invoked when needed. Good trigger descriptions should include specific keywords, typical user intent expressions, and explicit exclusion conditions.
5. Frozen Content and Parameter Descriptions
For core parameters in a Skill that must not be modified (such as alarm names and their params), the Skill description needs to detail their usage and constraints to ensure the Agent doesn't arbitrarily alter critical configurations. This design stems from a deep understanding of large language model behavior: models have a tendency toward "creative rewriting" when generating code — even constants, enum values, or configuration items that should remain unchanged may be "optimized" by the model based on contextual semantics. By explicitly marking frozen content, you're essentially setting a "read-only lock" for the Agent.
6. Validation Checklist
This is the last line of defense for ensuring code quality. The design philosophy of validation checklists comes from the aviation industry's Checklist culture — pilots must go through a checklist item by item before every takeoff, even seasoned veterans. In AI coding scenarios, large language models have a "Hallucination" problem, potentially generating code that looks reasonable but contains logical errors. By embedding validation checklists in Skills, you're essentially adding a "self-check step" for the Agent, having the model perform structured self-review before outputting the final result. This is consistent with the core idea of Chain-of-Thought prompting — guiding the model through step-by-step reasoning rather than jumping directly to an answer.
For AI Agents to write high-quality code, they must have self-verification capabilities. While the Skill level may not achieve very rigorous automated testing, it should at least include basic consistency checks:
- Whether Java code configurations are consistent with frontend configurations
- Whether the Release Note matches the actual changes
- Whether cross-references between template files are correct
Summary
Writing effective Skills is essentially behavioral design for AI Agents. Through coding-type Skills with "descriptions + templates," orchestration-type Skills with dependency isolation, and standardized structures containing responsibility boundaries, version management, and validation checklists, we can effectively constrain Agent behavior and transform AI coding from "hoping for the best" to "predictable outcomes."
The underlying logic of this methodology is highly consistent with the "Convention over Configuration" principle in software engineering: rather than letting each developer (or Agent) decide how to implement things on their own, it's better to unify behavior through preset conventions and templates. In the context of AI programming, Skills are the carriers of these conventions — they codify the team's engineering experience, coding standards, and best practices, enabling AI Agents to produce output efficiently according to team standards, much like a well-trained new team member.
Remember this core principle: The less freedom the Agent has, the more deterministic its output becomes. Good Skills don't limit AI's capabilities — they channel AI's capabilities precisely in the right direction.
Related articles
PiDeck 0.5.0 Released: Ten Versions in One Week, a Complete Overhaul of the Desktop AI Agent
PiDeck 0.5.0 completes the rebrand from PiDesktop, shipping 10 versions with ~100 changes in one week: design system overhaul, dark mode, LAN sharing, Git integration, and dual-layer proxy config.
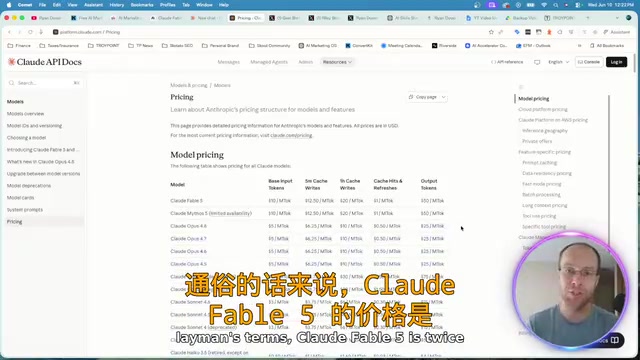
Claude Fable 5 Hands-On Review: Double the Price — Is It Worth It?
Hands-on comparison of Claude Fable 5 vs Opus 4.8 on landing page design and website rebuilds. Detailed API pricing analysis and practical advice on whether double the cost delivers double the value.

Introduction to AI Literacy: How Teachers Can Build a Systematic Cognitive Framework
A teacher's guide to AI literacy: from AI history and LLM fundamentals to the Agent era, build a systematic cognitive framework and master tool selection strategies.