AI Coding Gone Wrong: 4 Models Generated Files to the Exact Same Path
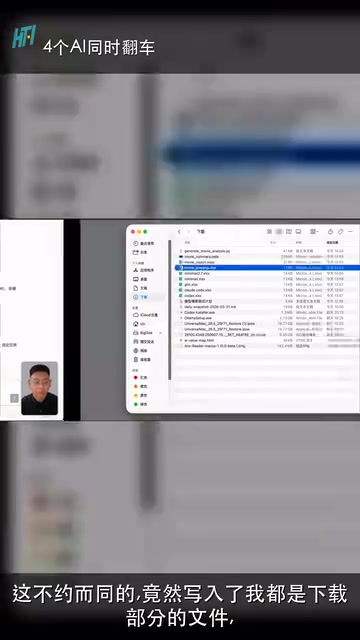
Four AI coding models generated files to the same path, overwriting each other in a multi-model test.
A developer tested four AI models — Claude Code, Codex, DeepSeek, and MiniMax — simultaneously for file generation, only to discover all four wrote to the exact same default path, overwriting each other's output. The fix required manually assigning separate directories to each model. The incident highlights critical gaps in multi-model isolation, default path diversity, and model stability in current AI coding tools.
An Unexpected AI Coding Disaster
As AI coding tools become increasingly mainstream, more and more developers are experimenting with running multiple AI models simultaneously to compare their capabilities. In recent years, AI coding tools like GitHub Copilot, Cursor, Claude Code, and OpenAI Codex have risen rapidly, and developers have shifted from asking "should I use AI-assisted coding?" to "which AI models should I use at the same time?" Multi-Model Benchmarking has become a popular practice in the tech community, with the core goal of having different models execute the same task to compare code quality, execution speed, context comprehension, and other dimensions. However, this parallel testing approach also introduces resource contention problems that don't exist in traditional single-model usage.
A Bilibili content creator encountered a hilariously frustrating disaster during real-world testing — four AI models, when generating files, all wrote to the exact same path without any coordination, overwriting each other in what can only be described as a classic "four riders on one horse" scenario.
What Happened: Four AI Models "Coincidentally" Collided on the Same Path
The creator was simultaneously using four different AI models to generate files: Claude Code, Codex, DeepSeek (Deep Thick), and MiniMax. The expectation was that each model would generate independent files without interfering with one another.
Reality, however, had other plans: all four models wrote their output to the exact same file in the same download directory. Each subsequent file overwrote the previous one, leaving only the output from the last model to finish.
From a technical perspective, this is essentially a classic Race Condition problem. At the operating system level, when multiple processes write to the same file path simultaneously, later writes overwrite earlier ones. This happens because most file systems default to "truncate write" mode rather than "append write" mode. When AI models generate files, they typically choose output locations based on the most common path patterns in their training data — such as the user's download directory (~/Downloads) or the current working directory (./output). This makes it extremely likely that different models will choose the same path when no explicit instructions are given.
The creator's description was spot-on: "It's like four people riding the same horse, and each one thinks the horse belongs to them." This analogy perfectly captures how AI models behave without context isolation — they each run independently, completely unaware of the other models' existence, yet happen to choose the same default path.
The Fix: Manually Assigning Independent Paths to Each Model
After discovering the problem, the creator had to start over. This time, they manually specified different output paths for each model to prevent file overwrites:
- Claude Code →
Cloud Movie - Codex →
Codex Movie - DeepSeek →
Deep Thick Movie - MiniMax →
MiniMax Movie - GLM →
GLM Movie
With explicit path isolation, each model could finally work independently within its own "territory" without interfering with the others. While this manual isolation approach is effective, it also exposes a shortcoming in current AI coding tools from an engineering standpoint — ideally, the tools themselves should provide automated sandbox isolation mechanisms rather than relying on users to manually assign paths.
Significant Performance Differences Across AI Models
After fixing the path issue, the models showed notably different performance characteristics.
DeepSeek: Speed Champion Among Free Models
As a free model, DeepSeek was the first to complete the file generation task, delivering impressive speed. DeepSeek is a large language model series developed by DeepSeek (深度求索), with versions like DeepSeek-Coder and DeepSeek-V3 standing out in code generation. As a flagship Chinese open-source model, DeepSeek has gained widespread attention in the developer community for being free to use, fast at inference, and strong in Chinese language comprehension. Its MoE (Mixture of Experts) architecture allows the model to maintain a large parameter count while only activating a subset of parameters during inference, achieving high efficiency. For a free AI coding model, this level of performance is commendable.
MiniMax: Crashed Mid-Task Without Completing
MiniMax's performance was disappointing. It output a large amount of English content before abruptly stopping, essentially failing to complete the task at all. This kind of mid-task crash is extremely costly in real development scenarios, as it forces developers to spend extra time debugging and retrying. AI model task interruptions can be caused by multiple factors, including Context Window Overflow — where the total token count of input and output exceeds the model's maximum processing capacity — API call timeouts, or connection drops due to server-side overload. For workflows that require end-to-end automation, this kind of unpredictability is fatal, as a single failure can force the entire pipeline to roll back and restart.
Three Takeaways for Developers from This Disaster
This seemingly comical incident actually exposes several critical issues with current AI coding tools in multi-model parallel scenarios.
1. AI Models Lack Randomness in Default Paths
Multiple AI models, when given no explicit instructions, tend to choose the same default output path. This indicates that most models share highly similar training data and behavioral patterns when it comes to file operations, lacking differentiated path generation strategies. Fundamentally, this reflects the homogeneity problem in current LLM training data — regardless of which company built the model, the code examples related to file operations in their training corpora largely come from the same open-source projects and technical documentation, so the "default behaviors" the models learn converge as well.
2. Multi-Agent Collaboration Requires Explicit Isolation
When running multiple AI Agents simultaneously, resource isolation must be established at the task assignment stage, including but not limited to file paths, port numbers, and temporary directories. You cannot assume that AI will automatically handle conflicts.
Multi-Agent Collaboration is a major direction in current AI application architecture. From AutoGPT to CrewAI, from MetaGPT to OpenAI's Swarm framework, the industry is actively exploring best practices for coordinating multiple AI Agents. However, resource isolation between Agents remains an insufficiently solved engineering problem. In traditional software engineering, similar issues are addressed through containerization (e.g., Docker), Namespace Isolation, Sandboxing, and other techniques. But most current AI coding tools don't have these isolation mechanisms built in — Agents share the same file system and runtime environment, making conflicts virtually inevitable. In the future, we'll likely see more orchestration tools specifically designed for multi-Agent scenarios, with resource isolation as a default configuration rather than an optional feature.
3. Model Stability Remains a Critical Weakness
MiniMax's mid-task crash reminds us that an AI model's task completion rate and output stability are still crucial metrics for evaluating practical usability. Being fast but unable to finish is worse than being slow but delivering reliably.
The industry currently over-relies on benchmark scores — such as HumanEval, MBPP, and SWE-bench — to evaluate model capabilities. These tests primarily measure code generation accuracy under ideal conditions but rarely examine model stability under long-running tasks, large-scale outputs, or complex real-world contexts. The industry is addressing stability issues through strategies like Retry Mechanisms, Checkpoint Recovery, and Task Sharding, but these are all "patch-style" solutions. Fundamental improvements will need to come from the model architecture and inference engine levels.
Conclusion
While this "four AIs colliding on the same path" incident is equal parts funny and frustrating, it genuinely reflects the pain points of current AI coding tools in real-world usage. As multi-model parallelism and multi-Agent collaboration become the norm, designing better isolation mechanisms and conflict resolution strategies will be a key challenge that AI coding tools must address next.
From a broader perspective, this incident also highlights the engineering gap that AI tools must bridge on their journey from "toy" to "productivity tool." Academia focuses on how many points a model can score on benchmarks, but what truly matters in engineering practice is whether a model can run stably in complex, concurrent, and unpredictable real-world environments. For developers, while enjoying the convenience that AI coding brings, it's important to have fallback plans ready — after all, no matter how smart AI gets, sometimes it still makes embarrassingly basic mistakes.
Related articles
Mistral Le Chat Image Generation Review: Can It Replace Fable?
Mistral AI launches image generation in Le Chat, dubbed Le Chaton Fat. We analyze its capabilities, compare it with Fable, and explore the trend of AI chat platforms integrating image generation.
Testing DeepSeek's Safety Mechanisms: Multiple Jailbreak Attempts Successfully Blocked
An overseas security blogger systematically tested DeepSeek's jailbreak resistance using direct requests, rephrased prompts, and varied strategies. Results show robust intent recognition, consistent blocking, and context-aware safety mechanisms.
A Middle Schooler with Zero Coding Skills Built a Story-Driven Game with AI: Creativity Unshackled from Technical Barriers
A middle schooler with no coding experience used AI to build an interactive story game with branching choices and surreal alien adventures. We explore what this means for creative democratization.