Claude Code vs Codex: A Deep Comparison — Who Wins When the Tech Converges
Claude Code vs Codex: when features converge, reliability becomes the ultimate differentiator.
Claude Code and OpenAI Codex are converging on nearly identical features — from autonomous loops to sub-agent architectures to "Dreaming" memory mechanisms. Despite Claude Code's 18:4 early innovation lead and 80-day head start, Codex closes gaps in just 11 days. Market data shows Codex leads in total users (5M vs 2M) while Claude Code dominates hardcore developer adoption on NPM. As features reach pixel-level parity, reliability and engineering stability emerge as the true decisive factors.
The two most talked-about AI coding tools today — Claude Code and OpenAI Codex — are locked in a head-to-head showdown. This isn't just a feature checklist comparison; it's a paradigm battle over the future of AI-assisted programming. This article breaks down the ultimate face-off across four dimensions: first-mover advantage, technical convergence, market landscape, and the decisive factors for the endgame.
The Starting Line: The Strategic Value of an 80-Day Head Start
Claude Code made an extremely smart strategic move — launching an agent-based coding tool first in the terminal environment that developers rely on most. "Agent-based" represents the third-generation paradigm shift in AI-assisted programming. The first generation was simple code completion (like early GitHub Copilot), the second was conversational coding assistants (like ChatGPT writing code), and the third is autonomous agents capable of planning, executing, and verifying on their own — understanding high-level programming intent, breaking down tasks independently, writing code, running tests, fixing bugs, and forming a complete closed-loop workflow. Claude Code's decision to debut in the terminal was no accident. The terminal is the professional developer's core workspace, offering direct access to the file system, script execution, Git, and other toolchains — far more system-level control than any web interface.
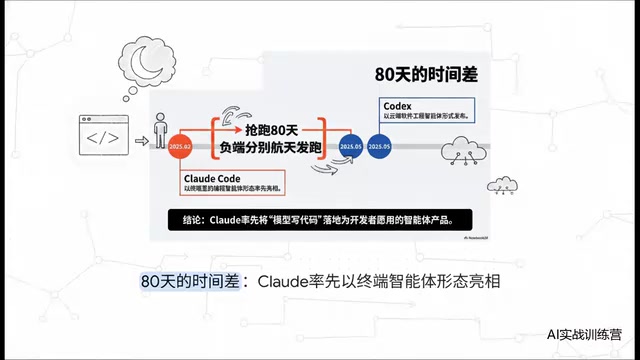
With this single move, Claude Code secured a full 80-day head start. In the fast-moving AI space, 80 days means nearly three months of open runway, during which Claude Code became the go-to tool for virtually every early-adopter developer.
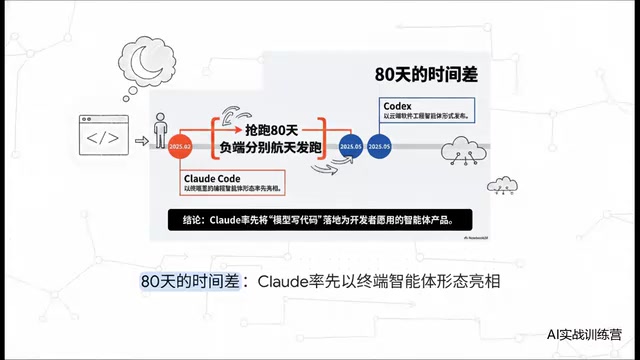
Looking at the early innovation scoreboard, Claude Code posted a staggering 18:4 lead. From headless scripting to context compression, Claude claimed first-mover status on nearly every key feature — a truly dominant early performance.
But standing on the other side is OpenAI. Codex demonstrated formidable engineering catch-up capability: whether it was autonomous goal-setting logic or multi-agent parallel processing, once Codex identified a gap, both critical technical counterattacks took just 11 days. The hard-won first-mover advantage was being erased at a pace measured in days.
Pixel-Level Feature Alignment: Technical Convergence or Mutual Borrowing?
As the catch-up pace accelerated, a fascinating phenomenon emerged — the two tools' "answer sheets" started looking increasingly alike.
Highly Consistent Self-Driving Loop Logic
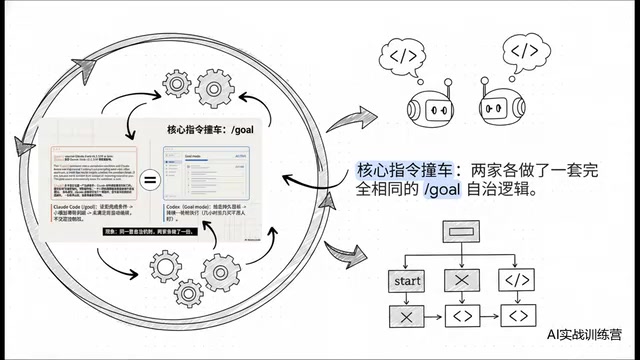
Most notably, Claude Code and Codex arrived at nearly identical self-driving loop logic: set a goal, use a small model each round to automatically determine whether conditions are met, continue executing if not, all without handing control back to the user.
The technical prototype of this Autonomous Loop can be traced back to closed-loop control systems in cybernetics. In the AI coding context, the workflow goes like this: a large model understands and sets the goal, then generates an execution plan and implements it step by step. After each execution round, the system calls a lightweight evaluation model (typically one with fewer parameters and faster inference) to judge whether the current output meets the preset conditions. If not, the system automatically enters the next iteration. The key innovation here is shifting the cognitive burden of "deciding whether it's done" from humans to the AI itself, allowing developers to issue a high-level instruction and then completely step away. This autonomous mechanism was independently developed by both companies, yet the underlying logic aligned down to the finest details.
Sub-Agent Architecture: A Shared Conclusion
When facing complex tasks, both sides remarkably abandoned the monolithic approach and converged on a similar sub-agent architecture — decomposing tasks layer by layer and distributing execution.
The sub-agent architecture draws from the design principles of distributed systems and microservices. The main agent (Orchestrator) acts as a dispatch center, responsible for task decomposition, resource allocation, and result aggregation, while each subtask is independently handled by a dedicated sub-agent. The advantages are multifold: different subtasks can execute in parallel, dramatically reducing total time; each sub-agent faces less context window pressure, mitigating the risk of performance degradation in large models under ultra-long contexts; a single subtask failure doesn't crash the whole system, allowing targeted retries. This aligns perfectly with the classic "divide and conquer" principle in software engineering, which also explains why both companies independently arrived at the same architectural choice — it's fundamentally the engineering-optimal solution for complex coding tasks.
Even more noteworthy, the two companies have begun jointly defining industry standards. Anthropic introduced the lightweight SKLD format — a configuration spec for defining an AI coding agent's behavioral guidelines, code style preferences, and task-handling rules within a specific project, similar to what .editorconfig or .eslintrc is for code formatting tools, but targeting AI agents. Codex promptly adopted the exact same filename and format specification, meaning developers can use a single config file to work with both platforms, dramatically reducing migration costs. This kind of standards convergence between competitors is not uncommon in tech history — USB interfaces, HTML standards, and containerization specs (OCI) all went through similar processes, typically signaling a technology domain's transition from wild growth to maturity. The rules governing plugin ecosystems and routine task handling are being jointly defined by these two giants.
The most intriguing part is the "Dreaming" memory mechanism — both companies even "collided" on the feature name, both exploring how to let AI self-reflect and organize memories in the background. This mechanism draws inspiration from the neuroscience principle of how the human brain organizes and consolidates memories during sleep. In the context of AI coding tools, it refers to the agent automatically reviewing previous coding sessions during inactive periods (when the user isn't actively interacting), extracting key patterns, summarizing project context, identifying recurring error types, and compressing these "experiences" into long-term memory. This addresses a core pain point of large language models — limited context windows and lack of persistent memory between sessions. Through background self-reflection, the AI can quickly "recall" project context at the start of the next session without requiring developers to repeatedly provide the same contextual information, essentially simulating a form of continuous learning.
The high degree of overlap in these technical details points to a deeper conclusion: This isn't simple imitation — it's the inevitable convergence of AI coding agents in form and function. The optimal paths for solving specific programming problems may truly be limited to just a few.
Developers Vote with Their Feet: The Real Landscape Behind Market Data
As the tools grow increasingly similar, market data paints a strikingly divided picture.
The Classic Tug-of-War Between User Volume and Developer Quality
On one hand, Codex leverages its massive ecosystem to reach 5 million weekly active users, while Claude Code sits at 2 million. But on NPM — the platform representing hardcore developer environments — Claude Code's 30-day download count hit 46.3 million, more than three times that of Codex.
NPM (Node Package Manager) is the core package management platform for the JavaScript/Node.js ecosystem and one of the world's largest software registries, hosting over 2 million packages. NPM download counts are considered a key indicator of "hardcore developer" adoption because installing tools via NPM means developers are working in local command-line environments rather than using graphical interfaces or web apps. These developers typically have stronger technical backgrounds and are more inclined to deeply integrate tools into their development workflows.
This creates a classic dynamic: The general public gravitates toward Codex, while the most hardcore, low-level code enthusiasts are holding the line with Claude Code.
The Reliability Problem: Even Loyalists Can Waver
There's a landmark event in the community — Simon Last, co-founder of Notion and once a die-hard Claude fan, eventually moved his team to Codex. The reason boils down to three words: reliability issues. In his own words, Claude Code sometimes "lies" — claiming to be executing a task while nothing is actually happening in the background.
AI hallucination refers to large language models generating content that appears plausible but is actually incorrect or fabricated. In everyday conversation, a hallucination might be a harmless factual error; but in coding scenarios, the damage is amplified exponentially. An AI tool that "claims to be executing but actually isn't" can lead developers to believe code has passed tests, files have been modified, or deployments have completed, causing them to continue building on a faulty foundation and ultimately triggering cascading failures that are nearly impossible to trace. In production environments, a tool that's 99.9% accurate but lies 0.1% of the time can be far more dangerous than one that's 95% accurate but never conceals its mistakes. In the world of writing code, an AI tool that hallucinates is worthless — stability is king.

Power Users Push the Limits
For truly passionate users, a tool's ceiling is limited only by imagination. Peter Stenberger, creator of OpenCloud, has fully switched his daily productivity workflow to the Codex command line — pulling up a 3×3 terminal grid on his monitor and running 3 to 8 Codex instances in parallel simultaneously. This extreme productivity squeeze also demonstrates that advanced developers have built substantial trust in Codex's stability. This multi-instance parallel workflow is made possible precisely by the sub-agent architecture discussed earlier — each terminal instance can independently handle different task branches without interference, with the developer performing integration at a higher level.
The Endgame: Decisive Factors in the Age of Feature Convergence
Having examined the technical evolution and market competition, we arrive at the most critical question: What ultimately determines the winner?
The Competition Shifts from "Does It Exist?" to "Is It Stable?"
In the past, choosing an AI coding assistant was mainly about the feature checklist — can it write code, can it help find bugs? But now all core features are converging toward pixel-level alignment. Any feature you have today, I'll have in a few days. No single feature qualifies as a moat anymore.
The real battlefield has shifted to: Whose overall engineering environment runs more robustly, whose user experience is smoother, and whose ecosystem connections are more reliable. The competitive dimension has upgraded from "does this feature exist" to "how far can this feature perform stably at its limits." This shift in competitive dynamics is a recurring pattern in the tech industry — the AWS, Azure, and GCP battle in cloud computing ultimately wasn't about who launched a service first, but about who had higher SLAs (Service Level Agreements), shorter downtime, and broader global node coverage. AI coding tools are heading down the same path.
How Should Developers Choose?
This is a question worth deep reflection for every developer: When all AI coding tools have roughly the same interface, identical features, and even the same underlying architecture — when feature parity becomes the absolute norm — what is the core factor that ultimately determines your choice?
Is it past usage habits? Trust in a particular company? Or even a 0.1% difference in error rate?
The answer may vary from person to person, but one thing is becoming increasingly clear: In the age of AI coding tool convergence, reliability and engineering stability will be the ultimate decisive factors. Features can be caught up on, ecosystems can be built, but the sense of stability that lets developers place unconditional trust in a tool at critical moments — that is the true moat.
Key Takeaways
Related articles
What Is Claude Code? Five Key Differences from Regular AI Chatbots
Explore the five key differences between Claude Code and regular AI chatbots like ChatGPT and DeepSeek — from interaction, context, execution, memory, to tool integration.
5 Daily Claude Code Tips: Let AI Interrogate You Instead
5 daily Claude Code tips: Grill Me for requirements, Brainstorming for architecture, Writing Plan for execution, TDD for testing, and Debugging for precise fixes — a complete AI coding workflow.

AITS Hands-On Review: API + Web + App Automated Testing All in One Platform
In-depth review of AITS: an AI testing platform covering API automation, Web automation, App real-device cloud testing, and performance testing end-to-end.