Codex vs Claude Code Cost Comparison: Breaking Down the Real Reasons Behind the 10x Price Gap
Breaking down why Claude Code costs 10x more than Codex — it's not about Token pricing.
The same programming task costs $15 on Codex but $155 on Claude Code. Surprisingly, the 10x price gap isn't due to Token unit prices — Codex is actually pricier per output Token. The real difference lies in Claude Code consuming 4x more Tokens through verbose output, aggressive context loading, and repeated verification. However, this thoroughness catches subtle bugs like race conditions and produces cleaner code. The best strategy is using both tools strategically based on task requirements.
One Task, Two Bills: Where Does the 10x Price Gap Come From?
Give the same complex programming task to OpenAI's Codex and Anthropic's Claude Code, and when the bills come in: Codex costs $15, Claude Code costs $155—a full 10x difference. And this isn't a fluke; similar gaps have appeared repeatedly across multiple real-world tests.
This naturally raises the question: Is Claude Code more expensive because it's more powerful? Where exactly does this 10x price gap come from? This article breaks down the real answer from three dimensions: Token unit price, consumption volume, and working patterns.
Token Unit Price Comparison: A Counterintuitive Fact
Many people's first instinct is that "Codex is cheaper because OpenAI has lower unit prices," but pull up the official pricing tables and you'll find the opposite is true.
Before diving into the comparison, it's important to understand how Token billing works. A Token is the basic unit that large language models use to process text—roughly equivalent to 3/4 of an English word or one Chinese character. All major AI service providers charge by Token count, and input and output are priced separately. Output Tokens are typically several times more expensive than input because generating each output Token requires the model to perform a complete forward inference computation, while input Tokens can be processed in parallel, consuming far fewer computational resources than the sequential generation process. Understanding this is essential for making sense of the cost breakdown that follows.
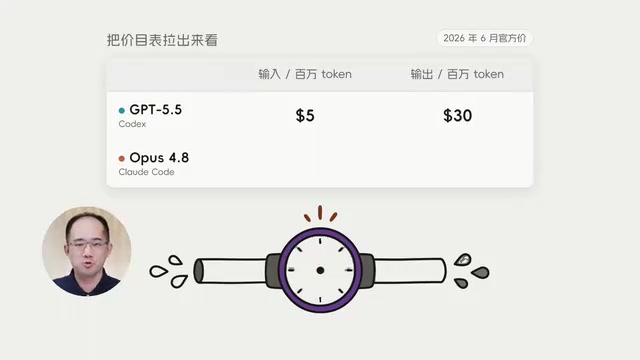
Codex's primary model is priced at $5 per million input Tokens and $30 per million output Tokens. Claude Code's primary model is priced at $5 per million input Tokens and $25 per million output Tokens.
The first conclusion is highly counterintuitive: Codex's Token unit price isn't cheaper at all—on the output side, it's actually more expensive than Claude Code. So this 10x price gap has nothing to do with unit pricing.
Token Consumption: A 4x Usage Gap
Since it's not a unit price issue, it must be about usage. Real-world test data shows that for similar complex tasks:
- Codex consumes approximately 1.5 million Tokens
- Claude Code consumes approximately 6.2 million Tokens
That's over a 4x difference. Based on feedback from different users and tasks across the community, this multiplier fluctuates between 3.2x and 4.2x, but without exception, Codex is significantly more Token-efficient.
So the question becomes: If Token consumption differs by 4x, why does the final bill differ by 10x? This requires breaking things down across three layers.
The Three Deep Layers Behind the 10x Price Gap
Layer 1: Output Style Differences — Terse and Direct vs. Talk While You Work
Codex is extremely "economical with words"—when you ask it to write code, it tends to give you a runnable result directly, with minimal explanation. Claude Code, on the other hand, is more like an engineer who "reports as it works"—it writes out its reasoning process, asks clarifying questions to confirm requirements, and explains why it chose a particular approach.
This style difference isn't accidental; it stems from fundamentally different product design philosophies at the two companies. OpenAI's Codex evolved from code completion tools (the original Codex model was the backend for GitHub Copilot), and its design DNA is "shortest path to executable code." Anthropic, from its founding, has made "interpretability" and "safety alignment" core principles. The Claude model family is trained to lean toward showing its reasoning process and proactively confirming intent. This "transparent thinking" design is further amplified in Claude Code—it doesn't just write code; it tries to help you understand why it writes code that way.

The biggest fear in AI programming is the amplification effect: tiny differences in each conversation round, compounded over dozens of iterations, can snowball into a massive Token gap. To understand the power of this amplification effect, consider a simple mathematical projection: suppose Claude Code outputs 30% more Tokens per round than Codex, and the context also expands 30% more as a result. The gap in the first round is only 30%, but by round N, the cumulative Token consumption gap approaches 1.3 to the power of N. After 10 rounds of conversation, the gap expands to roughly 3.4x; after 20 rounds, it can exceed 11x. This is why "saying a few extra words per round"—something that seems trivial—can ultimately create an order-of-magnitude chasm on the bill. One works silently, the other chats while working, and after dozens of rounds, the gap is naturally staggering.
Layer 2: Context Management Strategy — Selective Reading vs. Full Reading
Context is all the information the AI needs to read and integrate before responding—everything you've said, files it's read, command outputs, error logs, and so on. The key point is that context is also billed by Token count.
From a technical perspective, the context window is one of the core constraints of the Transformer architecture. When the model generates each new Token, it needs to perform attention calculations across all Tokens in the context, with computational complexity proportional to the square of the context length (i.e., O(n²)). This means that when context expands from 100,000 Tokens to 400,000 Tokens, not only does the Token cost quadruple, but the underlying computational resource consumption actually increases 16x. While service providers don't charge directly by computation volume, the longer the context, the higher the latency and cost per API call—which is why context management strategy has such a profound impact on the final bill.
Claude Code's reading approach is quite "thorough": every file it reads and every command it runs, it tends to stuff the entire raw content into the context, and it rarely proactively cleans up. The upside is that it stays closely aligned with your requirements and is less likely to go off track; but the cost is that if it reads a log file with tens of thousands of lines midway through, that log will continue occupying Tokens, and the context snowballs larger and larger.
Codex is much more restrained in this regard—it reads more sparingly, and context grows more slowly. So within the same context window size, Codex achieves higher effective Token utilization efficiency.
Layer 3: Working Personality — Straight to the Goal vs. Repeated Verification
Claude Code is more "meticulous": for the same bug, it will proactively check several related files, verify multiple times, and repeatedly confirm whether it got things right. The cost of this thoroughness is that every step burns Tokens.
Codex is more "goal-oriented": once it has a clear direction, it acts immediately, rarely explains, rarely takes detours, and rarely asks you for repeated confirmation.
Stack these three layers together—more verbose output × more bloated context × more frequent verification—and the 4x Token gap, after being weighted by unit prices, ultimately inflates into a 10x bill difference.
Is the Extra Spending Wasted? Claude Code's Hidden Value
At this point, it might seem like Codex wins hands down. But if that were truly the case, Claude Code wouldn't have so many loyal users.
The extra Tokens that Claude Code burns aren't entirely wasted. Because it reads more thoroughly, checks more carefully, and thinks more deeply, in some comparative tests, Claude Code has caught Race Conditions that Codex missed—these are hidden bugs that only surface occasionally and are extremely difficult to reproduce in normal testing, making them the most troublesome issues in production environments.
A race condition is one of the most classic and challenging problems in concurrent programming. When two or more threads (or processes) simultaneously access shared resources, and the final result depends on the order in which they execute, a race condition can occur. The danger lies in the fact that in development and testing environments, where load is lower and timing is relatively fixed, race conditions may never trigger; but in high-concurrency production scenarios, they appear randomly with extremely low probability, causing data corruption, deadlocks, or even security vulnerabilities. Historically, many major system failures—from banks processing duplicate charges to spacecraft software crashes—have been linked to race conditions. Precisely because these bugs are nearly impossible to catch through conventional unit testing, Claude Code's approach of "checking a few more files and verifying related logic multiple times" is actually more likely to catch them during the code review stage.
Beyond that, someone conducted a set of blind evaluation experiments: code written by both tools was shown to developers with the names hidden, and 67% of them felt that Claude Code's output was cleaner and more maintainable.
So as things stand, there's no absolute winner or loser—each has its strengths and weaknesses. Choosing between them is fundamentally a trade-off decision.
Practical Advice: How to Choose for Different Scenarios and Money-Saving Tips

Since Codex saves money by "reading sparingly and not taking detours," while Claude Code costs more because it "reads thoroughly, checks carefully, and confirms frequently," we can make flexible choices based on the nature of the task.
Scenarios Where Codex Is the Better Choice
- Writing copy, everyday development, rapid iteration
- Building prototypes, proof of concepts (PoC)
- Personal projects with tight budgets
- Scenarios where code quality just needs to be "good enough"
Scenarios Where Claude Code Is the Better Choice
- Complex system refactoring
- Production-grade code writing
- Projects with very high quality and fault-tolerance requirements
- Scenarios involving sensitive logic like concurrency and security
General Token-Saving Tips
- Clarify requirements before starting: Describe your requirements completely in one go to reduce back-and-forth confirmation rounds
- Control context size: Avoid feeding in overly large files at once; provide information in segments as needed
- Use task decomposition wisely: Break large tasks into smaller ones, each in an independent session, to prevent context from expanding indefinitely. This point is especially important—as mentioned earlier, the attention computation complexity of context is O(n²), which means splitting a 200,000-Token long session into four 50,000-Token short sessions can theoretically reduce total computation to 1/4 of the original. While actual savings depend on the provider's specific billing method, splitting sessions almost always significantly reduces costs
- Use a hybrid approach: Handle simple tasks quickly with Codex, and use Claude Code for meticulous work on critical modules. This "dual-engine" strategy is being adopted by an increasing number of development teams in practice—using Codex to build scaffolding and handle boilerplate code, then using Claude Code for deep review and optimization of core business logic, security modules, and concurrency handling. This controls total costs while ensuring code quality where it matters most
Conclusion: The Trade-off Between Efficiency and Quality
Returning to the original question: Is Claude Code more expensive because it's better than Codex?
The answer is: not exactly. One prioritizes efficiency, the other prioritizes quality. The essence of the 10x price gap isn't in Token unit pricing, but in two fundamentally different working philosophies—Codex is like a silent, efficient executor, while Claude Code is like a rigorous, meticulous reviewer. Whether efficiency or quality matters more depends on the specific task at hand and your budget constraints.
The smartest approach may not be choosing one over the other, but letting each play to its strengths.
Related articles

GPT-5.6 Pro Hands-On Review: In-Depth Evaluation of Game Development, 3D Modeling, and SVG Design Capabilities
Comprehensive hands-on review of GPT-5.6 Pro covering SVG vector design, 3D modeling, game generation, and image-to-web conversion. Detailed analysis of breakthroughs in spatial understanding, code reasoning, and One-Shot generation.

Claude Code Source Leak Revealed: The 5-Step AI Coding Agent Mechanism & Practical Pitfall Guide
Deep dive into Claude Code's leaked source revealing the 5-step AI coding Agent mechanism: progressive disclosure, precise indexing, surgical edits, auto-verification & graceful termination.
Deep Dive into the 198-Page Codex Chinese Manual: A Complete Guide from Beginner to Advanced
Deep breakdown of ByteDance's internal 198-page Codex Chinese manual covering installation, Commands, MCP workflows, Skills templates, multi-Agent collaboration, and background task scheduling.