GPT-5.6 Pro Hands-On Review: In-Depth Evaluation of Game Development, 3D Modeling, and SVG Design Capabilities

GPT-5.6 Pro shows major leaps in SVG design, 3D modeling, game generation, and image-to-code capabilities.
Leaked tests of GPT-5.6 Pro reveal significant advances in SVG design, 3D modeling via Three.js, game generation with One-Shot success, and near-perfect image-to-web page reproduction. The model demonstrates breakthrough spatial understanding and code reasoning, surpassing Claude in visual-spatial tasks while trading longer inference time for higher output quality.
Introduction: OpenAI's Powerful Comeback
Just shortly after Claude Sonnet 4 went live, OpenAI's upcoming GPT-5.6 Pro has already begun stirring up a new wave of excitement. According to predictions on Polymarket, the model is set for official release on June 25, but numerous testers have already gained early access and are sharing their test results extensively online. Polymarket is a blockchain-based decentralized prediction market platform where users can bet real money on the outcomes of future events. Because real money is at stake, its prediction prices are generally considered more reflective of participants' genuine expectations than ordinary polls or social media speculation. In the AI industry, Polymarket has become an important source for tracking model release timelines—the release dates of both GPT-4o and Claude 3.5 were accurately predicted on the platform.
Unlike previous releases, this round of testing doesn't focus on traditional tasks like writing articles, doing translations, or answering questions. Instead, it zeroes in on some of AI's most challenging domains—SVG design, game development, 3D modeling, image reproduction, and web page generation. Based on the leaked test results so far, GPT-5.6 Pro is likely OpenAI's most significant capability upgrade in the past two years.
GPT-5.6 Pro's SVG Design Capabilities: From "Crooked Wheels" to Professional-Grade Output
Many people might wonder—isn't SVG just a vector graphic? Why has it become an important benchmark for measuring AI capabilities?
The reason is that SVG design rigorously tests a model's comprehensive understanding of geometric structures, spatial layouts, layer relationships, and proportion control. SVG (Scalable Vector Graphics) is an XML-based vector graphics format that, unlike the PNG and JPEG pixel-based images we encounter daily, describes graphic paths, shapes, and colors through mathematical formulas. Every line segment and every arc requires precise coordinate values and Bézier curve parameters—any tiny numerical deviation results in visually obvious errors, such as a circle becoming an ellipse or two lines that should intersect showing a gap. This makes SVG generation an ideal test scenario for examining the intersection of AI's mathematical reasoning and visual understanding capabilities, far more revealing of a model's true capability boundaries than generating text or translating sentences.
Previously, when GPT generated SVGs, issues like disproportionate scaling, misaligned lines, and misplaced elements were common—it would even get the position of car wheels wrong.

However, in the BMW car SVG design test case, GPT-5.6 Pro's output approached the quality of professional design software—not only was the overall structure correct, but the detail proportions were noticeably more reasonable, even incorporating perspective effects. Testers also showcased various SVG works including rockets, tanks, and factory robots, each with clear recognizability.
What does this mean? In the future, a large volume of logo design, illustration creation, and UI asset work could potentially be completed directly through a single AI prompt, fundamentally changing the design industry's workflow.
Mechanical Watches and 3D Modeling: GPT-5.6 Pro's Breakthrough in Spatial Understanding
In the mechanical watch design test case, GPT-5.6 Pro demonstrated impressive spatial understanding capabilities. Testers asked the model to design a mechanical watch, requiring attention to dial structure, hand positions, and the entire mechanical hierarchy—areas where AI has historically been most prone to failure, as the model must understand the logical structure of real-world objects.

The result was that GPT-5.6 Pro's first output was nearly production-ready. It's worth mentioning that GLM 5.2, an open-source model tested concurrently, also demonstrated very strong capabilities, even producing a complete 3D mechanical watch without obvious structural errors—the progress of open-source models is equally impressive.
Another more challenging test involved using a single prompt to create a low-poly 3D model of a BMP turret using Three.js, with all code contained in a single HTML file. Three.js is currently the most popular WebGL JavaScript library, abstracting low-level OpenGL ES shader programming into high-level APIs that enable developers to create and render 3D scenes directly in the browser without installing any plugins or specialized software. Low-poly modeling is a technical style that expresses object contours using the minimum number of triangle faces, requiring the creator—whether human or AI—to precisely grasp the key structural features of an object and convey its core form with limited geometric faces. For AI to complete this task, it needs to simultaneously master Three.js's BufferGeometry vertex definitions, material systems, lighting models, and camera perspective projection across multiple technical dimensions, making it far more difficult than ordinary code generation tasks.
GPT-5.6 Pro directly generated a highly recognizable model with very accurate contours. Claude's performance on the same test was noticeably inferior.
The core difficulty of this test lies in the fact that AI must not only write code but also understand the spatial relationships of three-dimensional structures—precisely one of the weakest areas for large language models currently, and GPT-5.6 Pro's progress in this regard is remarkable.
Image-to-Web Page Reproduction: A "Crisis Moment" for Front-End Engineers
GPT-5.6 Pro also demonstrated a capability that testers called "the most terrifying"—by simply uploading a web page screenshot with an extremely simple prompt, it can reproduce the entire web page design almost one-to-one.
From layout to fonts, from spacing to colors, nearly everything is automatically replicated. This indicates the model is no longer merely "recognizing images" but is understanding design logic. It can parse the hierarchical relationships between visual elements, alignment rules, and typographic intent, then convert them into runnable front-end code. Specifically, the model needs to infer DOM structure nesting levels, CSS Flexbox or Grid layout methods, responsive breakpoint settings, and the margin and padding value relationships between elements—all from a single static image. This cross-modal conversion from visual to code requires the model to simultaneously possess computer vision perception capabilities and front-end engineering domain knowledge, representing a concentrated demonstration of multimodal AI capabilities.
This also means that the first area of front-end engineering work to be transformed by AI is likely UI reproduction—the repetitive work of writing HTML/CSS based on design mockups is being replaced by AI with extremely high efficiency.
AI Game Generation: From Demos to Complete Playable Experiences
If using AI to write game code a year ago would most likely result in an error-filled HTML page or a completely unplayable demo, GPT-5.6 Pro has completely changed this situation.
Testers showcased multiple complete game cases:
- Archery simulation game: Including power-charging mechanics, parabolic physics, multiple-distance targets, and level unlock systems
- Racing game: Complete 3D scenes and game logic
- Rocket launch simulation: Including launch systems, camera following, particle effects, procedural sound effects, and a complete system
- 3D Poké Ball: Opens to reveal a random Pokémon—two years ago, this would have been practically an independent small game project
Particularly noteworthy is GPT-5.6 Pro's progress in One-Shot capability—generating a successful result on the first attempt without repeated debugging. In the AI code generation field, One-Shot capability is one of the key metrics for measuring a model's practical utility. It means the model's output code can run directly without manual debugging and achieve the expected results, requiring the model to anticipate potential syntax errors, logic flaws, and runtime exceptions during generation, completing internal corrections before output. The improvement in One-Shot success rate reflects the maturity of the model's internal reasoning chain—it no longer needs to rely on multiple rounds of user feedback to gradually approach the correct answer, but can complete the entire closed loop from requirement understanding to code implementation in a single inference pass.
According to tester feedback, in just 30 minutes, the model generated a rocket launch game with a complete system. Previously, completing such a project would require at least several days of work from an independent developer.
Multiple testers noted that while Claude Sonnet 4 remains strong in complex code reasoning, GPT-5.6 Pro has begun to surpass it in game generation and visual-spatial understanding.
Summary of GPT-5.6 Pro's Core Upgrade Directions
Based on the leaked test results, GPT-5.6 Pro's core upgrades can be summarized in the following directions:
- Significantly enhanced code reasoning: Not only can it write correct code, but it understands the logical structure behind the code
- Spatial understanding breakthrough: From 2D SVG to 3D modeling, the model's grasp of geometry and spatial relationships has noticeably improved
- Image-to-code capability upgrade: Evolved from "describing what it sees" to "reproducing designs from images"
- Higher One-Shot success rate: The quality of first-attempt generation has significantly improved, reducing the need for iterative refinement
However, some testers pointed out that the model's thinking time has noticeably increased—very similar to Claude's development trajectory, essentially trading longer reasoning time for higher-quality output. This phenomenon corresponds to an important technical trend in the current AI field: inference-time compute scaling. Traditional AI capability improvements primarily relied on investing more data and compute during the training phase, while inference-time compute strategies improve output quality by allocating more computational resources during the inference phase after the model has already been trained. Specific implementation methods include Chain-of-Thought reasoning, internal verification and self-correction, multi-path search and optimal selection, among others. OpenAI's o1/o3 series and Anthropic's Claude extended thinking mode both employ this strategy. This essentially seeks a new Pareto optimal point between inference cost (longer wait times and higher API fees) and output accuracy, offering users the option to "spend more time for better results."
Final Thoughts: New Variables in the AI Competitive Landscape
In just two to three years, AI has evolved from "drawing six fingers" to producing results that are nearly indistinguishable from human work in gaming, code, design, and video. The emergence of GPT-5.6 Pro is likely to become yet another turning point in AI development.
Can OpenAI reclaim its lost technological lead with this upgrade? How long can Claude's Sonnet series maintain its advantage? Will open-source models like GLM catch up from behind? The answers to these questions will likely become clearer after the official release.
What's certain is that the capability boundaries of AI programming and AI design are expanding at a pace that exceeds expectations. For developers and designers, learning to collaborate with these tools rather than resist them may be the most pragmatic choice.
Key Takeaways
Related articles

Ponytail Plugin for Claude Code Tested: Dramatically Less Code, 50% Lower Costs
Real-world testing of Claude Code plugin Ponytail: YAGNI decision ladder dramatically reduces AI-generated code, cutting costs 47%-77% with weather dashboard comparison and benchmark analysis.
DeepSeek + Resonix: A Low-Cost AI Coding Solution — 150 Million Tokens for Just $1.10
Real-world test: DeepSeek API + Resonix coding tool consumed 150M tokens for just $1.10. Deep dive into DeepSeek pricing, Resonix's 95% cache hit rate, and honest comparison with GPT models.
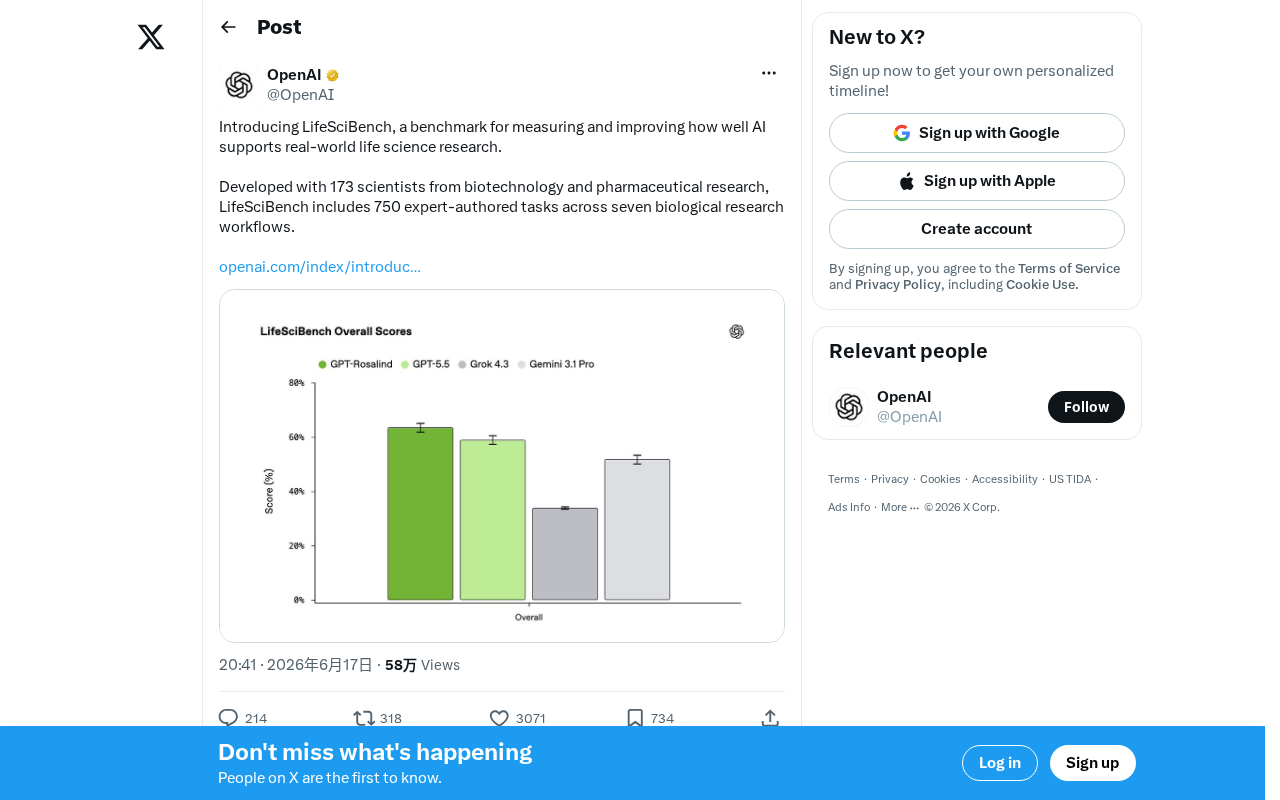
LifeSciBench: A Life Science AI Benchmark Built by 173 Scientists
LifeSciBench is a life science AI benchmark developed by 173 biotech and pharma scientists, featuring 750 expert tasks across seven research workflows.