AI Progress Demands a More Nuanced Examination: A Rational Framework Beyond Hype and Panic
A rational framework for evaluating AI progress beyond the hype-panic dichotomy.
This article argues that AI discourse is stuck between hype and panic, and calls for a more nuanced evaluation framework. It examines the gap between benchmark performance and real-world reliability, distinguishes pattern matching from causal reasoning, and emphasizes the shift from "what AI can do" to "what it can reliably do." Practical guidance is offered for researchers, enterprises, and decision-makers to adopt cautious optimism.
Introduction: Rational Thinking Beyond AI Hype and Panic
In the AI space, public opinion tends to swing between two extremes — either the fervent optimism of "AGI is just around the corner" or the deep anxiety of "AI will replace everything." Recently, researcher Pranav Gasawa (@pgasawa) and Professor Joey Gonzalez (@profjoeyg) co-authored an article that has garnered widespread attention, calling on the industry and the public to adopt a more nuanced perspective when evaluating the real progress of AI.
The article has been positively received in the tech community and is regarded as a rare voice of reason in the current AI discourse.
Why Do We Need a More Nuanced AI Evaluation Perspective?
The Polarization Problem in Current AI Narratives
The current public discourse around AI suffers from severe polarization. On one hand, tech companies and some researchers continuously release jaw-dropping benchmark scores, creating the impression that AI capabilities are advancing at breakneck speed. On the other hand, critics point to the many limitations of these models in real-world applications, questioning the true meaning of so-called "progress."
This black-and-white framing does nothing to help us understand the actual state of AI. What we need is an analytical framework that can simultaneously acknowledge both progress and limitations — neither blindly optimistic nor relentlessly pessimistic. In the philosophy of science, this way of thinking is known as "Critical Realism" — it acknowledges the existence of objective progress while emphasizing that our understanding of that progress is always constrained by our measurement tools and theoretical frameworks.
The Gap Between Benchmarks and Real-World Capabilities
The AI field has long grappled with a problem that is frequently discussed yet never adequately addressed: stellar performance on benchmarks does not equate to reliable capability in the real world. A model may excel on standardized tests but falter when confronted with even slightly varied real-world scenarios.
To understand the deeper reasons behind this issue, we need to look at how current AI benchmarks operate. Common benchmarks include MMLU (Massive Multitask Language Understanding), HumanEval (code generation), and GSM8K (mathematical reasoning), all of which use standardized question sets to measure model capabilities. However, several structural problems exist here. First, there's Goodhart's Law in action — "When a measure becomes a target, it ceases to be a good measure." When research teams optimize for specific benchmarks, models may learn "shortcuts" for solving problems rather than truly mastering the underlying capabilities. Second, there's the issue of data contamination: since LLMs are trained on internet data, benchmark questions and answers may already appear in the training set, meaning the model's "reasoning" is actually "memorization." Furthermore, benchmarks are typically static and fixed in format, while real-world problems are often dynamic, ambiguous, and require multi-step interaction to clarify.
This "benchmark illusion" can easily mislead investors, decision-makers, and everyday users in their assessment of AI capabilities, leading to unrealistic expectations or misallocation of resources. In recent years, the research community has begun experimenting with more dynamic evaluation methods, such as adversarial evaluation, out-of-distribution generalization testing, and evaluation platforms based on real user interactions (like Chatbot Arena), but these approaches have yet to become part of the mainstream narrative.
Key Dimensions for Rationally Evaluating AI Progress
Clear Understanding of Capability Boundaries
A nuanced examination of AI progress first requires us to clearly distinguish between different types of capability improvements. Language models have indeed made significant strides in text generation, code writing, and knowledge-based Q&A, but they still face fundamental challenges in causal reasoning, long-term planning, and reliability guarantees.
It's worth explaining the essential difference between "causal reasoning" and "pattern matching." Current LLMs are fundamentally statistical models based on the Transformer architecture — they generate outputs by learning patterns and correlations from massive amounts of text. This is similar to what cognitive scientist Daniel Kahneman describes as "System 1" thinking — fast, intuitive, pattern-recognition-based cognition. However, true causal reasoning requires "System 2" thinking — slow, deliberate, logic-chain-based reasoning. While recent Chain-of-Thought prompting and reasoning models (such as OpenAI's o1 series) have made progress in simulating System 2 reasoning, whether this simulation is equivalent to genuine causal understanding remains an open scientific question. Regarding long-term planning, the autoregressive generation mechanism of current models (predicting the next token one at a time) inherently lacks global planning capability — they are better at "local coherence" than "global optimality."
Conflating these different dimensions of capability leads to misjudgments about AI's overall level. A more constructive approach is to separately evaluate AI's actual performance and reliability for each specific application scenario.
From "What It Can Do" to "What It Can Reliably Do"
This is perhaps the most critical mindset shift in current AI capability assessment. There is often an enormous gap between dazzling demo performances and stable operation in production environments. A model occasionally completing a complex task is an entirely different matter from it consistently and reliably completing that task.
From an engineering perspective, this involves the "long-tail problem" of AI systems. In most common scenarios, a model may perform well (say, 95% of the time), but the remaining 5% of edge cases can lead to catastrophic failures. In high-stakes domains like autonomous driving, medical diagnosis, and financial trading, this 5% unreliability is completely unacceptable. Moreover, current LLMs generally suffer from poor "confidence calibration" — they cannot accurately judge when they might be wrong, often delivering correct answers and incorrect answers with the same confident tone (the so-called "hallucination" phenomenon). This means users cannot assess reliability based solely on the model's output.
For enterprises and developers, focusing on AI's reliability boundaries is more important than focusing on its capability ceiling. This is also why human-in-the-loop approaches remain the most pragmatic choice in real-world deployment. Specific implementations of human-AI collaboration vary widely: from simple "AI generates, human reviews" workflows, to more sophisticated tiered systems where "AI flags low-confidence outputs for human intervention," to advisory models where "AI serves as a supplementary information source for human decision-making." The choice of model depends on the risk tolerance and efficiency requirements of the specific scenario.
Practical Implications for Industry and Research
The Academic Community's Responsibility for Transparency
The article by Gasawa and Professor Gonzalez also carries an implicit call to academia: researchers should be more transparent about model limitations when publishing results, rather than only highlighting peak performance. This kind of academic honesty is crucial for maintaining public trust and guiding reasonable expectations.
This call comes against the backdrop of an increasingly serious "reproducibility crisis" in AI research. Multiple surveys have shown that a significant proportion of AI paper results are difficult to independently reproduce, due to reasons including: selective reporting (showcasing only the best results while hiding failed experiments), overfitting test sets through hyperparameter tuning, and lack of complete experimental detail disclosure. In recent years, the academic community has begun taking measures to address this — top conferences like NeurIPS have introduced "reproducibility checklists" requiring authors to explicitly state computational resources, random seeds, data preprocessing steps, and other key information; some journals now require code and data submissions; and documentation standards like "Model Cards" and "Datasheets for Datasets" are promoting more comprehensive disclosure of model capabilities and limitations. However, under the pressure to publish papers and secure funding, overclaiming remains a pervasive phenomenon.
A Rational Foundation for Enterprise AI Decisions
For enterprise decision-makers considering AI investments, this nuanced perspective is especially important. Understanding AI's true capability level in specific scenarios helps make wiser technology selection and investment decisions, avoiding project failures caused by inflated expectations.
Specifically, when evaluating AI solutions, enterprises should focus on several key questions: Does the solution have validated case studies in scenarios similar to their own business? Is the vendor willing to transparently share failure cases and known limitations? Does the system have a graceful degradation mechanism when encountering inputs beyond its capability range? The answers to these questions are often far more predictive of an AI project's actual success or failure than benchmark scores.
Conclusion: Cautious Optimism Is the Healthy AI Attitude
In an era of rapid AI advancement, maintaining rational and nuanced judgment is more important than ever. The article by Gasawa and Professor Gonzalez reminds us that real progress is not defined by hype — it must be confirmed through rigorous evaluation and honest discussion.
Maintaining "cautious optimism" toward AI — acknowledging its enormous potential while clearly recognizing its current limitations — is perhaps the best attitude for promoting the healthy development of this field. This attitude applies not only to technology practitioners but also to policymakers, investors, and the general public. In an age of information overload, the ability to distinguish signal from noise and substance from hype is itself a scarce and invaluable skill.
Related articles
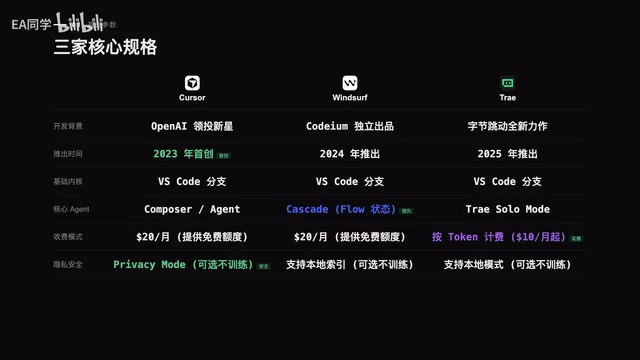
Cursor vs Windsurf vs Trae: An In-Depth Comparison of Three Major AI IDEs
A comprehensive comparison of Cursor, Windsurf, and Trae across five dimensions including coding, Agent autonomy, and pricing, with detailed scores and recommendations.
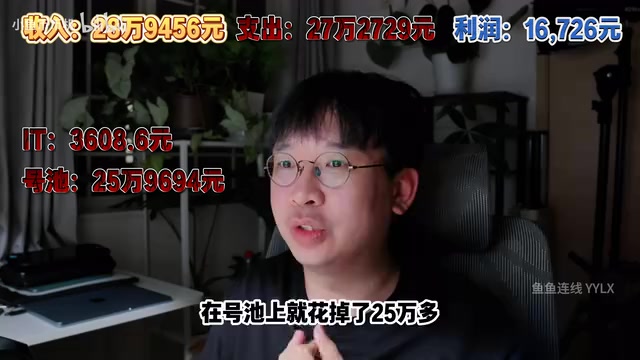
AI API Relay Startup's First Month: Open Books Reveal Just ¥16K Profit on ¥290K Revenue
A 3-person team shares their AI API relay startup's first month: ¥290K revenue, 95% spent on API costs, only ¥16.7K book profit. A deep dive into adjusted margins, cost structure, and competition.
Trae Hands-On Tutorial: Build a Full-Stack Website with Just 3 Prompts
Learn how to use ByteDance's AI coding tool Trae to build a full-stack website with just 3 prompts—covering frontend, backend API, and admin panel.