AI Coding Showdown: Four Major Models Show Shocking Performance Gaps on a Dynamic Web Scraping Task
Dynamic web scraping test reveals stark coding ability gaps among four leading AI models.
A real-world Baidu dynamic web scraping challenge tested ChatGPT 5.4, Gemini 3.1, DeepSeek V4 Pro, and Kimi 5.1. All four failed initially, but ChatGPT decisively switched to browser simulation and finished first with clean output. DeepSeek succeeded after multiple iterations but with messier results. Gemini and Kimi both failed entirely, unable to escape ineffective strategies — revealing that real engineering tasks expose far greater AI coding gaps than benchmarks suggest.
Test Background: The Hardcore Challenge of Dynamic Web Scraping
In evaluating AI coding capabilities, dynamic web scraping has always been a highly differentiating test. It not only challenges a model's code generation ability but also involves handling anti-scraping mechanisms, browser simulation, asynchronous loading, and many other technical hurdles. In episode 20 of their arena series, Bilibili creator "IR Programming" pitted four mainstream AI models against each other using a Baidu dynamic web scraping task.
To understand the difficulty of this task, you first need to grasp the fundamental difference between dynamic and static web pages. Static web pages have their HTML content fully generated on the server side — a crawler only needs to send a single HTTP GET request to retrieve everything. Dynamic web pages (like Baidu search results), however, rely heavily on JavaScript executing in the client browser to render the final content. This means traditional Python libraries like requests can only retrieve a nearly blank HTML skeleton. To make matters worse, major platforms like Baidu deploy multiple layers of anti-scraping mechanisms, including User-Agent detection, Cookie verification, request rate limiting, JavaScript challenges (such as generating dynamic tokens), and CAPTCHA triggers. The combination of these mechanisms makes dynamic web scraping a highly complex engineering problem that requires knowledge spanning network protocols, browser rendering principles, and anti-scraping countermeasures.
The four contestants were: ChatGPT 5.4, Gemini 3.1, DeepSeek V4 Pro, and Kimi 5.1. DeepSeek and Kimi used Solid mode (autonomously completing the entire workflow), while ChatGPT and Gemini operated through standard interactive mode. It's worth explaining the difference between these two modes: Solid mode is a testing approach where the AI model independently handles everything from requirements analysis, solution design, and code writing to debugging and execution — without any human intervention or prompting. This is closer to how an AI Agent works, where the model must assess the current state, decide the next action, handle errors, and iterate on its own. Standard interactive mode allows for some degree of guidance through conversation. Solid mode places much higher demands on a model's autonomous reasoning and planning capabilities, as the model must independently close the entire problem-solving loop. The core requirement was straightforward — given a Baidu dynamic web page, have the AI autonomously choose a technical approach, write the scraping code, successfully extract the page content, and output the results.
Round One: All Four Models Fail Completely
Once testing began, all four models quickly jumped into code writing, with decent response times across the board. However, the first round's results were unexpected — all four models failed.
Kimi 5.1 was the first to finish its code output, but it threw errors immediately upon execution. Gemini 3.1's interface also showed request failures. DeepSeek and ChatGPT were still running, but they too failed to succeed in the first round. This confirmed that Baidu's dynamic web anti-scraping mechanisms are genuinely formidable — simple request approaches simply can't break through. All four models most likely used the most straightforward HTTP request approach in the first round (such as Python's requests or urllib libraries), and Baidu's front-end anti-scraping strategy checks request headers, Cookie status, and JavaScript execution environment. Missing any single element results in the request being blocked or returning empty content.
The critical difference lay in what came next — each model's self-recovery ability. When facing failure, who could adjust strategies and iterate on solutions faster is what truly separated the contenders.
ChatGPT 5.4: Decisive Strategy Switch, First to Pass
After the first-round failure, ChatGPT 5.4 demonstrated impressive autonomous debugging capabilities. It quickly recognized that standard HTTP requests couldn't bypass the anti-scraping mechanisms and decisively switched to a browser simulation approach (choosing browser automation tools like Selenium) to load dynamic page content by mimicking real browser behavior.
There's clear technical logic behind this strategy switch. The core principle of browser automation tools like Selenium is launching a real browser instance (such as Chrome or Firefox) and controlling it programmatically through the WebDriver protocol. Unlike sending HTTP requests directly, Selenium fully executes JavaScript code on the page, waits for Ajax asynchronous requests to complete, and ultimately retrieves rendered results identical to what a human user would see in their browser. Beyond Selenium, other mainstream browser automation solutions include Microsoft's Playwright (which supports multiple browsers with better performance) and Google's Puppeteer (focused on Chrome control). These tools also support Headless Mode — running without displaying the browser interface, making them suitable for server-side deployment. ChatGPT's choice of browser simulation meant it correctly identified the essence of the problem — this wasn't about tweaking HTTP request parameters, but about needing a complete browser environment to execute JavaScript and bypass front-end anti-scraping detection.
After automated debugging and test runs, ChatGPT 5.4 was the first to declare success. The creator opened the output directory to verify that the scraped data was completely correct. A second verification was then performed using a different keyword, "泰山" (Mount Tai), which also successfully returned correct results.
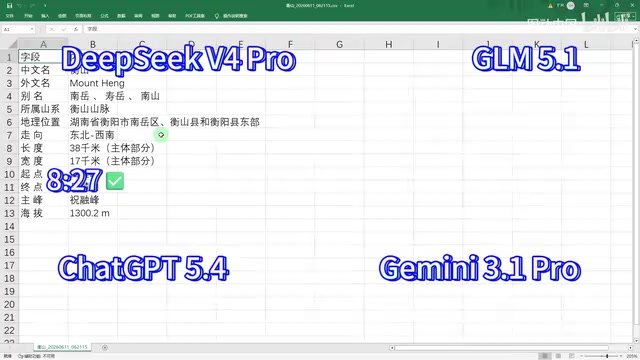
What you might not have noticed is that ChatGPT 5.4's output data was remarkably clean and well-organized, with no redundant information — code quality clearly superior to the other contestants. This reflects not just its coding ability, but also its maturity in engineering practice.
DeepSeek V4 Pro: A Winding Path to Success
DeepSeek V4 Pro's journey was far more tortuous. It went through multiple iterations, still debugging by its third and fourth versions. However, DeepSeek's strength lay in its persistent iteration capability — after each failure, it could analyze the cause and try a new strategy.
This self-debugging ability is an important research direction in large language models in recent years. It requires the model not only to generate code but also to understand runtime error messages (such as stack traces, HTTP status codes, timeout exceptions), locate root causes, and generate fixes. This process is essentially a "generate-execute-feedback-correct" closed-loop reasoning chain, closely related to the ReAct (Reasoning + Acting) framework in academia — where the model alternates between reasoning and taking action, continuously adjusting its strategy based on environmental feedback. DeepSeek V4 Pro demonstrated exactly this closed-loop reasoning ability across multiple iterations. While its convergence speed was slower than ChatGPT's, it consistently moved toward the correct solution.
Ultimately, after multiple rounds of automated testing, DeepSeek V4 Pro also successfully completed the scraping task. However, compared to ChatGPT, its output contained some redundant data, with data cleanliness falling short. When the creator tested with other keywords, DeepSeek could also scrape successfully and wasn't slow, but the extraneous information issue persisted.
Overall, while DeepSeek V4 Pro took longer and produced slightly lower-quality output, its ability to ultimately complete this high-difficulty task as a Chinese-developed model is commendable.
Gemini 3.1 and Kimi 5.1: Stuck in the Mud
Compared to the first two contestants' success, Gemini 3.1 and Kimi 5.1's performance was disappointing.
Kimi 5.1's code grew increasingly complex after multiple attempts, but it never found an effective way to break through the anti-scraping defenses. Gemini 3.1 fell into a similar trap — it spent considerable time analyzing the web page structure and even added complex processes like end-to-end testing, but the core problem remained unsolved.
From a technical perspective, these two models' failures exposed their shortcomings in error attribution and strategy search space exploration. They likely kept making minor adjustments in the same wrong direction — such as repeatedly tweaking HTTP request headers, trying different Cookie strategies, or adding more complex parsing logic — without being able to break out of the local optimum like ChatGPT did and make a global strategy switch (from HTTP requests to browser simulation). This trap of "refining in the wrong direction" is extremely common in real software development, where developers sometimes invest too much time in an infeasible technical approach while overlooking the need for a more fundamental change in strategy.
After waiting beyond the allotted time, the creator ultimately ruled that both models had failed. It's worth noting that the creator had originally expected all four models to complete the task successfully, with differences only in timing — but the actual performance gap far exceeded expectations.
Where the Core Differences in AI Coding Ability Lie
From this dynamic web scraping test, several key dimensions of AI coding ability can be distilled:
Strategy Selection
When facing anti-scraping failures, ChatGPT 5.4 could quickly identify the root cause and switch to a browser simulation approach. This technical decision-making ability is the most critical differentiator. Meanwhile, Gemini and Kimi went further and further down the wrong path, trapped in cycles of ineffective iteration. In software engineering, this capability corresponds to architecture-level judgment — knowing when to "take a different road" rather than repeatedly hitting the same dead end.
Self-Debugging and Iteration
Although DeepSeek V4 Pro went through four versions of iteration, it improved with each attempt and ultimately succeeded. This kind of persistent optimization resilience is extremely important in real-world development. By contrast, Gemini and Kimi's iteration efficiency was clearly insufficient, unable to converge on the correct solution within the given time.
Code Quality and Engineering Maturity
Even among those that completed the task, ChatGPT's output code was cleaner and its data more polished, reflecting higher engineering maturity. In real projects, this translates to lower maintenance costs and better readability. Good engineering code doesn't just need to "work" — it must also consider comprehensive exception handling, standardized output formatting, and code maintainability. These details often determine whether a solution can evolve from prototype to production.
The AI Coding Landscape Is Diverging Rapidly
The final ranking from this test was: ChatGPT 5.4 (1st) > DeepSeek V4 Pro (2nd) > Gemini 3.1 / Kimi 5.1 (Failed).
The creator also mentioned that this result mirrors what happened when Claude participated in earlier tests — Claude was similarly "far ahead" at the time. This suggests that on complex coding tasks, the gap between top-tier models is widening, not narrowing.
Of course, it's worth mentioning that Gemini and Kimi may not have been running their latest versions, while ChatGPT 5.4 had already gone through updates and iterations. Regardless, this real-world test once again proves: in actual engineering scenarios, the differences in AI models' coding abilities are far greater than what benchmark scores suggest. Current mainstream code capability benchmarks like HumanEval, MBPP, and SWE-bench primarily evaluate function-level code generation or standardized bug-fixing abilities. However, real engineering scenarios involve technology selection, environment configuration, third-party library usage, error handling, data cleaning, and many other dimensions that are difficult to adequately cover in standard benchmarks. This is why the industry increasingly values "Real-World Evaluation" — measuring model capabilities through actual project tasks rather than artificially constructed problems. Tasks like dynamic web scraping that involve external environment interaction and anti-scraping countermeasures remain areas that existing benchmarks struggle to standardize.
For developers, choosing the right AI coding assistant still requires validation through real tasks — you can't rely solely on benchmark leaderboards.
Related articles
AI Large Model Learning Roadmap Breakdown: Three Stages from Application Development to Model Fine-Tuning
Deep breakdown of a popular AI large model learning roadmap covering LangChain, RAG, Agent, and LoRA fine-tuning across three stages, with analysis of its strengths and limitations for career changers.

AI Agent Development: A Complete 6-Week Systematic Learning Roadmap
A 6-week systematic learning roadmap for AI Agent development, covering core architecture, ReAct principles, multi-agent collaboration, RAG integration, and deployment.
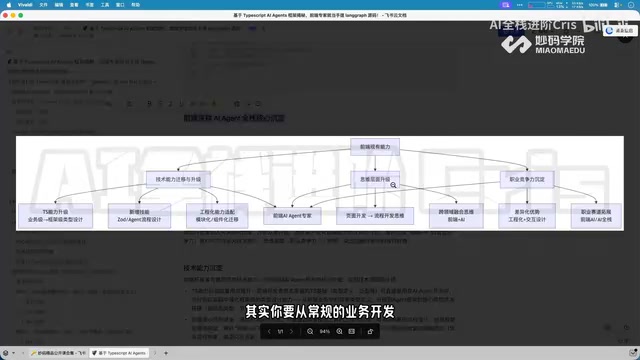
Four Core Advantages Frontend Developers Have When Transitioning to AI Agent Development
Frontend developers have key advantages for AI Agent development: TypeScript ecosystem fit, low-barrier full-stack bridging, and state management isomorphism. Learn the transition path here.