AI Large Language Models Explained: Transformer Architecture & Practical Testing Guide
A comprehensive guide to Transformer architecture, LLM principles, and AI application testing strategies.
This article systematically explains AI large language models from the ground up—covering the technical lineage from AI to LLMs, the Transformer architecture and its probability-based inference mechanism, and the strengths and weaknesses that stem from this probabilistic nature. It then explores practical applications for testers, including using AI for requirements review and test case design, as well as new challenges in testing AI-powered applications such as output non-determinism, quality evaluation, and safety compliance.
How Close Are AI Large Models to Our Daily Work?
Many people assume AI large models are some unreachable high-tech concept that requires specialized courses or specific job roles to use. In reality, if you can type a text message, you can use an AI large model. Just sign up for an account, and you can use it to generate test cases, review requirements, and assist with design plans.
This article provides a systematic overview covering the basic concepts of AI large models, their core principles, strengths and weaknesses analysis, and how testers can tackle AI application testing. Whether you're a test engineer, developer, or technical manager, you'll gain a practical cognitive framework from this guide.
What Exactly Are AI Large Models?
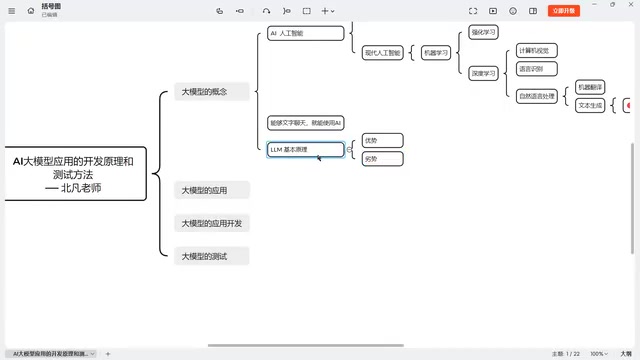
The Technical Lineage from Artificial Intelligence to Large Language Models
The term "AI large model" is actually not very precise. To truly understand it, we need to first clarify the technical hierarchy:
- Artificial Intelligence (AI): The top-level concept, encompassing all technologies that enable machines to simulate human intelligence
- Machine Learning: The primary implementation path for modern AI
- Deep Learning: An important branch within machine learning
- Large Language Models (LLMs): A specific application of deep learning in the field of natural language processing
The core idea of machine learning is to let computers automatically learn patterns from data, rather than having programmers manually write every rule. Deep learning is the branch of machine learning that uses multi-layer neural networks, whose structure is inspired by the way neurons connect in the human brain. The more layers and parameters, the "deeper" the model, and the stronger its ability to handle complex patterns. Large language models are called "large" precisely because they have tens of billions or even trillions of parameters and are trained on internet-scale volumes of text data.
The tools we use daily—DeepSeek, ChatGPT, Gemini—in the narrow sense, are large language models (LLMs). They don't represent the entirety of artificial intelligence, but rather a very specific technical direction within AI.
Three Mature AI Application Domains
Currently, there are three main domains where AI applications are relatively mature:
- Computer Vision (CV): Understanding and processing images and graphics—such as TikTok's beauty filters, automatic face slimming, and smart makeup effects
- Automatic Speech Recognition (ASR): Understanding spoken content—such as smart speakers, speech-to-text, and even budget smart voice-controlled lights
- Natural Language Processing (NLP): Understanding and generating textual meaning—this is exactly the domain where large language models operate
Each of these three domains has gone through a long journey of technological evolution. The maturity of computer vision owes much to breakthroughs in Convolutional Neural Networks (CNNs)—in 2012, AlexNet dramatically outperformed traditional methods in the ImageNet competition, marking the rise of deep learning in image recognition. Speech recognition evolved from Hidden Markov Models (HMM) to Recurrent Neural Networks (RNN) to end-to-end models, and Apple's launch of Siri in 2011 gave ordinary users their first large-scale exposure to voice AI. Natural language processing was long considered one of the hardest domains for AI to crack, because human language is full of ambiguity, metaphor, and cultural context—it wasn't until the emergence of the Transformer architecture that a qualitative leap was achieved.
Computer vision and speech recognition have actually been quite mature for a long time, but they share a common problem—they're not convenient for ordinary people to use directly. Visual AI can recognize image content, but ultimately still needs to communicate results to you through text; no matter how powerful voice AI is, cross-language communication barriers still exist.
It wasn't until large language models matured that everyone could interact with AI through the most natural method—typing a chat message—which truly lowered the barrier to using AI. So the AI explosion didn't happen overnight; it was the concentrated release of years of accumulated technological progress.
Transformer: The Core Architecture Behind Large Models
Understanding Transformer Architecture Through Translation Tasks
The Transformer is the core architecture of large language models. It was originally proposed by Google to solve machine translation problems. Its workflow can be simplified into three steps: Input → Model Processing → Output.
The Transformer architecture was first introduced in 2017 by a Google team in the paper Attention Is All You Need. Before this, processing sequential data (such as text) mainly relied on Recurrent Neural Networks (RNN) and Long Short-Term Memory networks (LSTM), but they had a fatal flaw—they had to process words one at a time and couldn't compute in parallel, making training extremely slow. The Self-Attention mechanism introduced by Transformer completely solved this problem by allowing the model to simultaneously attend to information at all positions in the input sequence and automatically determine which word relationships are more important. For example, when processing the sentence "The bank of the river was very steep," the attention mechanism can identify that "river" and "steep" have a stronger semantic connection, thereby correctly understanding that "bank" here refers to a riverbank rather than a financial institution.
Taking the translation of "I love you" as an example:
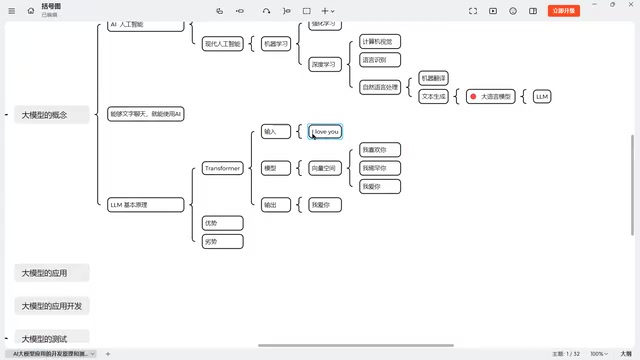
- Encoding Stage: The input English characters are encoded into mathematical vectors, entering a high-dimensional "vector space"
- Computation Stage: The model searches for semantically similar content in the vector space—various expressions like "我爱你" (I love you), "我喜欢你" (I like you), "我稀罕你" (I adore you), "我中意你" (I fancy you) are all semantically close to "I love you" and therefore occupy nearby positions in the vector space
- Decoding Stage: Through probability calculations, the model selects the most likely output character by character. For instance, the first character "我" (I) might have roughly equal probabilities among candidates, but by the second character, "爱" (love) has a significantly higher probability than alternatives, ultimately producing "我爱你"
The Essence of Large Models: Probability-Based Inference
Understanding the process above, we've grasped the most fundamental nature of large models—their output is probabilistic, not deterministic.
The core task during a large model's training phase is actually very simple—predicting the next word. Given the first half of a text passage, the model needs to guess what word is most likely to come next. By repeatedly performing this prediction training across trillions of words of text, the model gradually masters language grammar structures, factual knowledge, and even reasoning abilities. This training approach is called "autoregressive language modeling." Notably, there's a key parameter called "Temperature" when the model generates responses: the lower the temperature, the more the model tends to choose the highest-probability word, producing more stable but conservative output; the higher the temperature, the more willing the model is to choose lower-probability words, producing more creative but less controllable output. This is why the same question sometimes gets a rigorous answer and other times gets a wildly imaginative one.
This means:
- Ask the same question 100 times, and you might get 100 different answers
- It doesn't retrieve exact answers from a database; instead, it "infers" the most reasonable next word based on probability
- Every conversation is a completely new probability computation process
This fundamental characteristic directly determines the strengths and weaknesses of large models.
Strengths and Weaknesses of Large Models
Strengths: Creativity and Diversity
Precisely because of their probabilistic nature, large models excel in the following scenarios:
- Creative Writing: Generated content varies each time, naturally possessing creativity and diversity
- Conversational Interaction: Responses are rich and varied, never as monotonous as fixed scripts
- Divergent Thinking: Can examine problems from different angles, offering unexpected perspectives
Weaknesses: Lack of Precision and Authority
Also because of their probabilistic nature, large models have obvious shortcomings in the following scenarios:
- Precise Computation: For solving complex equations, a calculator is far more reliable—this fundamentally isn't what LLMs are good at
- Authoritative Accurate Answers: In fields like medical diagnosis, legal consultation, and financial accounting where errors are unacceptable, large models can only provide reference suggestions, not serve as the final authority
- Code Debugging: In debugging scenarios, AI tends to go down rabbit holes, straying further and further in the wrong direction
How Should Testers Approach AI Application Testing?
Best Use Cases for AI in Testing Work
For testers, the probabilistic nature of large models is actually an advantage:
- Requirements Review: AI can examine requirement documents from multiple angles, discovering boundary conditions and edge cases that humans easily overlook
- Test Case Design: Testing inherently requires considering "all sorts of unexpected and bizarre" scenarios, and the divergent thinking of large models is extremely useful here
- Test Plan Generation: Quickly generate multiple testing strategies for reference, significantly boosting work efficiency
New Testing Challenges Brought by AI Applications
As more and more companies develop applications around AI—AI conversation practice partners, AI customer service, AI intelligent Q&A, AI IDEs, etc.—testers face entirely new challenges:
- Output Non-determinism Testing: The same input may produce different outputs, requiring adjustments to the traditional "expected result vs. actual result" testing approach
- Probabilistic Quality Assessment: How do you measure whether AI output is "good" or "bad"? New evaluation criteria and metrics systems need to be established
- Edge Case Coverage: The anomalous scenarios for AI applications are far more complex than traditional software, requiring more systematic testing strategies
- Security and Compliance Testing: Ensuring AI doesn't provide misleading "authoritative" answers in sensitive domains like healthcare and law
Traditional software testing is built on deterministic logic—given input A, you necessarily get output B, and pass/fail is clear-cut. But testing AI applications requires an entirely new mindset. Evaluation methods currently being explored in the industry include: human annotation-based scoring systems (e.g., having annotators rate AI responses from 1-5), automated evaluation metrics (e.g., BLEU scores for translation quality, ROUGE scores for summarization quality), and the "LLM-as-Judge" approach where another AI evaluates AI output quality. Additionally, AI safety testing has become an independent technical discipline, including adversarial testing (deliberately inputting provocative questions to test whether the model produces harmful output), hallucination detection (identifying when AI fabricates non-existent facts), and bias auditing (detecting whether the model produces discriminatory output toward specific groups).
Key Tips for Improving AI Usage Effectiveness
While "anyone who can type can use AI," the difference in effectiveness can be enormous. The key tips are:
- Provide Clear Context: Supply sufficient background information so the AI understands your specific scenario
- Leverage Its Strengths: Use AI for creative and divergent tasks, not precise calculations
- Iterate and Refine: Don't expect a perfect result from a single conversation; gradually approach your goal through multiple rounds of interaction
- Verify Results: AI output should always be treated as a reference; critical decisions still require human judgment
Summary
AI large models (LLMs) represent a major breakthrough in deep learning applied to natural language processing, with probability-based inference built on the Transformer architecture at their core. Understanding this fundamental nature allows us to leverage strengths while avoiding weaknesses: fully harnessing their advantages in creative tasks while remaining cautious in scenarios demanding high precision.
For testers, this represents both an opportunity for tool upgrades—using AI to improve the efficiency of requirements review and test case design—and a new career development direction—mastering AI application testing methodologies to gain a competitive edge in this rapidly evolving field.
Key Takeaways
Related articles
Claude Code Installation Guide & The Five Stages of AI Programming Tools Explained
Complete Claude Code installation guide with the five stages of AI programming tools, from manual coding to agents. Learn 0-to-1 project building and 1-to-100 iteration challenges.

Enterprise-Level AI Project Rules Files: 5 Hard Rules + 6 Writing Techniques
AI keeps messing up your code? Learn 5 hard rules and 6 writing techniques for enterprise-level Rules files in Claude Code, Cursor & more, with templates.
Building Cloud Computing Clusters from Old Phones: Google and UCSD Explore a New Path to Sustainable Computing
Google and UCSD explore building cloud clusters from old phones, leveraging ARM chip efficiency to cut e-waste and data center carbon footprints.