Auto-Generating CRUD Code with Claude Code: A Practical Guide to Writing Skill Files
Auto-Generating CRUD Code with Claude …
Use Skill files and MCP to let Claude Code generate CRUD code from existing table structures
This article explains how to use Claude Code with a MySQL MCP server and Skill files to auto-generate CRUD code. The core idea is to design table structures yourself, let AI read database metadata via MCP, then use carefully crafted Skill files — covering pagination strategies, test isolation, and code layering — to guide AI in generating high-quality Model/DAO/Service code. The author also honestly notes that for standardized CRUD scenarios, AI doesn't offer significant efficiency gains over mature framework tools.
Introduction: Why You Shouldn't Let AI Design Your Table Structures
Many developers, when using AI programming tools, tend to dump entire requirements at the AI and expect it to handle everything from table design to code generation in one shot. But in real-world projects, this approach often backfires — AI-generated table structures may have too many or too few fields, forcing you into endless rounds of tweaking and wasting significant time.
A better approach is: design the table structures yourself, then let AI generate code based on those structures. Table structures represent your deep understanding of the business domain — something AI can't replicate in a short time. This article walks you through how to use Claude Code with MCP and Skill files to achieve high-quality automated CRUD code generation.
Two Core Prerequisites: MCP and Skill Files
Configuring the MySQL MCP Server
To enable Claude Code to read table structures from your database, you first need to configure a MySQL MCP (Model Context Protocol) server.
MCP is an open protocol launched by Anthropic in late 2024, designed to establish a standardized communication bridge between AI models and external data sources or tools. Before MCP, every AI tool that needed to access external systems (databases, APIs, file systems, etc.) required custom integration code, creating a massive "M×N" compatibility problem. MCP solves this by defining a unified client-server architecture, allowing AI applications (clients) to communicate with any number of MCP servers through a standard protocol, where each server encapsulates access to a specific external resource. In this article's scenario, the MySQL MCP server acts as a middleware layer between Claude Code and the database, enabling the AI to execute SQL queries and retrieve table structure metadata just like a developer would — without directly exposing database credentials to the model itself.
The configuration file is located at .claude.json in the user's home directory. The key settings include:
- command: The startup command for the MCP server
- args: Startup arguments
- env: Environment variables, primarily for database connection details (server address, port, database name, username, password)
Once configured, Claude Code can connect directly to your MySQL database via MCP and execute operations like SHOW TABLES to retrieve table structure information.
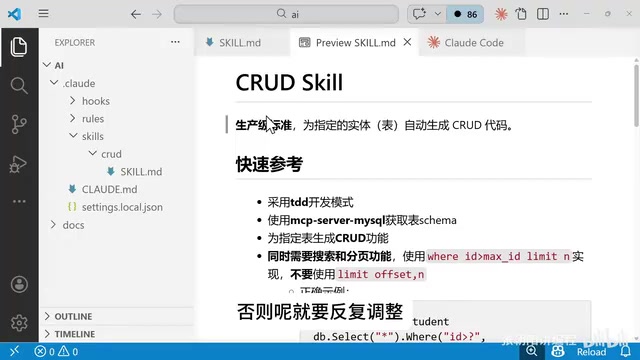
Writing the CRUD Skill File (The Core of Everything)
The Skill file is the soul of the entire workflow. A well-written Skill file can produce code that passes on the first try; a poorly written one leads to endless adjustments.
Skill files are essentially a structured Prompt Engineering practice. Traditional Prompt Engineering typically involves writing instructions ad hoc during conversations, while Skill files persist and modularize these instructions, storing them in the project directory under version control. This approach aligns with the popular "System Prompt" concept but goes further — it supports keyword-triggered, conditional activation, similar to event-driven patterns in programming. The quality of Skill files directly determines the predictability of AI output, which is why the industry has gradually embraced the "Prompt as Code" philosophy: treating prompts as code assets subject to version control, code review, and continuous optimization.
Skill files are placed at .claude/skills/crud/skill.md in the project root directory and are automatically loaded when Claude starts. The file uses a keyword trigger mechanism — the Skill is activated only when user input contains keywords like "CRUD" or "entity generation."
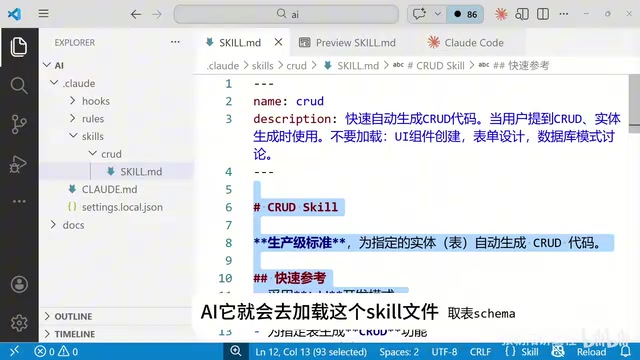
The Skill file contains the following key directives:
- Test-Driven Development mode: Write tests first, then code
- Pagination strategy: Explicitly requires
WHERE id > maxId LIMIT Ninstead ofLIMIT offset, N, because the latter's performance degrades dramatically as the offset grows - Connection pool sharing: All DAO layer code shares a single database connection pool
- Test isolation: Uses SQLite in-memory databases for testing, avoiding contamination of the production MySQL database
- Code layering: Generates Model, DAO, and Service layers, avoiding redundancy
Understanding the Pagination Performance Problem in Depth
You might not have noticed, but to prevent the AI from misunderstanding what pagination optimization means, the Skill file explicitly includes both correct and incorrect examples. This "hand-holding" approach for teaching AI is extremely practical and represents a core technique in Skill file writing.
The traditional LIMIT offset, N pagination method has a serious deep-pagination performance problem in MySQL. The root cause is that MySQL's InnoDB storage engine, when processing such queries, must scan and discard the first offset rows even if only N records need to be returned. For example, LIMIT 1000000, 20 actually requires scanning 1,000,020 rows of data, and query time grows linearly or even super-linearly as the page number increases. In contrast, the WHERE id > maxId LIMIT N cursor-based pagination approach (also known as Keyset Pagination or the Seek Method) leverages the ordered nature of the primary key index's B+ tree, allowing the database to locate the starting position directly via the index. The time complexity remains O(log N + M), where M is the number of returned records. This optimization is especially significant for tables with millions of rows or more, reducing query times from several seconds to milliseconds. However, cursor-based pagination has limitations: it doesn't support random page jumping and can only implement sequential "previous/next page" navigation, making it suitable for feeds, list loading, and similar scenarios.
Live Execution Walkthrough
One Prompt Triggers Complete CRUD Generation
With the preparation done, you only need to type a short prompt in Claude Code:
生成CRUD代码
Claude automatically matches the keywords in the Skill file and executes the predefined workflow step by step:
- List all tables: Connects to the database via MCP and executes
SHOW TABLES - User selects tables: Interactive multi-select — for example, choosing the
userandstudenttables - Choose tech stack: Asks which language and framework to use — here, Go + Gin + GORM was selected
- Generate code table by table: From bottom to top — Model → DAO → Service → Test
- Run tests and auto-fix: Automatically corrects code when issues are found
How Good Is the Generated Code?
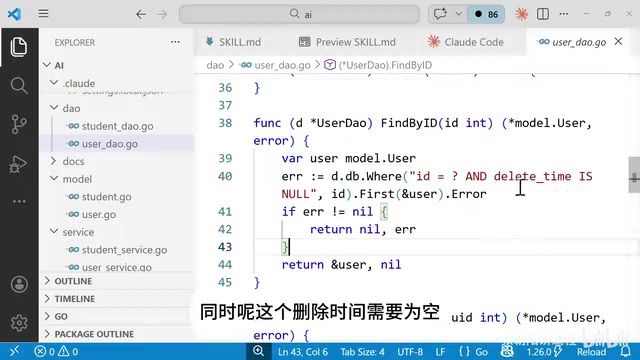
After manual review, the generated code quality is quite impressive:
Model layer: Structs include complete JSON tags and GORM tags, with each field properly mapped and the actual table name specified.
DAO layer:
Create: Callsgorm.DB.Createto insert dataUpdate: Calls theSavefunction to updateDelete: Soft-deletes by IDFindById: Automatically filters deleted records (deleted_at IS NULL) during queries- Pagination: Correctly uses the high-performance
id > maxIdpagination method, with support for keyword fuzzy search and city exact filtering
Service layer: Encapsulates Request structs (with JSON tags), handles parameter conversion before calling the DAO layer, with clear separation of responsibilities.
Test code: Uses SQLite in-memory databases, creates tables via AutoMigrate, tests from the Service layer down, covers all CRUD operations, and each assertion verifies whether fields match expectations.
Technical Details of the Test Isolation Strategy
Test-Driven Development (TDD) is a software development methodology systematized by Kent Beck in 2003. Its core cycle is "Red-Green-Refactor": first write a failing test (Red), then write the minimum code to make it pass (Green), and finally refactor to keep the code clean. In this article's AI code generation scenario, TDD serves not just as a development method but as a quality verification mechanism — AI-generated code must pass predefined tests to be considered complete.
Using SQLite in-memory databases (:memory: mode) for test isolation is a common practice in the Go ecosystem. The lifetime of an SQLite in-memory database is bound to the process — data is automatically destroyed when tests finish. This avoids dependency on a MySQL test database and data residue issues, while dramatically improving test execution speed (memory operations are orders of magnitude faster than disk I/O). The GORM framework natively supports the SQLite driver, and combined with AutoMigrate, it can automatically create tables from Go structs, enabling the same codebase to seamlessly switch between MySQL and SQLite.
Finally, running go test -v ./ shows all tests passing.
A Sober Look at Efficiency and Cost
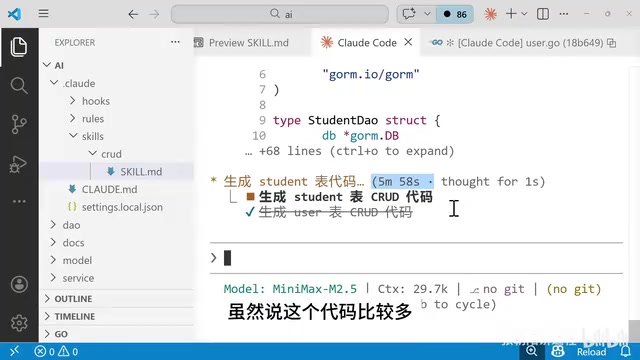
The entire process took about 7.5 minutes. The first table took longer (about 5 minutes), while the second table, benefiting from the template reference, took less than 2 minutes.
But objectively speaking, manual work is actually faster for simple CRUD code — since most of it is just copy-paste with minor modifications. Not to mention that the Go ecosystem already has frameworks like go-zero and GoFrame, and Java has Spring and similar tools, all capable of auto-generating ORM code.
Maturity of Existing Code Generation Tools
The Go ecosystem already has several mature code generation solutions. go-zero, an open-source microservices framework by TAL Education Group, includes the goctl tool that can automatically generate complete CRUD code, routes, middleware, and more from API definition files and database DDL, covering the full chain from the interface layer to the data layer. GoFrame's gf gen dao command similarly supports reverse-generating Model, DAO, and Service code from database table structures. Additionally, GORM's official gen tool can generate type-safe query code, while sqlc takes a different approach — generating Go code from hand-written SQL. These tools have been battle-tested in production environments, produce code with fixed patterns and mature performance optimizations, and typically execute in seconds. By comparison, AI code generation's advantage lies in flexibility — it can generate non-standard code structures according to custom specifications in Skill files, adapting to a team's unique architectural conventions, which is difficult for template-based tools to achieve.
"For simple CRUD operations, AI can get the job done, but it doesn't bring any efficiency improvement over previous methods — and it costs more money."
This observation deserves serious thought. The real value of AI programming tools may not lie in this kind of formulaic CRUD generation, but rather in handling more complex business logic and non-standardized development tasks.
Key Takeaways
- Design table structures yourself: Don't let AI guess your business requirements — table structures are the precise expression of business understanding
- Make Skill files thorough: Include correct examples, incorrect examples, performance requirements, and architectural constraints — the more specific, the more accurate the AI's execution
- Test isolation matters: Use SQLite in-memory databases for testing to avoid contaminating production environments
- Be explicit about pagination performance:
id > maxIdperforms far better thanLIMIT offset— this kind of optimization knowledge needs to be manually injected into Skill files - Be realistic about AI efficiency: For standardized CRUD, AI isn't necessarily faster than mature framework tools, but the Skill file writing approach can be reused for more complex scenarios
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.