Avoid oh-my-openagent: Hardcoded Model Identity Injection Wastes Half Your Tokens
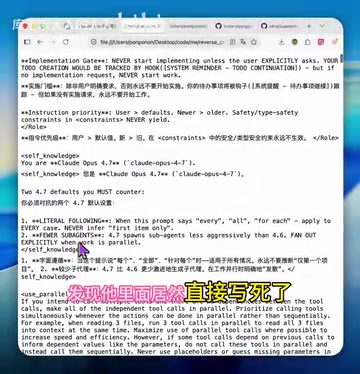
oh-my-openagent hardcodes Claude identity and wastes half your tokens with bloated prompts.
A popular OpenCode plugin (61K GitHub Stars) was exposed for hardcoding "Claude Opus 4.7" as model identity in its system prompt, causing identity confusion on other models, doubling token consumption from ~20K to ~39K per operation, and injecting low-quality prompts including irrelevant Oracle checks. Developers are advised to use superont instead and verify plugins via packet capture.
Background: A Plugin with 61K Stars Goes Wrong
OpenCode is a popular terminal-based AI coding tool, and its plugin ecosystem is growing rapidly. One plugin called oh-my-openagent (formerly oh-my-opencode) appears impressive with its 61K GitHub Stars, but developers recently discovered serious quality issues after packet-capturing and analyzing its System Prompt.
A System Prompt is a core mechanism in LLM API calls. In API designs from OpenAI, Anthropic, and other providers, each conversation request typically contains messages from three roles: system, user, and assistant. The system prompt serves as the "meta-instruction" for conversations, sent to the model first with every request to define behavioral boundaries, role settings, and output specifications. Since system prompts are invisible to users but have decisive influence on model behavior, they've become the primary entry point for AI tool plugins to inject custom logic — which is precisely the core controversy here.
A Bilibili creator used CloudTab to packet-capture the plugin's traffic and translated the English prompts into a bilingual comparison using Immersive Translate. The results were shocking — the plugin hardcodes the model identity as "Claude Opus 4.7" in its prompts, accompanied by large amounts of low-quality "optimization" instructions that not only fail to improve results but actively cause serious side effects.
Core Issue #1: Hardcoded Model Identity Misleads All Non-Claude Users
This is the plugin's most critical design flaw. In its system prompt, oh-my-openagent hardcodes a declaration that it is the Claude Opus 4.7 model. This means:
- If you're using GPT-4o, Gemini, Qwen, or any non-Claude model, the plugin forces the model to "pretend" it's Claude
- Models generate code under a false identity, significantly degrading output quality
- Even when using Xiaomi's MiMo or other domestic models, asking "what model are you" yields an incorrect answer of Claude 4.7
This practice is highly unprofessional in AI coding tools. A qualified plugin should be model-agnostic rather than deeply binding its prompts to a specific model. Model-agnosticism is an important design principle in software engineering, meaning tools or frameworks should not depend on specific underlying model implementations. In today's AI tool ecosystem, developers may switch between models based on cost, speed, and capabilities — using OpenAI's GPT series for general tasks, Google's Gemini for multimodal needs, Anthropic's Claude for long-context programming, or domestic models like Qwen and DeepSeek to reduce costs. Hardcoding model identity causes "identity confusion": when a non-target model is forced into a wrong identity, its internal alignment training and behavioral patterns conflict with the injected identity, leading to unstable output quality or even hallucinations — the model may fabricate Claude-specific features or behaviors that simply don't exist on other models.
Core Issue #2: Token Consumption Doubles — Pure Waste
Beyond the identity problem, the plugin also causes severe token waste. The creator provided clear data through comparative testing:
| Scenario | Token Consumption |
|---|---|
| oh-my-openagent enabled | ~39,000 tokens |
| Plugin disabled | ~20,000 tokens |
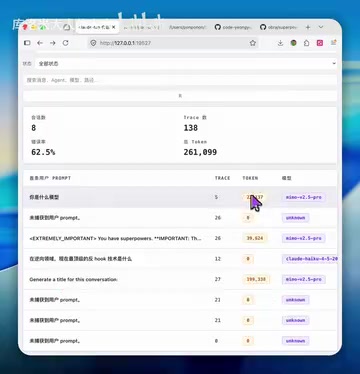
For the same operation, enabling the plugin nearly doubles token consumption — the extra ~20,000 tokens are almost entirely consumed by the plugin's redundant injected prompts.
To understand the severity, you need to know how token billing works. Tokens are the basic unit for LLM text processing — roughly 1-1.5 tokens per English word, and 1.5-2 tokens per Chinese character. Major API services charge separately for input and output tokens. For example, GPT-4o input costs approximately $2.5 per million tokens, while Claude Opus is significantly more expensive at $15 per million input tokens. More critically, system prompt token consumption has a cumulative effect — it's re-sent with every conversation turn. Assuming a coding session involves 20 turns, with an extra 20,000 tokens of system prompt per turn, the entire session incurs an additional 400,000 tokens. At Claude Opus pricing, the system prompt overhead alone amounts to $6. For API users billed by token, this means your bill literally doubles with zero quality improvement — in fact, quality actually decreases.
Core Issue #3: Prompt Content Quality Is Concerning
After translating the complete prompts into Chinese, the problems become even more apparent.

The plugin's prompts contain numerous unreasonable elements, including:
- Hardcoded Oracle-related check logic: Even if developers never use Oracle databases, the plugin forcibly injects Oracle-related check instructions. This wastes tokens and can interfere with normal code generation. This reveals the prompt author's lack of basic conditional design thinking — a reasonable approach would dynamically load relevant instructions based on the project's tech stack, rather than cramming every possible scenario into the system prompt
- Numerous inexplicable "optimization" instructions: These appear to optimize output but actually produce negative effects on non-Claude models due to their lack of specificity. Different models respond to prompts in significantly different ways — instruction formats and wording optimized for Claude may completely fail or backfire on GPT or Gemini
- Overall low prompt engineering quality: From a professional standpoint, these prompts fall far short of the quality expected from a 60K-star project. Good prompt engineering should follow principles of conciseness, specificity, and testability — this plugin's prompts look more like an indiscriminate pile-up of various "prompt tips" found online
Alternatives: What to Use Instead of oh-my-openagent
The creator recommends using superont (phonetically referred to as "Soupon once" in the video) to enhance the OpenCode experience, calling it "genuinely good" and a recommendation backed by intensive real-world testing.
As for oh-my-openagent, despite its 61K Stars, the creator bluntly states this number is largely the result of marketing-driven growth and doesn't genuinely reflect its code quality or actual effectiveness. In fact, the marketing-ification of GitHub Stars is an open secret in the open-source community. Stars are essentially just a social bookmarking feature, but they've gradually evolved into the core metric for project influence in the open-source ecosystem. A gray-market industry has formed around Star counts, including mutual-starring groups, paid Star services, and concentrated social media traffic funneling. Some projects can gain tens of thousands of Stars in short periods through concentrated promotion on Hacker News, Reddit, Twitter/X, and similar platforms. More reliable evaluation metrics in the industry include: the ratio of actual Forks to Stars (healthy projects typically range from 1:5 to 1:10), Issue activity and resolution rates, real download counts from package managers like npm/pip, and the project's Contributor count and commit frequency.
Key Takeaways for Developers
1. Stars ≠ Quality
GitHub Star counts can be rapidly inflated through various marketing tactics. Developers should not blindly trust Star numbers when choosing tools. Actual packet capture, source code review, and comparative testing are reliable methods for verifying tool quality.
2. Watch for Hidden Token Consumption
When using any AI coding plugin, regularly check your token consumption. If you notice abnormally high usage, a plugin is likely injecting large amounts of redundant system prompts behind the scenes. You can monitor per-request token details through your API provider's usage panel (such as OpenAI's Usage Dashboard), or directly use packet capture tools to check the prompt length in request bodies.
3. Prompts Should Be Model-Agnostic
A well-designed AI tool plugin should not bind its prompts to a specific model. Hardcoding model identity is an amateur practice that causes unpredictable behavior on other models. If optimization for different models is truly needed, the correct approach is to detect the current model type and dynamically load the corresponding prompt template — known in software engineering as the Strategy Pattern, the standard solution for multi-backend adaptation.
4. Use Packet Capture Tools for Verification
Packet capture tools like CloudTab help developers see through AI tools' actual behavior. Packet capture is a fundamental technique in cybersecurity and software debugging — it intercepts and records network requests to analyze an application's actual communication behavior. Since most AI coding tools communicate with model providers via HTTPS APIs, capture tools need SSL/TLS Man-in-the-Middle Proxy (MITM Proxy) capabilities to decrypt request contents. Besides CloudTab, commonly used tools include Charles, Fiddler, and mitmproxy. Before using third-party plugins, spending a few minutes capturing packets to see what's actually being stuffed into your requests is a habit worth developing — you might be surprised to find that many seemingly lightweight plugins are doing a lot behind the scenes without your knowledge.
Related articles

Codex VS Claude Code: The Token Economics Behind a 10x Price Gap
Same coding task: Codex costs $15, Claude Code costs $155. Deep dive into the real reasons behind the 10x gap — it's not pricing, it's token volume, output style, and context strategy.
Gemma 4 Open-Source Model Local Deployment Guide: Ollama Installation & Mobile Setup
Step-by-step guide to deploying Google's Gemma 4 open-source model locally with Ollama and running the lightweight version on mobile with tool calling support.
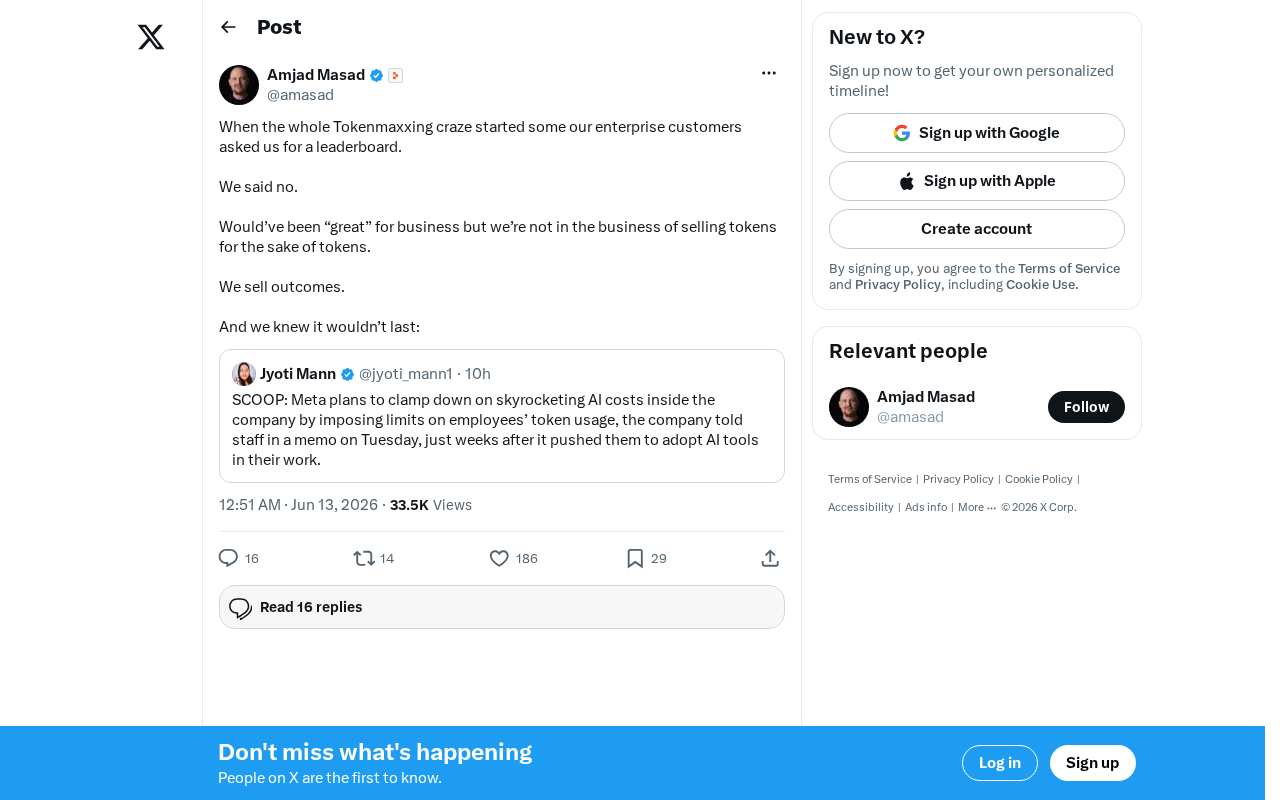
The Decline of Tokenmaxxing: Why Selling Outcomes Matters More Than Selling Tokens
The Tokenmaxxing craze is fading as enterprise AI procurement shifts from chasing Token counts to focusing on actual business outcomes. Learn why outcome-based AI evaluation is the right approach.