Claude Code + Codex Cross-Validation: Dramatically Reducing AI Coding Bug Rates
Combine Claude Code for development and Codex for review to cross-validate and slash AI coding bugs.
This article details a practical workflow combining Claude Code and Codex to dramatically reduce AI coding bug rates. Claude Code excels at code generation and architecture, while Codex shines at code review and finding logical flaws. By following a develop-review-fix iterative loop — where Claude Code builds, generates review docs, and Codex audits for bugs — most issues are resolved within 2-3 rounds. The cross-validation approach leverages different models' cognitive biases to eliminate blind spots.
The Pain Point of AI Coding: What to Do When Code Gets Messier with Every Edit
Many AI coding enthusiasts have experienced this: the code starts out fine, but with each modification it gets messier, until eventually the entire project breaks down and becomes nearly impossible to fix. The root cause often isn't that the AI model isn't powerful enough — it's that we haven't established a sound development workflow.
Bilibili creator "Sanshao Tech" shared a development methodology he refined through practice — using Claude Code and Codex in combination to achieve cross-validation, dramatically reducing bug rates while keeping code more standardized. This approach is especially valuable for AI coding beginners.
Tool Selection: Why Claude Code + Codex
The Case for Top-Tier Tools
When it comes to choosing AI coding tools, Sanshao Tech's stance is clear: go straight for the top-tier tools. His primary tools are Claude Code and Codex, while domestic models like GLM and Kimi are rarely used for coding tasks.
This isn't about dismissing other tools — it's based on simple logic: "time is money." The cost of spending half a day wrestling with a minor bug far exceeds the cost of using better tools. Currently, Claude Code and Codex aren't particularly expensive, yet they deliver first-tier results in code generation and bug fixing.
Each Has Its Strengths, but Neither Is Optimal Alone
The key insight is: neither tool is optimal when used alone — they must be used together to achieve maximum effectiveness.
Sanshao Tech summarized their capability differences:
-
Claude Code: Anthropic's command-line AI coding tool that runs directly in the terminal, capable of reading and editing local code files, executing shell commands, and deeply integrating with development tools like Git. It operates in Agent mode, autonomously planning multi-step tasks, browsing project structures, and running tests. Built on Claude Sonnet/Opus models, it excels at code generation, architecture design, and rapid prototyping. It's great at writing code and designing architecture, getting programs up and running quickly, with development speed clearly superior to Codex. However, in practice, it frequently produces unexpected bugs.
-
Codex: This refers to OpenAI's cloud-based AI coding Agent launched in 2025 (distinct from the earlier Codex code completion model). It runs in OpenAI's cloud sandbox environment, powered by o3/o4-mini reasoning models, and can independently complete code writing, bug fixing, code review, and other tasks, submitting results as Pull Requests. It has unique advantages in code comprehension and logical reasoning, particularly excelling at discovering logical flaws and edge case issues in code. However, it falls short of Claude Code in architecture design and large-scale development. Some developers have even reported that having Codex directly modify code can actually "make the code worse."
In short, Claude Code is the better "builder," while Codex is the better "reviewer." Using them together is the key to achieving both efficiency and stability in AI coding.
Core Workflow: The Develop-Review-Fix Iterative Loop
Step 1: Use Claude Code to Analyze the Full Project
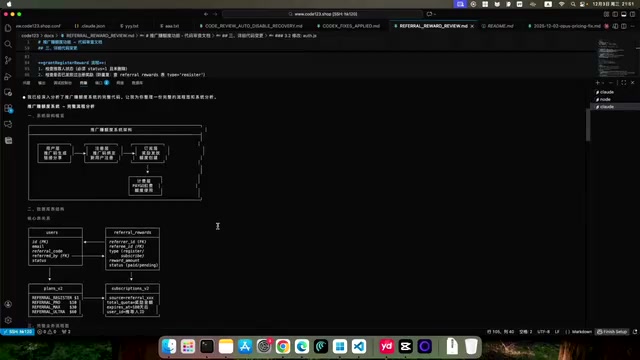
Before starting a major task, first have Claude Code read through the entire project codebase, deeply understand the system's operational flow and logical relationships, and generate a flowchart.
The purpose of this step isn't just to help the developer clarify their own thinking — more importantly, it's to let the AI fully understand the system's logical relationships. After this analysis, the AI's understanding of the system can reach 70%-80%, making subsequent code modifications much more thorough.
Step 2: Use Claude Code to Execute Development Tasks
Once the analysis is complete, give Claude Code the specific development requirements. For example, modifying a reward mechanism, asking it to deeply analyze the system before making changes.
However, Sanshao Tech admits that even when explicitly asked to "analyze deeply," Claude Code may not achieve fully comprehensive modifications. This is primarily limited by current LLM token limits — 200K tokens is actually very little.
Here's some context on tokens: a token is the basic unit of text processing for large language models. A Chinese character typically corresponds to 1-2 tokens, while an English word corresponds to 1-4 tokens. The context window of current mainstream LLMs determines how much information the model can "remember" in a single conversation. Claude's context window is 200K tokens, which seems large but is far from sufficient for a medium-sized code project. When input approaches the context window limit, the model discards earlier information through sliding windows or summary compression — this is why during long code modification tasks, the AI may "forget" previously analyzed code logic, leading to incomplete modifications or new bugs.
Just reading the code and generating flowcharts can consume 60,000-70,000 tokens. By the time it gets to modifying code, the context gets automatically compressed, causing information loss.
He believes that unless future LLMs reach context windows of 10 million tokens, truly comprehensive code modifications will remain difficult to achieve.
Step 3: Generate a Code Review Document (The Critical Bridge)
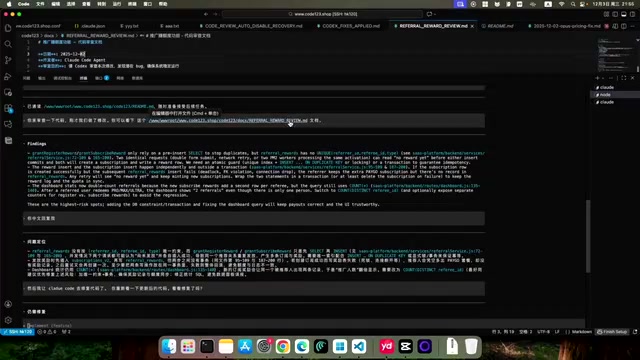
After development is complete, have Claude Code write a code review document in MD format, detailing:
- The user's original requirements
- Which code files were modified
- A detailed description of the entire modification process
This document serves as the bridge connecting Claude Code and Codex, and is the most critical handoff point in the entire cross-validation workflow.
Choosing Markdown format as the information transfer medium has deeper considerations: in multi-tool collaborative workflows, each AI tool has its own independent conversation context, and it's impossible to let one tool directly "see" another tool's complete work process. Through a carefully designed structured review document, key information (requirement context, modification scope, technical decisions, code change points) can be transferred to the next tool with minimal information loss. This essentially establishes a standardized communication protocol between AI tools — ensuring information completeness while controlling token consumption, allowing the receiving tool to quickly understand the context and get to work.
Step 4: Use Codex for Code Review
Send this review document to Codex, asking it to deeply analyze the modifications, discover potential bugs, and ensure stable system operation.
After Codex completes its review, it will list existing issues and potential bugs in the current system. Since Codex has stronger code review capabilities, it can often discover problems that Claude Code itself would have difficulty noticing.
Step 5: Cross-Validation and Iterative Fixes
Feed the issues discovered by Codex back to Claude Code, asking it to verify whether these problems actually exist. Sanshao Tech's experience is that in most cases, Claude Code will acknowledge that the issues Codex identified do indeed exist, and then proceed to fix them.
After fixes are complete, have Codex review the updated code again to confirm whether the issues have been resolved.
After 2-3 rounds of this iteration, most bugs can be resolved. This develop-review-fix loop mechanism is the core of how cross-validation reduces AI coding bug rates.
Why Not Use Claude Code to Review Claude Code
A natural question arises: why not use another Claude Code instance to review the code instead of bringing in Codex?
Sanshao Tech's answer is straightforward: when it comes to thoroughness in code review, Claude Code doesn't match Codex. The same model reviewing its own generated code tends to fall into "cognitive blind spots," while cross-validation between different models is more effective at discovering problems.
There's a deeper methodological foundation behind this. The idea of cross-validation originates from Code Review practices in software engineering and Ensemble methods in machine learning. In traditional software development, code reviews are performed by different developers, leveraging complementary knowledge blind spots to find issues. Applying this concept to AI coding, different models develop different "cognitive biases" due to differences in training data sources, RLHF (Reinforcement Learning from Human Feedback) strategies, and reasoning architectures. Claude-series models may favor certain coding styles or design patterns during code generation, while Codex based on o3/o4-mini follows different reasoning paths. One model's blind spots during code generation may be precisely another model's strengths — this is the theoretical basis for why multi-model cross-validation can effectively reduce bug rates.
This approach can be extended further — for example, you could also try using Gemini 2.5 Pro for code review, forming a multi-model cross-validation system. The differences in training data and reasoning approaches across AI models are precisely the underlying reason why cross-validation works.
Summary and Reflections
The core philosophy of this workflow can be summarized as: let the builder build, let the reviewer review, and eliminate blind spots through cross-validation.
The specific process is:
- Claude Code analyzes the project → Creates flowcharts, understands the full system
- Claude Code executes development tasks → Completes code writing and modifications
- Claude Code generates a code review document (MD format) → Records requirements and modification details
- Codex reviews the code → Identifies potential bugs and issues
- Claude Code fixes bugs → Makes repairs based on review findings
- Codex reviews again → Loop until bug-free
The value of this methodology goes beyond reducing bug rates — it reveals an important principle: at the current level of AI capabilities, no single tool can perfectly handle all tasks. The right combination of tools and well-designed processes are the key to improving efficiency. This aligns with the "Separation of Concerns" design principle in software engineering — decomposing complex tasks into different responsibilities, assigning each to the most suitable role, and ultimately achieving collaboration through standardized interfaces (in this case, MD documents).
As LLM token limits continue to increase, the capability boundaries of AI coding will keep expanding. But the mindset of "cross-validation" will never become obsolete, regardless of the era.
Related articles
Claude Code Desktop Status Capsule: An Open-Source Widget for Real-Time AI Coding Status Monitoring
An open-source desktop status capsule that monitors Claude Code's idle, working, and completed states in real time, with multi-conversation management, memos, and music control for developers.

GPT-5.2 Codex vs Opus 4.5 Hands-On: A Comprehensive Comparison of Coding Ability, Speed, and Developer Experience
Hands-on comparison of GPT-5.2 Codex vs Opus 4.5 across frontend generation, physics simulation, 3D scenes, and code refactoring, with practical selection advice.
Deep Dive into the Three AI Programmin…
Deep Dive into the Three AI Programming Frameworks: The Right Way to Do Specification-Driven Development
Deep dive into the three frameworks of Specification-Driven Development (SDD) for AI programming: Blueprint, Execution Flow, and Change Records — solving the problem of AI code going off the rails.