Codex Loop Patterns: The Paradigm Shift of AI Agents from One-Shot Tasks to Continuous Loops
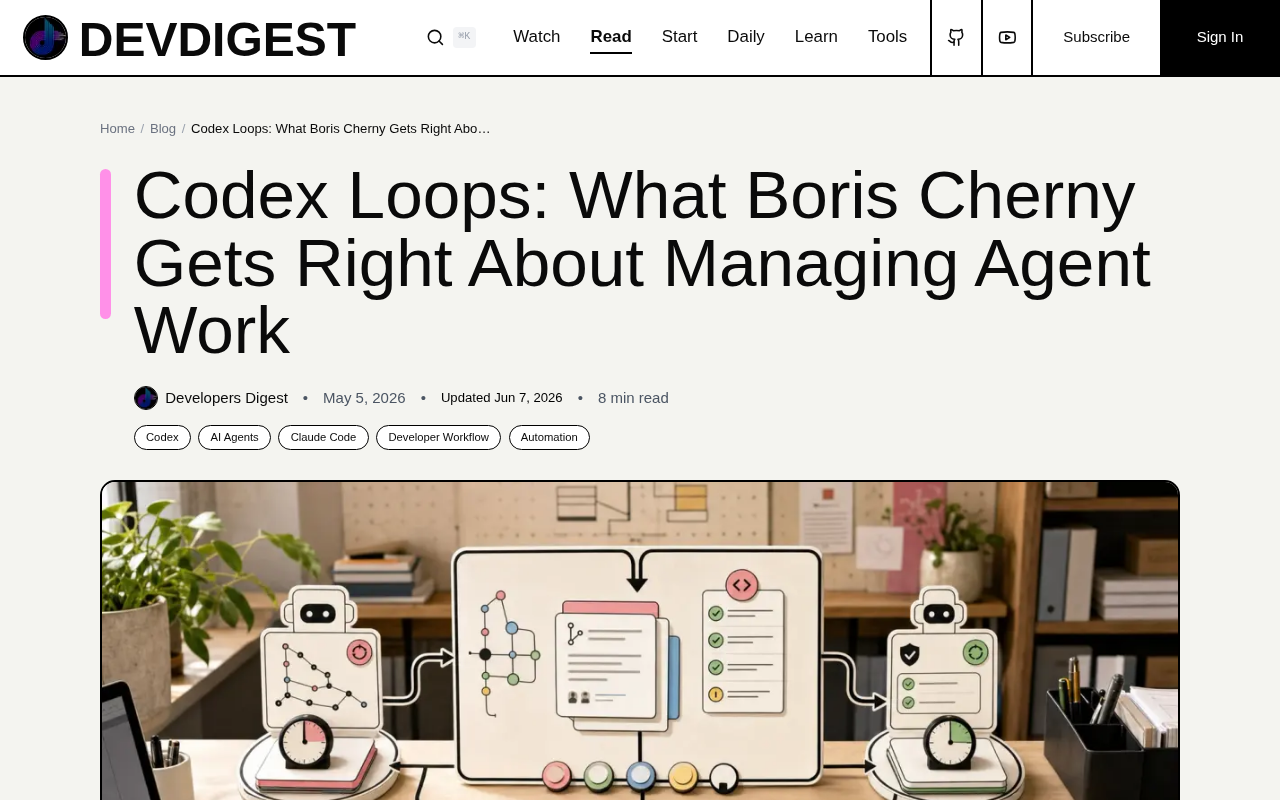
AI agents evolve from one-shot tools to continuously running engineering loops governed by clear contracts.
Boris Cherny proposes a paradigm shift for AI agents: from one-shot task execution to continuous loop-based monitoring and response. The framework defines five core loop elements (trigger, scope, budget, stop condition, reporting), introduces loop contracts for controllability, presents four practical loops (PR Babysitter, CI Health, Deploy Verification, Feedback Clustering), and addresses failure modes like resource drain and stale context.
Core Insight: From One-Shot Tasks to Continuous Loops
Boris Cherny has proposed an entirely new working model that goes beyond "AI agents writing code and submitting diffs." He runs multiple sessions simultaneously, makes heavy use of sub-agents, and relies on the /loop command to manage ongoing engineering work. This marks a significant paradigm shift in how AI agents are used — from one-shot task execution to continuous loop-based monitoring and response.
A sub-agent is an independent execution unit spawned within a primary AI agent session. Each sub-agent has its own context window and task scope, capable of handling different engineering tasks in parallel. This architecture is analogous to the process forking model in operating systems, where the main agent acts as a scheduler. The /loop command is a continuous execution directive in AI coding tools like Claude Code. It puts the agent into a watch-act loop — similar to inotifywait or a filesystem monitoring daemon in Linux — continuously detecting state changes and responding, rather than exiting after executing a single instruction.
The core insight behind this shift is that a vast amount of software engineering work isn't one-time code writing — it's continuous state monitoring and response. PRs need revisions after review, CI pipelines need attention when dependency caches expire, deployments need post-launch verification. These are fundamentally state monitoring problems, not one-time editing problems.
In distributed systems engineering, state monitoring is a classic paradigm. From Nagios to Prometheus to modern observability platforms, the engineering world has been building increasingly sophisticated monitoring-response systems. Boris positions AI agents as the new vehicle for this paradigm — essentially delegating monitoring-response tasks that traditionally required human judgment (such as responding to code reviews or performing CI failure root cause analysis) to AI agents with reasoning capabilities, rather than limiting automation to rule-based scripts. This aligns directly with the feedback control loop concept from cybernetics — sense state, assess deviation, execute correction, verify results.
Five Core Elements of Loop Workflows
A complete AI agent loop workflow consists of five core components:
- Trigger: What event initiates the loop
- Scope: The boundaries of what the loop monitors
- Action Budget: The upper limit of resources allowed to be consumed
- Stop Condition: When to terminate the loop
- Reporting Path: How results are communicated back to humans
These five elements form the foundational framework of the loop pattern. Unlike traditional one-shot agent calls, the loop pattern acknowledges the continuous nature of engineering work and provides AI agents with a structured way to operate persistently over time.
Why Loop Patterns Outperform One-Shot Agents
One-shot agents excel at bounded editing tasks — given clear inputs, they produce clear outputs. But a huge portion of real-world engineering work is state-driven:
- PR review responses: After submission, reviewers leave comments, and code needs corresponding modifications
- CI failure diagnosis: Pipelines fail due to expired dependency caches, requiring diagnosis and repair
- Post-deployment verification: After deployment, service health needs continuous validation
- User feedback processing: Feedback streams in continuously and needs clustering analysis to form actionable insights
The common characteristic of these scenarios is that they aren't "do it once and done" tasks — they're cyclical processes requiring continuous monitoring, judgment, and response. One-shot agents fall short in these scenarios, and the loop pattern fills exactly this gap.
Loop Contracts: Making Continuous AI Work Controllable
Every useful loop should explicitly define a Loop Contract containing the following elements:
- Name: A clear identifier for the loop's purpose
- Trigger Frequency: How often to check for state changes
- Scope: Which repositories, services, or systems to focus on
- Permissions: Which operations are allowed
- Budget: Maximum token or API call consumption
- Stop Condition: Under what circumstances to automatically terminate
- Reporting Mechanism: How to report progress and anomalies to humans
The value of this contract lies in making the AI agent's continuous work predictable, auditable, and controllable. A loop without a contract is like a service without an SLA — it's bound to cause problems eventually.
SLA (Service Level Agreement) is a core concept in cloud computing and SaaS. It explicitly defines metrics such as service availability, response time, and failure recovery time, along with compensation mechanisms for violations. Boris's analogy between loop contracts and SLAs reveals a deeper insight: when AI agents transition from ad-hoc tools to continuously running infrastructure, they need the same observability and accountability as human-operated services. An AI loop without a contract is like a microservice without monitoring — you don't even know it's running until something goes wrong, and afterward you can't trace the root cause.
Under the loop pattern, token budget is a critical engineering constraint. Tokens are the basic billing unit for large language models, and every API call consumes input and output tokens. Since agents run continuously, token consumption can grow linearly or even super-linearly. For example, a loop that checks PR status every 5 minutes, consuming 2,000 tokens per check, would use approximately 576,000 tokens per day. At current GPT-4-tier model pricing, this could mean several to tens of dollars per loop per day. Therefore, the budget mechanism isn't just a safety valve against runaway costs — it's a necessary constraint at the engineering economics level.
Four Loops Worth Running Immediately
PR Babysitter Loop
Monitors PR state changes, automatically responds to review comments, handles merge conflicts, and ensures PRs don't stall in the review pipeline. This is one of the most direct loops for improving a team's code delivery velocity.
In large engineering teams, the average PR (Pull Request) lifecycle often far exceeds expectations. GitHub's industry data shows that many organizations have a median time from PR submission to merge exceeding 24 hours, with a significant portion of that time wasted on waiting for review responses, handling merge conflicts, and other non-creative work. The PR Babysitter loop essentially automates PR state machine management — it monitors every state transition from "awaiting review" to "changes requested" to "approved" to "ready to merge," automatically executing the appropriate action at each transition point, thereby compressing the wait time in the PR lifecycle.
CI Health Loop
Continuously monitors CI pipeline status, diagnoses failure causes, distinguishes between code issues and infrastructure issues, and automatically fixes recoverable failures. This reduces the time developers spend investigating red CI lights.
CI (Continuous Integration) pipeline failures can be categorized as deterministic and non-deterministic. Deterministic failures are typically caused directly by code changes (e.g., compilation errors, test assertion failures), while non-deterministic failures (flaky failures) may stem from network timeouts, expired dependency caches, resource contention, or unstable third-party services. Google's engineering practice reports indicate that approximately 16% of test failures in large codebases are flaky failures. The core value of the CI Health Loop lies in automatically distinguishing between these two types of failures, preventing developers from wasting time investigating non-code-related red lights.
Deploy Verification Loop
Continuously checks service health metrics after deployment, verifies that the new version behaves as expected, and triggers alerts or rollbacks when anomalies are detected. This transforms post-deployment manual monitoring into automated surveillance.
Feedback Clustering Loop
Continuously collects user feedback, performs semantic clustering, identifies emerging problem patterns, and generates actionable insight reports. This helps product teams catch shifts in user pain points more quickly.
Failure Modes and Prevention Strategies
The loop pattern is not without risks. Boris identifies four failure modes to watch out for:
Resource Drain: Loops may continuously consume resources without producing value. Budget mechanisms and clear stop conditions are the primary defenses.
Stale Context: Loops may make incorrect judgments based on outdated context. The knowledge base of loops needs periodic refreshing to avoid repeatedly operating on expired information. This problem is especially pronounced in long-running loops — as the codebase evolves, team members change, and architectural decisions are updated, the contextual assumptions from when the loop was initialized may gradually become invalid, causing the agent to take actions that seem reasonable but are actually harmful.
No Ownership: Every loop needs a clearly designated human owner; otherwise, it becomes an unattended zombie process, quietly consuming resources with no one paying attention.
In Unix/Linux systems, a zombie process is a process that has terminated but whose parent process has not yet reclaimed its resources — it occupies a process table entry while doing no useful work. Boris's analogy of unmaintained AI loops to zombie processes precisely captures a key risk: in organizations, the cost of starting an AI loop is very low (it might take just a single command), but without clear ownership and lifecycle management, these loops accumulate like technical debt, consuming compute resources and API quotas while no one reviews whether their output still has value.
No Escalation Path: When a loop encounters problems beyond its capabilities, there must be a clear escalation path to hand the issue back to humans, rather than retrying endlessly in a dead end. This mirrors the on-call escalation policy in operations — a mature alerting system doesn't let the same person handle the same issue indefinitely but automatically escalates to a higher-tier responder after a timeout. AI loops need the same tiered response mechanism.
Trend Assessment: Loop Contracts Determine Team Competitiveness
Boris's core thesis is: Repetitive engineering work will soon be managed by AI agent loops, and the winning teams will be those with the clearest loop contracts.
This assessment deserves serious consideration. Most teams today still use AI agents in a "human initiates → agent executes → human accepts" one-shot model. The loop pattern represents the next stage — AI agents becoming part of continuously running engineering infrastructure, rather than tools invoked on an ad-hoc basis.
This transition can be compared to the evolution of cloud computing: from initially "spinning up VMs on demand to execute tasks" to "always-on containerized microservices" to "event-driven Serverless functions." AI agent usage patterns are undergoing a similar evolution — moving from "on-demand invocation" toward a "continuously running intelligent infrastructure layer." Teams with clear loop contracts are essentially building a manageable, scalable AI operations system, which aligns with the "Infrastructure as Code" philosophy from the DevOps movement.
For engineering teams, the question worth considering now is: What repetitive work on your team could be loop-ified? Can you define clear contracts for these loops? This may be a critical dimension of future engineering efficiency competition.
Key Takeaways
Related articles

AI + Java Backend Learning Roadmap: Four Stages from CRUD to Senior AI Engineer
A complete AI + Java backend learning roadmap based on Spring AI Alibaba: from prompt engineering and LLM API integration to RAG knowledge bases and Agent systems across four stages.
Agent Middleware: Adding Interceptors to Model Calls
Learn how AI Agent middleware works through two practical examples — logging and security checks. Master the Observer and Guardian design patterns to build extensible, production-grade Agents.
Why SFT Can't Fix the Root Cause of JSON Errors: How GRPO Correctness Training Breaks Through Coding Agent Bottlenecks
Analysis of why SFT can't fix coding agent JSON errors and how GRPO's binary reward signals and synchronized weight updates train directly for correctness.