Claude Code Codex Plugin Integration: A Practical Guide to Dual-AI Adversarial Review for Better Code Quality
Integrate OpenAI's Codex into Claude Code for dual-AI adversarial code review that catches what single-model reviews miss.
This guide explains how to integrate OpenAI's Codex plugin into Claude Code to enable a dual-AI adversarial review workflow. By having an independent model critically examine AI-generated code across seven attack surfaces—including race conditions, version skew, and observability gaps—developers can break the self-consistency bias inherent in single-model workflows and significantly improve code quality at minimal additional cost.
Introduction: When Competitors Become the Best Partners
The competitive landscape of AI programming tools is undergoing a subtle shift. OpenAI's Codex can now be integrated into Anthropic's Claude Code as a plugin—meaning you can invoke the programming capabilities of two top-tier AI companies within the same workflow. This not only provides Claude Code users with an alternative when facing usage limits, but more importantly, it pioneers a brand-new code quality assurance paradigm: "dual-AI adversarial review."
The emergence of this cross-platform integration reflects how the AI tool ecosystem is evolving from closed competition toward open interoperability. Similar to the development of IDE plugin ecosystems—when VSCode allowed arbitrary third-party extensions, innovation across the entire developer tools market accelerated significantly. Today, the AI programming assistant space is experiencing a similar paradigm shift: boundaries between tools are becoming blurred, and developers are gaining unprecedented freedom to combine them.
Why Use Codex in Claude Code?
The Reality of Usage Limits
Developers using Claude Code commonly face a pain point: regardless of whether you're subscribed to Anthropic's Pro plan or the 5x Max tier, quota gets consumed extremely fast—especially given some bugs in the CLI. Codex offers much better cost-effectiveness—the dollar-to-token conversion shows a clear cost advantage.
To understand the severity of this issue, you need to understand Claude Code's token consumption mechanism. When Claude Code runs in CLI mode, each interaction consumes not only the tokens from user input, but also system prompts, conversation history in the context window, and substantial hidden tokens generated by tool calls (such as file reads and terminal command execution). A seemingly simple request like "refactor this function for me" might actually consume tens of thousands of tokens—because Claude needs to read related files, understand the project structure, generate code, and then verify the results. Anthropic's Max plan (the 5x usage version at $100/month) often hits its limits within a week under heavy use. In comparison, OpenAI's Codex is accessible with a ChatGPT Pro subscription ($20/month) and offers relatively generous token quotas, making it an economically rational choice to offload repetitive review tasks to Codex.
If you're already paying $20/month for ChatGPT, bringing Codex into Claude Code costs virtually nothing extra. It's essentially finding a middle ground between the $20 and $100 subscriptions.
Installation and Configuration Is Extremely Simple
The installation process takes just a few steps: run the plugin installation command, select the user scope, reload plugins, and finally run the Codex Setup command to complete authentication. Usage is tied directly to your ChatGPT account, and even free accounts appear to work.
Core Feature: The Power of Adversarial Review
The Difference Between Standard and Adversarial Review
The Codex plugin in Claude Code offers two main code review modes:
Standard Review is a neutral, read-only mode where Codex objectively examines the code and provides conventional feedback.
Adversarial Review is the real highlight. Its core approach is: tell Codex to "assume the code is flawed by default," then scrutinize Opus-generated (or other AI-generated) code with an extremely critical eye. This method works because Anthropic themselves acknowledge in their engineering blog that AI models tend to perform poorly when evaluating their own code.
The theoretical foundation of adversarial review traces back to the "Red Teaming" tradition in information security. In military and cybersecurity domains, the red team's responsibility is to stand in the attacker's perspective and actively seek vulnerabilities in defensive systems. After this concept was introduced into AI safety research, it evolved into a paradigm where one model specifically challenges another model's output. Multiple studies in 2024 demonstrated that LLMs exhibit significant "self-consistency bias"—when asked to evaluate their own generated content, models tend to give inflated ratings because their evaluation logic shares the same weights and preferences as their generation logic. Introducing a completely independently trained model (such as using OpenAI's model to review Anthropic's output) effectively breaks this bias, since the two models differ fundamentally in training data, RLHF preferences, and architectural design.
Seven Attack Surface Coverage Areas
Adversarial review constructs specialized adversarial prompts covering seven key attack surfaces:
- Authentication Security — Detecting identity verification and authorization vulnerabilities
- Data Loss Risk — Identifying logic flaws that could lead to data loss
- Rollback Capability — Verifying whether the system supports safe rollback
- Race Conditions — Identifying potential conflicts in concurrent scenarios
- Dependency Degradation — Checking compatibility risks of third-party dependencies
- Version Skew — Discovering version inconsistencies in configurations or interfaces
- Observability Gaps — Evaluating whether logging and monitoring coverage is adequate
Several of these concepts deserve deeper explanation. Race Conditions are among the most insidious defects in concurrent programming: when two or more operations need to execute in a specific order but the system fails to guarantee that order, unpredictable behavior results. For example, if two users simultaneously modify the same database record without proper locking mechanisms, the final state could be the result of either modification—or even a corrupted intermediate state. These issues are nearly impossible to reproduce in local testing and only surface under high-concurrency production scenarios.
Version Skew refers to situations in distributed systems where different components are running incompatible versions. In microservice architectures, when an API producer updates its interface contract but consumers are still using the old version, version skew occurs. This is especially common during progressive deployments (like canary releases), where old and new service instances run simultaneously, potentially causing data format mismatches or behavioral inconsistencies.
Observability Gaps are a core concern in modern DevOps practices. Observability is built on three pillars: Logs, Metrics, and Traces. When critical paths in a system lack coverage from any of these three, operations teams cannot quickly identify root causes during failures, dramatically increasing Mean Time To Recovery (MTTR). AI-generated code is particularly prone to neglecting this because observability code doesn't affect functional correctness but is critical for production operations.
These are all the kinds of issues that "lurk beneath the surface" and cause serious consequences once pushed to production. After the review completes, Codex outputs structured JSON results containing severity ratings (Critical/High/Medium/Low), issue descriptions, affected files, specific code, and remediation suggestions.
Real-World Testing: Codex vs. Opus Head-to-Head
Test Subject
The test project was a Twitter engagement research bot. This web application's features include: scanning AI-related tweets every 30-45 minutes, built-in quality filtering and scoring system, integrated Softmax selection mechanism, Supabase connection for deduplication, Telegram push notifications, and AI-assisted reply functionality. While not extremely complex, it involves multiple system integrations, making it ideal material for testing code review capabilities.
The Softmax selection mechanism mentioned here deserves explanation. Softmax is a mathematical function that converts an arbitrary vector of real numbers into a probability distribution, widely used in neural network output layers. In this tweet filtering scenario, Softmax's role is to convert each tweet's quality score into a selection probability—high-scoring tweets have a greater chance of being selected for engagement, but low-scoring tweets also retain some chance of being selected. This "soft" selection strategy (compared to simple Top-K hard truncation) prevents the system from falling into a pattern of only focusing on top content, maintaining diversity and exploration in interactions. This parallels the ε-greedy strategy in reinforcement learning, striking a balance between exploitation and exploration.
Supabase is an open-source Firebase alternative that provides PostgreSQL databases, real-time subscriptions, authentication, and storage backend services. In this project, it's used to store processed tweet IDs for deduplication—ensuring the bot doesn't repeatedly engage with the same tweet.
Codex's Review Results
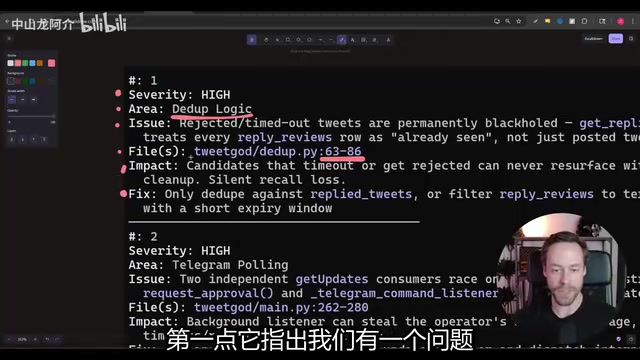
Codex performed an adversarial review of the entire codebase and identified 4 high-severity issues:
- Deduplication logic flaws
- Telegram polling handling concerns
- Schema Drift
- Dashboard build issues
Schema Drift is an important concept in data engineering, referring to the gradual divergence between the actual state of database table structures, API response formats, or configuration files and the structures assumed in the code. For example, the Twitter API might add new fields or modify existing field types in an update, but the application code still parses data according to the old structure. This divergence usually doesn't cause immediate crashes (since most parsers ignore unknown fields), but can lead to data loss or logic errors silently accumulating in the system until they collectively explode at some critical point.
Opus's Review Results
Opus was then asked to perform an adversarial review of the same codebase, with interesting results:
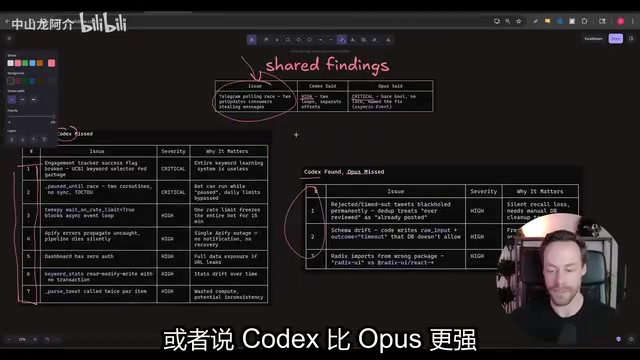
- Shared findings: Both identified the Telegram-related issue—Codex labeled it "High," Opus labeled it "Critical"
- Opus-exclusive findings: Discovered 7 additional high-priority or critical issues that Codex missed
- Codex-exclusive findings: Found 3 issues that Opus missed
How to Interpret These Results?
This comparison is highly instructive. Does Opus finding more issues mean it's stronger? Or does Codex's focus on 4 core issues—without leading developers down irrelevant paths—actually provide more practical value?
The answer is probably: neither is the point. The real value lies in introducing a "second pair of eyes." Using the same AI system throughout the entire process of planning, generation, and evaluation has a fundamental flaw. Now we can very easily introduce Codex as an independent reviewer, breaking the limitation of "grading your own homework."
This finding aligns closely with the long-standing "Independent Verification and Validation" (IV&V) principle in software engineering. NASA strictly enforces IV&V in aerospace software development—the team writing the code and the team verifying it must be completely independent, even using different toolchains and methodologies. The underlying logic is: if the verifier shares the same mental models and assumptions as the developer, systematic biases introduced during development will be inherited as-is during verification rather than being discovered. Mapping this principle to AI programming: Claude Opus's "mental model" when generating code (its training data distribution, RLHF preferences, reasoning patterns) is the same as when it reviews code, so it tends to consider its own output reasonable. Introducing a model with completely different architecture for review essentially implements IV&V in the AI workflow.
Recommended Practical Workflow
Based on test results, an efficient dual-AI collaboration workflow can be structured as follows:
- Use Opus for planning and code generation — leveraging its powerful reasoning and coding capabilities
- Use Codex for adversarial review — providing an independent perspective to discover potential issues
- Synthesize both results for fixes — combining strengths to maximize code quality
The design philosophy behind this workflow draws from the research tradition of Multi-Agent Systems. In multi-agent architectures, different AI agents are assigned different roles, objectives, and even "personalities," collaborating or competing to accomplish complex tasks. In recent years, this paradigm has gained widespread attention in AI research—from Google's "Society of Mind" experiments to Microsoft's AutoGen framework, all exploring how interactions between multiple AI agents can surpass the capability ceiling of any single model. The Claude Code + Codex combination can be seen as this trend landing in practical development tools: one agent is responsible for creation, another for criticism, and the tension between them produces output more reliable than either single agent alone.
Additionally, you can use the Codex Rescue command to have Codex independently complete coding tasks, just as you would normally use Opus. This serves as a great fallback when Anthropic quotas are exhausted.
Fine-Grained Control Over Review Scope
While the prompts used in testing were quite open-ended, according to examples on GitHub, you can very specifically define the scope and focus of Codex's review, including adjusting effort level parameters for more granular control. For example, you can focus the review on specific directories, specific types of security issues, or perform incremental reviews on the most recent Git commit changes rather than scanning the entire codebase every time.
Conclusion
Integrating Codex into Claude Code essentially adds a powerful new tool to the AI programming toolbox. Its value isn't about "Codex is stronger than Opus" or vice versa—that comparison misses the point. The real breakthrough is: we can now have two independent AI systems challenge and review each other, making the whole greater than the sum of its parts.
From a broader industry perspective, this cross-platform AI collaboration model may foreshadow the future direction of development tools. Just as modern software development doesn't rely on a single programming language or cloud provider, AI-assisted development in the future is unlikely to be locked into a single model provider's ecosystem. Developers will increasingly play the role of "AI orchestrators"—selecting the most suitable model combinations based on different task characteristics and designing interaction protocols between them. Claude Code's plugin architecture provides an early but viable implementation path for this future.
For developers already using Claude Code, there's virtually no downside: installation is simple, cost is low (potentially even free), yet it can significantly improve code output quality. In the AI programming space, "adversarial review" may be one of the most noteworthy practical patterns to emerge recently.
Key Takeaways
Related articles
AI Agent Learning Roadmap: A Four-Step Practical Guide from Zero to Job-Ready
A proven AI Agent learning roadmap covering four core elements, mainstream architecture patterns, multi-agent collaboration, and hands-on projects to go from zero to job-ready in three months.

HarmonyOS 7 Developer Beta Launches: A Deep Dive into System-Level Transformation for the Agent Era
HarmonyOS 7 developer Beta launches, claiming to be the world's first AI-native OS. Deep analysis of Xiaoyi Agent, StarShield security, Galaxy Interconnect, and the OS AI competition landscape.
Deploying a Multimodal AI Agent Locally on a 3080Ti: VRAM Management and a Deep Dive into All Five Modules
A detailed guide to deploying a multimodal AI Agent on a 3080Ti with 12GB VRAM, covering LLM, STT, TTS, image and video generation module selection, dynamic VRAM loading, and real-world performance.