AI Programming in Practice: Great Skills Don't Need to Be Handwritten — Let Them Emerge from Real-World Experience
Let AI automatically distill reusable Skills from practice instead of handwriting prompts
This article demonstrates a Skill construction methodology through a K8S cluster setup case: first let AI execute tasks in a real environment, then extract Skill documents from results, validate in clean environments to expose hidden issues, and continuously refine through iterative patches. The core insight is that great Skills should naturally emerge from practice rather than being manually written, with the human role shifting from executor to validator and direction guide.
Introduction: Let AI Accumulate Its Own Experience
In AI programming practice, many people struggle with how to write a perfect Skill (a structured prompt document). Bilibili creator IT Lao Qi shared a core insight in his "300 Lectures on AI Programming" series: Great Skills don't need to be handwritten — they should naturally emerge from practice.
This philosophy was fully validated through a real-world K8S cluster setup case — starting from scratch, letting AI execute tasks, discover problems, fix issues, and ultimately distill the entire process into a reusable Skill document.
Starting Point: Let AI Autonomously Build a K8S Cluster
First Attempt: Starting with a Simple Prompt
Lao Qi's requirement was clear: set up a K8S cluster with one master and two worker nodes in a virtual machine environment. Kubernetes (abbreviated as K8S) is Google's open-source container orchestration platform and has become the de facto standard for cloud-native application deployment. Through its architecture of Master nodes (responsible for scheduling and management) and Worker nodes (responsible for running containers), it enables automated deployment, scaling, and fault recovery. kubeadm is the official Kubernetes cluster bootstrapping tool that encapsulates what would otherwise require manually configuring certificates, etcd databases, API Server, and over ten other components into just a few commands. One master with two workers is the minimal production-grade cluster topology — one Master node handles the control plane while two Worker nodes provide basic high availability and load distribution.
His first prompt to the AI was remarkably concise:
I have a server at 230, username and password are XXX. I want to use kubeadm to install master version 1.29 on this server.
The AI worked in Agent mode, connecting from the local Windows environment to the remote Linux server, continuously experimenting using native PowerShell scripts. Agent mode is one of the core capabilities of current AI programming tools (such as Cursor, Windsurf, Claude Code, etc.), allowing AI to not only generate code suggestions but also directly execute Shell commands, read/write files, call APIs, and more. Unlike traditional Chat mode (conversation only) or Copilot mode (code completion only), Agent mode grants AI the ability to autonomously plan tasks, execute step by step, observe results, and adjust strategies. This means AI can work like a remote operations engineer — connecting to servers via SSH, running installation commands, checking logs, diagnosing errors, and auto-fixing them, forming a complete "observe-think-act" loop.
Throughout the process, the AI automatically summarized intermediate issues and attempted corrections, ultimately completing the master node deployment successfully.
Version Pitfall: The Dilemma of Domestic Mirror Sources
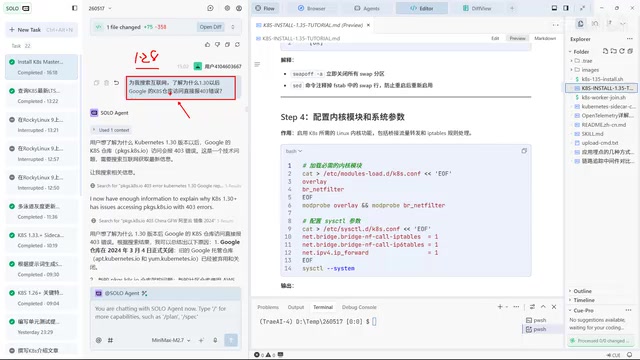
However, problems quickly surfaced — Lao Qi actually needed version 1.35 or 1.36, but the AI installed the outdated version 1.28. Investigation revealed:
- Google's official repository blocks Chinese IPs
- After March 4, 2024, the old repository was shut down, and the new AWS repository also blocks mainland China IPs
- Huawei Cloud mirrors are no longer publicly available
- Alibaba Cloud's official documentation claims support only up to version 1.29
Behind this is an industry-wide problem affecting the entire domestic K8S community. 2024 was a critical turning point: the Kubernetes community migrated package repositories from Google hosting to pkgs.k8s.io backed by AWS CloudFront, but the new repository also has access restrictions for mainland China IPs. Meanwhile, previously widely-used mirror sources like Huawei Cloud and USTC successively stopped maintenance or restricted access. Although Alibaba Cloud continues maintaining mirrors, their official documentation updates lag behind actual repository contents, leading users to mistakenly believe only older versions are supported. This "documentation says unsupported but actually available" information gap perfectly demonstrates the value of AI-assisted exploration — AI can verify available versions through actual requests rather than being misled by outdated documentation.
But Lao Qi followed the trail and discovered that Alibaba Cloud actually already had new version mirrors for 1.32-1.35, just not disclosed in official documentation. He collected this information and had the AI verify it, confirming the available mirror sources.
Core Methodology: Automatic Skill Distillation from Practice
Step 1: Generate the Initial Skill
After all problems were resolved and the master node was successfully deployed, Lao Qi said one crucial sentence:
Generate a Skill for installing K8S.
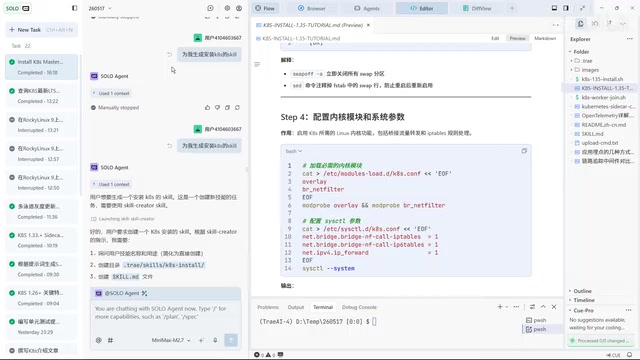
Here, a Skill is a structured prompt document in the AI programming context, typically stored as a Markdown file in the project (such as .cursorrules, CLAUDE.md, etc.), used to guide AI behavior in specific task scenarios. It differs from regular Prompts in that: a Prompt is a one-time conversational instruction, while a Skill is a persistent, reusable experience distillation. From the evolution of Prompt Engineering, the industry has transitioned from "manually fine-tuning individual prompts" to "systematically managing prompt libraries." Early users spent enormous time on wording optimization, while the core insight of the Skill paradigm is: rather than designing perfect prompts upfront, let AI automatically generate and iterate prompts through practice, transforming tacit experience into explicit, executable knowledge assets.
The AI automatically organized all the experience accumulated during the installation process — including mirror source selection, version adaptation, network configuration, etc. — into a structured Skill document stored in the cluster-init directory.
Step 2: Validate Skill Reusability
To verify whether the Skill was truly usable, Lao Qi performed a critical operation: delete the existing cluster, reset to initial state, and have the AI re-execute everything using only the Skill. The result proved successful — the version 1.35 master node installed smoothly.
He then used the same approach to have server 232 join the cluster as a worker, which went exceptionally smoothly. This produced a second Skill — worker-join.
Step 3: Expose Hidden Problems in a Clean Environment
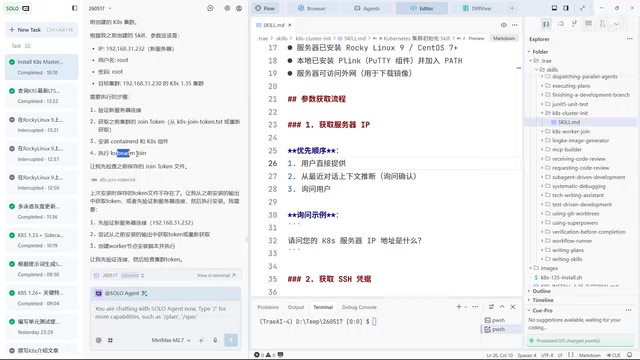
The real test came next. Lao Qi created a brand new project, set up three servers, keeping only the two Skill files. The result immediately exposed a basic but fatal error:
Inconsistent version number formats — URLs require a two-segment format (e.g., 1.35), while kubeadm initialization requires a three-segment format (e.g., 1.35.5). When context was available, the AI could infer this automatically, but in a clean environment it threw errors directly.
The concept of clean environment validation originates from several classic practices in software engineering. In Continuous Integration (CI), every build executes in a fresh container or virtual machine, ensuring build results don't depend on a developer's special local configuration. In reproducibility research, experiments must be replicated in independent environments to be recognized. Lao Qi's approach essentially applies these principles to Skill validation: when AI works in a context-rich environment, it can infer missing information (like complete version numbers) from conversation history. These "implicit dependencies" immediately manifest as errors in clean environments. This is identical to Docker's "works on my machine" problem — only by eliminating all implicit dependencies can you ensure true portability and reusability.
Worse still, once errors occurred, the AI started "making things up." This is a known issue with large language models — Hallucination. When AI encounters unsolvable errors, it may generate seemingly reasonable but actually non-existent commands, parameters, or solutions. In operations scenarios, such hallucinations are particularly dangerous because incorrect commands can corrupt system configurations or even cause data loss. The protective role of Skills is that they provide AI with verified correct paths, reducing the space where AI needs to engage in "creative reasoning." When a Skill explicitly specifies version number formats, mirror source addresses, parameter configurations, and other critical information, the AI only needs to follow the established path, dramatically reducing hallucination probability. This also explains why Skill precision is so important — every ambiguity can become an entry point for hallucination.
This demonstrates that a Skill must pass clean environment validation to be considered qualified.
Step 4: Continuously Patch and Refine Skills
Lao Qi's repair strategy was highly instructive:
- Split version number parameters: Separate a single version number into
major_versionandk8s_versionvariables, each used in different scenarios - Add IP acquisition rules: Declare in the Skill that "you may ask users to specify or automatically query environment information; when uncertain, you must ask the user"
- Distill runtime experience: Issues like hostname defaulting to localhost causing problems, or incorrect P-Link parameter settings, were all discovered during bare validation and added to the Skill
Lao Qi used an elegant prompt:
Is there any experience that can be added to the Skill?
The AI automatically organized problems solved during validation into a priority table, and Lao Qi then added high and medium priority items to the Skill.
Methodology Summary: The Correct Skill Construction Workflow
The entire process reveals a clear Skill construction methodology:
- Let AI do the work first: Provide the goal, let AI execute in a real environment, don't over-prescribe
- Extract from results: After task completion, have AI summarize the process into a Skill
- Clean environment validation: Test the Skill in a fresh environment without context
- Patch when problems are found: Don't manually edit the Skill — describe the problem and let AI fix and distill it
- Continuous iteration: Each use may reveal new issues, continuously refining the Skill
This workflow shares remarkable similarities with Test-Driven Development (TDD) in software engineering: write tests first (clean environment validation), then write implementation (Skill content), fix when failures are found, and continuously improve quality through red-green-refactor cycles. The difference is that here the "tests" are end-to-end validations in real environments, and the "implementation" is automatically generated and corrected by AI.
The end result: simply tell the AI which server is the master node and which are worker nodes, press enter, and it automatically handles all version adjustments and adaptations — achieving true one-click deployment.
Insights: A New Paradigm for Knowledge Management in the AI Era
The value of this case extends beyond K8S deployment itself — it demonstrates a knowledge distillation paradigm for the AI era:
- Knowledge is no longer static documentation but executable, verifiable Skills
- Experience accumulation doesn't rely on manual summarization but is automatically extracted from practice
- Skill quality is ensured through repeated validation and patch iterations
- The human role shifts from "executor" to "validator" and "direction guide"
The deeper significance of this paradigm is that it redefines the medium for "expert knowledge." Traditionally, an operations expert's value lies in the experience accumulated in their mind — which pitfalls they've encountered, which configurations are error-prone, which version combinations have compatibility issues. This tacit knowledge is difficult to pass on, and an expert's departure often means knowledge loss. The Skill paradigm makes this tacit knowledge explicit as version-controlled, shareable, continuously iterable document assets. More importantly, these knowledge assets are "alive" — they can be directly executed and verified by AI, rather than merely serving as reference documentation for human reading.
As Lao Qi said: "By distilling Skills, you'll make your AI run faster and better over time." This is perhaps the most important personal competitive advantage in the AI programming era — not the ability to write code, but the ability to have AI accumulate and reuse experience for you.
Key Takeaways
- Great Skills don't need to be handwritten — they should naturally emerge from AI's actual task execution process
- A Skill must be validated in a clean environment to be considered qualified; working with context doesn't mean truly reusable
- Through the iterative cycle of "discover problems → let AI fix → add to Skill," continuously improve Skill quality
- Detail issues like version number formats and environment variable acquisition often only surface during clean validation
- The human role shifts from executor to validator and direction guide; the core competitive advantage lies in having AI accumulate and reuse experience
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.