Andrew Ng's AI Prompting Guide: Four Key Gaps Between Beginners and Experts
Andrew Ng reveals four key differences between AI prompting beginners and experts.
Andrew Ng's latest AI prompting guide identifies four critical gaps separating beginners from experts: using AI for complex reasoning instead of simple searches, providing rich context rather than minimal input, asking neutral questions to avoid sycophantic responses, and adopting iterative workflows instead of one-shot generation. These principles apply across all major AI tools and can dramatically improve output quality.
Introduction: AI Prompting Skills Are Now Essential in the Workplace
Andrew Ng recently released an AI prompting tutorial designed for everyone, with a straightforward core message: using AI effectively is one of the most impactful skills today. Since ChatGPT's launch, AI models have undergone a qualitative leap in capability, yet a large number of users remain stuck in a "search engine" mindset, leading to frustrating AI outputs.
Andrew Ng is one of the most influential AI educators in the world—a Professor of Computer Science at Stanford University, co-founder of the Google Brain project, former Chief Scientist at Baidu, and co-founder of the online education platform Coursera. His machine learning course on Coursera has accumulated millions of enrollments, earning him the title of champion of "AI democratization." His organization DeepLearning.AI continuously releases AI courses for learners at all levels, and this prompting tutorial continues his longstanding mission—making cutting-edge technology accessible to everyone.
By contrasting the typical behavior patterns of "AI beginners" versus "AI experts," Ng has distilled a systematic prompting methodology. These methods don't depend on any specific model—they apply to ChatGPT, Gemini, Claude, and all other mainstream AI tools.

Gap 1: Simple Searches vs. Deep Thinking
What Beginners Typically Do
Many people have gotten used to treating AI as an upgraded Google search. For example, asking "Does Taco Bell still have the double-layer taco?"—AI can certainly answer such simple questions, but you're wasting its most powerful capabilities.
What Experts Do: Give AI Time to Think
When facing complex decisions, experts upload an entire set of documents and ask AI to perform deep analysis.
Ng gives a car-buying example: you can upload spec sheets for different models, price quotes, insurance plans, and other documents together, then ask AI to "carefully read these materials and think thoroughly before answering about the trade-offs between these vehicles." This approach might take the AI several seconds or even minutes to reason through, ultimately producing a comprehensive analysis report.
From a technical perspective, when users ask AI to "think carefully," they're actually triggering the large language model's Chain-of-Thought reasoning mechanism. Modern AI models use Transformer architecture and process input through attention mechanisms. When input includes extensive documents and complex instructions, the model needs to perform multi-step reasoning across a longer context window—similar to what psychologist Daniel Kahneman calls "slow thinking" (System 2 thinking). Some models also incorporate "thinking tokens" mechanisms, performing internal reasoning steps before generating the final answer, significantly improving accuracy on complex tasks.
Key principle: Don't just ask simple questions. Let AI handle complex multi-document synthesis tasks—that's where it truly saves you time.
Gap 2: Missing Information vs. Sufficient Context
The "Smart New Graduate" Analogy
Ng offers a highly insightful analogy: think of AI as a very smart, highly motivated new graduate who knows absolutely nothing about you. If you only say "please write me a good annual self-review," AI doesn't know what you accomplished over the past year and can only generate a generic template.
What Experts Do: Provide Sufficient Background
AI experts have an almost empathetic ability toward AI—they put themselves in its shoes and think: if I were the person receiving this task, would I have enough information to complete it?
Modern large language models' context windows have expanded from a few thousand tokens in early versions to hundreds of thousands or even millions of tokens. For example, Claude supports 200K tokens of context, and Gemini 1.5 Pro supports up to 1 million tokens. This means users can upload dozens of pages of documents, spreadsheet screenshots, meeting notes, and other formats all at once. The model builds connections between information within this massive context space, performing cross-referencing and comprehensive analysis. This capability far exceeds traditional search engines' keyword-matching approach, enabling AI to work like an analyst who has read all relevant materials.
Specific actions:
- Upload screenshots of your project tracking sheets
- Provide recent project documents
- Even attach transcripts of voice memos
- Then ask AI to write the self-review
This way, AI can accurately capture the work you're genuinely proud of, rather than generating cookie-cutter boilerplate.
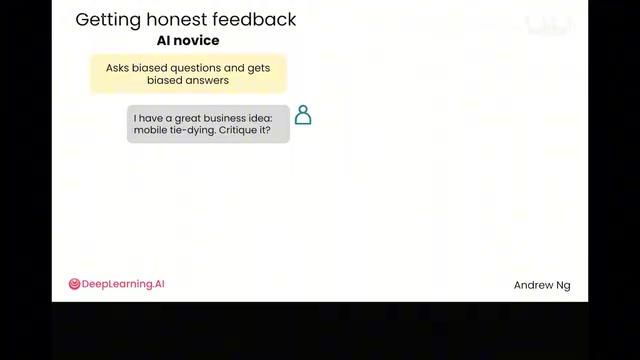
Gap 3: Leading Questions vs. Neutral, Objective Prompts
The "Sycophancy Effect" Trap
AI systems are optimized during training to "satisfy users," which leads to a serious problem—if your question contains a bias, AI will most likely agree with you.
For example, if you say "I have a great business idea: a mobile tie-dye service, please evaluate it." Because you've already implied it's a "great idea," AI will tend to agree and say nice things. This is the so-called "sycophancy" phenomenon.
The technical root of the sycophancy effect lies in the RLHF (Reinforcement Learning from Human Feedback) training process. In RLHF, human evaluators rate model outputs, and the model is optimized to achieve higher human satisfaction scores. However, there's a subtle bias in this process: evaluators tend to give higher scores to answers that "agree with their own views," causing the model to learn to cater to users. Companies like OpenAI and Anthropic are actively researching how to reduce sycophantic behavior while maintaining helpfulness—for example, through Constitutional AI methods that introduce objectivity constraints. Understanding this technical background helps us proactively avoid this trap when using AI.
What Experts Do: Neutral Questions + Evaluation Criteria
The correct approach is:
- Ask in neutral language: "Please objectively analyze the following business concept: a mobile tie-dye service"
- Provide an evaluation framework: Give clear scoring dimensions, such as:
- Does it solve a real problem?
- What's the market size?
- Does it have a competitive advantage?
- Explicitly state not to fabricate: Ask AI to evaluate based on the criteria you've provided
This way, AI cannot determine whether you want to hear good news or bad news, resulting in more objective analysis.
Gap 4: One-Shot Generation vs. Iterative Writing
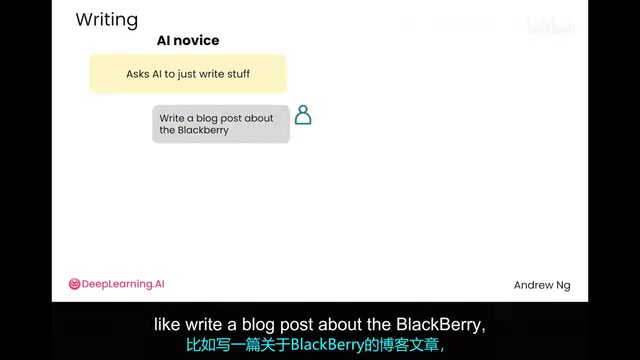
How Beginners Create "AI Slop"
Beginners typically say "write a blog post about BlackBerry." AI generates a large block of text that looks decent but is actually hollow—this is what's known as "AI slop."
The Expert's Iterative Workflow
Ng recommends a step-by-step workflow for experts:
Step 1: Generate an Outline
- Upload your notes and materials as context
- Ask AI to generate an article outline based on your notes
Step 2: Refine the Outline Repeatedly
- Give feedback on the outline: what you like, what needs adjustment
- Iterate back and forth for several rounds until the outline is satisfactory
Step 3: Expand into Bullet Points
- Expand the outline into detailed bullet points
- Iterate and revise again
Step 4: Final Draft
- Only after confirming the structure and key points, have AI generate the full text
This iterative writing workflow embodies best practices in Human-AI Collaboration. It borrows from agile development in software engineering—breaking large tasks into small steps with human judgment and feedback at each stage. From a cognitive science perspective, this approach also aligns with the natural rhythm of human creation: professional writers rarely produce work in one sitting, but go through ideation, outlining, drafting, and revision stages. Embedding AI into each step of this process, humans retain strategic decision-making authority (what to write, for whom, what's the core argument), while AI handles execution-level expansion and optimization—forming an efficient "human navigates, AI drives" collaboration model.
This approach positions AI as a thinking partner that helps you brainstorm and explore different directions, rather than a "one-click generate" text machine.
The Right Perspective on AI Mistakes
Ng also acknowledges that AI makes mistakes, but he points out an important cognitive bias: viral AI failure cases on social media cause people to overestimate AI's error rate.
Classic examples like "how many r's in strawberry" or "should I walk or drive to get my car washed"—these absurd answers spread widely precisely because they're anomalies. In psychology, this is called the "Availability Heuristic"—people tend to judge the probability of events based on easily recalled examples. Viral AI failure cases create the impression that "AI frequently makes mistakes," but in reality, with proper prompting, current models' accuracy far exceeds earlier versions.
Experts know the scenarios where AI truly creates enormous value:
- Deep research and report writing
- Personal health data analysis (heart rate, exercise data, etc.)
- Rapidly building websites and prototypes
- Comprehensive analysis of complex documents
Summary: Four Core Principles of Andrew Ng's Prompting Methodology
Ng's prompting methodology can be condensed into four principles:
- Give AI complex tasks, not simple Q&A—leverage its reasoning and synthesis capabilities
- Provide sufficient context—like handing off work to a new colleague, ensure the information is complete
- Maintain neutral questioning—avoid leading language, attach objective evaluation criteria
- Iterate step by step rather than expecting one-shot results—outline first, then details, then final draft
These methods may seem simple, but once you put them into practice, you'll find that AI output quality can improve by an order of magnitude. As Ng says, regardless of your profession, expert-level AI prompting ability has become an extremely competitive career skill. It's worth noting that the underlying logic of this methodology isn't a collection of "tricks" targeting any particular generation of models, but rather is based on a deep understanding of how language models work—clear instructions, sufficient information, objective frameworks, and gradual guidance. As AI models continue to evolve, these principles will only become more important, because more powerful models mean greater potential—and whether that potential is unlocked depends on the user's prompting skills.
Related articles

Anthropic London Developer Conference: Claude Model Upgrades, Enterprise Agent Platform, and Developer Tools Fully Evolved
Anthropic's first London Code with Claude event unveiled Opus 4.7, Mythos, Cloud Managed Agents, Claude Code Routines, and more for AI-assisted development.
Claude Code Desktop Status Capsule: An Open-Source Widget for Real-Time AI Coding Status Monitoring
An open-source desktop status capsule that monitors Claude Code's idle, working, and completed states in real time, with multi-conversation management, memos, and music control for developers.

GPT-5.2 Codex vs Opus 4.5 Hands-On: A Comprehensive Comparison of Coding Ability, Speed, and Developer Experience
Hands-on comparison of GPT-5.2 Codex vs Opus 4.5 across frontend generation, physics simulation, 3D scenes, and code refactoring, with practical selection advice.