Biological Neurons vs. Artificial Neurons: How Big Is the Computational Gap?
Biological neurons vastly outperform artificial ones — and that gap may reshape future AI design.
Recent research reveals that biological neurons possess computational capabilities far beyond classical artificial neuron models. Through dendritic computing, spike-timing mechanisms, and complex synaptic plasticity, a single biological neuron may rival an entire multi-layer artificial network. This efficiency gap — the brain runs on just 20 watts — suggests that next-gen AI breakthroughs may come from rethinking the fundamental computational unit rather than simply scaling parameters.
Introduction: Do We Really Understand Neurons?
In an era where deep learning has swept the globe, artificial neural networks (ANNs) have achieved remarkable results in fields like image recognition and natural language processing. Yet a long-overlooked question is once again capturing the attention of the academic community: Just how much more powerful are real biological neurons compared to classical artificial neurons?
A study by researcher Ido Aizenbud and collaborators delivers a striking conclusion — the computational capacity of biological neurons far exceeds what classical artificial neuron models can express. This is not merely a neuroscience question; it could profoundly influence the design direction of next-generation AI architectures.
The Classical Artificial Neuron: A Simplified Model Used for Nearly 70 Years
The Historical Limitations of the Perceptron
The artificial neuron used in modern deep learning can be traced back to the Perceptron proposed by Frank Rosenblatt in 1957. This model abstracts a neuron into an extremely simple computational unit: it receives multiple input signals, computes a weighted sum, and passes the result through an activation function to produce an output.
In fact, the intellectual roots of the perceptron go back even further to 1943. Neuroscientist Warren McCulloch and logician Walter Pitts proposed the first mathematical neuron model — the McCulloch-Pitts (MCP) model — which treated a neuron as a binary logic gate: it receives inputs of 0 or 1, and outputs 1 when the weighted sum of inputs exceeds a threshold, otherwise outputting 0. Rosenblatt built on this by adding a learnable weight adjustment mechanism, giving the perceptron the ability to learn automatically from data. Notably, in 1969, Minsky and Papert proved in their book Perceptrons that a single-layer perceptron cannot solve linearly inseparable problems such as XOR — a conclusion that directly triggered more than a decade of "AI winter." It wasn't until the popularization of the backpropagation algorithm and the emergence of multi-layer networks that neural network research experienced a renaissance.
This "dot product + nonlinearity" paradigm has been in use for nearly 70 years. Despite extensive innovation at the network architecture level — from convolutional networks to Transformers — the computational model of an individual neuron has remained essentially unchanged. At its core, it is a linear classifier with a simple nonlinear transformation.
The Cost of Simplification
This simplification has undeniably been an engineering success, as it makes large-scale parallel computation possible. But from a biological perspective, this model discards a vast amount of critical information. Real biological neurons are not simple "switches" or "weighted summers" — they are miniature computing systems with complex dendritic structures.
The True Computational Power of Biological Neurons: Far More Than "Weighted Summation"
Dendrites Are Miniature Computers in Their Own Right
The traditional view treats dendrites as simple signal transmission channels — like wires connecting to the neuron's cell body. But a growing body of research shows that a single dendrite can perform complex nonlinear computations on its own. Different branches on a dendrite can independently process information, perform local signal integration and nonlinear transformations, and then pass the results to the cell body.
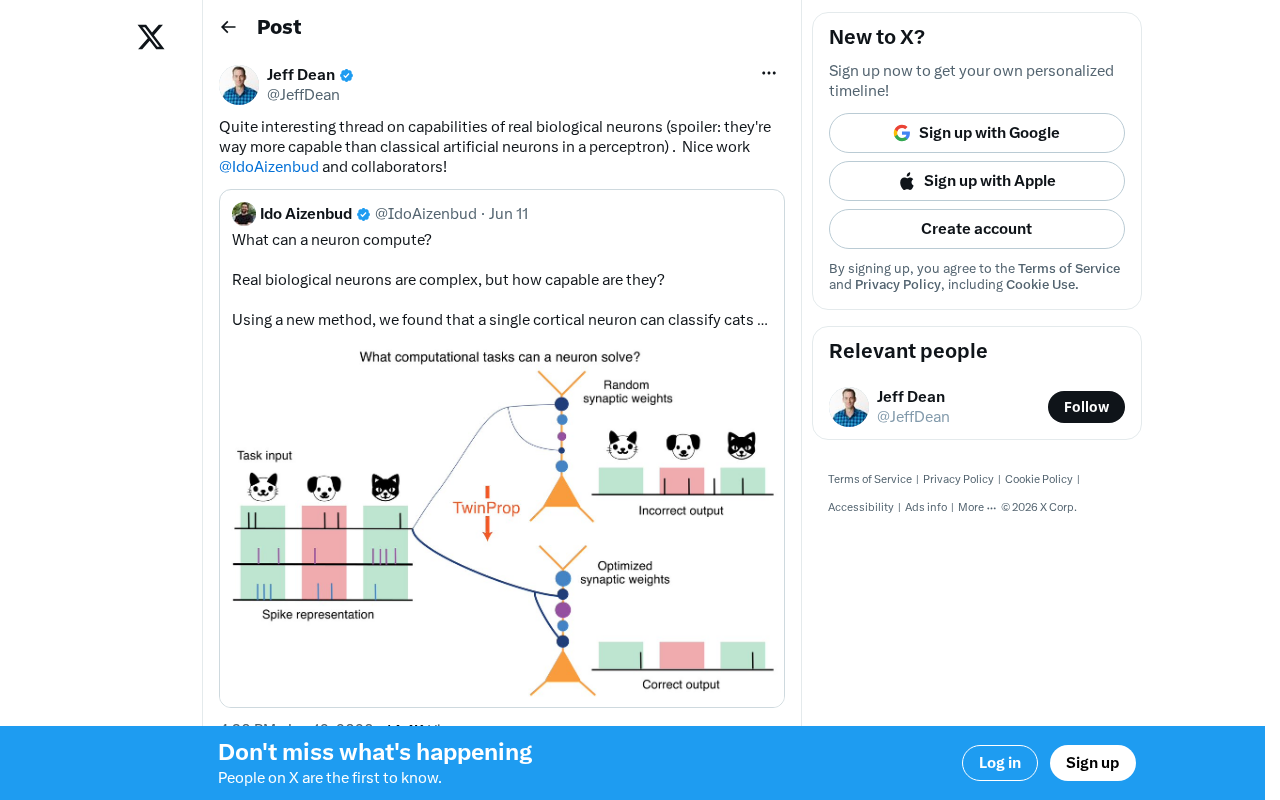
The computational power of dendrites stems from their complex biophysical properties. Dendrites are not passive cables; they are studded with numerous voltage-gated ion channels (such as sodium, calcium, and potassium channels). These ion channels enable dendrites to generate local electrical signals known as dendritic spikes. In 2003, Michael Häusser's lab at University College London used two-photon imaging to directly observe local calcium signals on dendritic branches, confirming that a single dendrite can independently perform logical operations such as AND and OR. More recent research has shown that dendrites of human cortical pyramidal neurons can even perform XOR logic — precisely the operation that single-layer perceptrons were proven incapable of computing. This means that a single biological neuron already surpasses a single-layer artificial neural network in computational complexity.
This implies that the computational power of a single biological neuron may be equivalent to a multi-layer artificial neural network, rather than a single artificial neuron.
The Temporal Dimension: Critical Information Ignored by Artificial Neurons
Biological neurons also exploit a dimension that artificial neurons almost entirely ignore: time. The precise timing of spikes, short-term synaptic plasticity, and dynamic changes in membrane potential all carry rich computational information. The classical artificial neuron model is static — it processes a fixed input vector — while biological neurons perform dynamic computation within a continuous stream of time.
Multiple Synaptic Mechanisms Working in Concert
Biological neurons possess multiple types of synapses, including excitatory and inhibitory ones, each varying in location, strength, and dynamic properties. Synaptic plasticity rules are also far more complex than simple gradient descent, including:
- Spike-Timing-Dependent Plasticity (STDP): Adjusts synaptic strength based on the time difference between pre- and post-synaptic neuron firing. STDP was first systematically discovered and described by Guo-qiang Bi and Mu-ming Poo at New York University in 1998, using cultured hippocampal neurons. Its core rule is remarkably elegant: if the presynaptic neuron fires before the postsynaptic neuron (a causal relationship), synaptic strength increases (long-term potentiation, LTP); if the order is reversed, synaptic strength decreases (long-term depression, LTD). The magnitude of strengthening or weakening depends on the time interval between the two firings, typically within a window of tens of milliseconds. STDP is considered a temporally precise version of Hebb's learning rule ("neurons that fire together wire together"), providing a biological basis for how the brain learns causal relationships and temporal patterns under unsupervised conditions. Unlike backpropagation in deep learning, which relies on global error signals, STDP is an entirely local learning rule that depends only on the activity of the two neurons on either side of the synapse.
- Synaptic tagging and capture mechanisms: Enabling the conversion of short-term memory into long-term memory
- Multiple local learning rules: Operating independently across different dendritic branches
Profound Implications for AI Development
Are We Compensating for Weak Units with Brute Force?
The research by Aizenbud et al. raises a fundamental question: If the basic computational unit is oversimplified, have we been compensating for its inadequacy by stacking ever more network layers?
Current large language models routinely have hundreds of billions of parameters and consume enormous computational resources. Meanwhile, the human brain accomplishes far more general intelligent tasks using only about 86 billion neurons and roughly 20 watts of power. The magnitude of this efficiency gap can be appreciated through concrete numbers: training GPT-4 is estimated to have consumed approximately 50–100 gigawatt-hours (GWh) of electricity — equivalent to the annual power consumption of about 10,000 American households. During a single inference pass, a hundred-billion-parameter model running on a GPU cluster consumes hundreds to thousands of watts. The human brain's total power consumption is only about 20 watts — comparable to an ordinary LED light bulb. In terms of computational efficiency per unit of energy, the brain can perform approximately 10^13 synaptic operations per second per watt, while the most advanced AI chips today (such as the NVIDIA H100) perform roughly 10^12 equivalent operations per second per watt. The more critical gap lies in generality: the brain uses 20 watts to simultaneously handle vision, language, motor control, emotion, and creative thinking, whereas current AI systems typically excel at only one or a few tasks, each requiring a separate large-scale model. A significant reason for this efficiency gap may lie in the difference in capability at the level of individual computational units.
Emerging Neuron Models Under Exploration
The academic community has already begun exploring neuron models that more closely approximate biological reality. Key directions include:
- Dendritic neural networks: Introducing dendritic structures into artificial neurons, giving individual neurons multi-layer computational capabilities
- Spiking Neural Networks (SNNs): Incorporating the temporal dimension by encoding information through spike timing, more closely resembling how the brain works. SNNs are called "third-generation neural networks," and their core advantage lies in event-driven computation — neurons only compute when they receive a spike, rather than performing forward propagation across all neurons at every time step as in traditional ANNs. This sparse computation property gives SNNs theoretically very high energy efficiency. Several dedicated neuromorphic chips have already been developed: Intel's Loihi 2 integrates one million neuron cores with on-chip learning support; IBM's TrueNorth contains 5.4 billion transistors simulating one million neurons; and there are academic projects like SpiNNaker 2 from the University of Manchester. In 2024, SNN-based models have demonstrated 10–100x lower power consumption than traditional ANNs on specific tasks (such as gesture recognition and keyword detection). However, SNNs still face challenges in training efficiency and large-scale tasks. The main bottleneck is that the non-differentiability of spike signals makes traditional backpropagation difficult to apply directly; researchers are seeking breakthroughs through methods such as surrogate gradients.
- Dynamic neuron models: Such as the Izhikevich model, which can reproduce multiple biological neuron firing patterns
While these directions have not yet comprehensively surpassed traditional models in engineering applications, they represent an important shift in thinking — from "stacking parameters" to "increasing per-unit computational density."
Balancing Biological Realism and Engineering Feasibility
The simplicity of the classical artificial neuron is not without value. It is precisely because it is simple enough that large-scale parallel computation on GPUs became possible, giving rise to today's deep learning boom. The balance between biological realism and engineering feasibility is the central question that this field must continue to explore.
Future breakthroughs may not come from fully replicating the complexity of biological neurons, but rather from identifying those critical, overlooked computational primitives and incorporating them into artificial neural networks in hardware-friendly ways. This will require deep collaboration among neuroscientists, computer scientists, and hardware engineers.
Conclusion: The Direction of the Next Paradigm Shift
From the perceptron to the Transformer, AI progress has primarily occurred at the network architecture level, while the computational model of individual neurons has remained virtually unchanged. The research by Aizenbud et al. reminds us once again: Biological neurons, refined by hundreds of millions of years of evolution, contain computational wisdom far richer than what current models capture.
As we marvel at the capabilities of large language models, perhaps we should also ask: if every computational unit were as powerful as a biological neuron, would we still need trillions of parameters? The answer to this question may point toward the next paradigm shift in AI development.
Related articles

Codex VS Claude Code: The Token Economics Behind a 10x Price Gap
Same coding task: Codex costs $15, Claude Code costs $155. Deep dive into the real reasons behind the 10x gap — it's not pricing, it's token volume, output style, and context strategy.
Gemma 4 Open-Source Model Local Deployment Guide: Ollama Installation & Mobile Setup
Step-by-step guide to deploying Google's Gemma 4 open-source model locally with Ollama and running the lightweight version on mobile with tool calling support.
The Decline of Tokenmaxxing: Why Selling Outcomes Matters More Than Selling Tokens
The Tokenmaxxing craze is fading as enterprise AI procurement shifts from chasing Token counts to focusing on actual business outcomes. Learn why outcome-based AI evaluation is the right approach.