DeepSeek + Resonix: A Low-Cost AI Coding Solution — 150 Million Tokens for Just $1.10
DeepSeek + Resonix delivers 150M tokens of AI coding for just $1.10 via 95% cache hit optimization.
A developer shares how the DeepSeek + Resonix combination achieved 150 million tokens of AI-assisted coding for just 8 RMB (~$1.10). Resonix's prompt prefix reuse strategy achieves 95% cache hit rates on DeepSeek's API, slashing costs to near zero. While DeepSeek falls short of GPT models in global code refactoring, its extreme cost-effectiveness makes it ideal for budget-conscious developers handling everyday coding tasks.
The Cost Dilemma of AI Coding: From Premium Models to Budget-Friendly Solutions
For developers who use AI-assisted programming daily, model costs are an unavoidable topic. From OpenAI's Codex to Claude, powerful coding capabilities often come with hefty API fees. One programmer shared his real-world experience at work — from initially using ChatGPT/Codex models and being forced to abandon them due to high costs, to ultimately discovering the incredibly cost-effective combination of DeepSeek + Resonix.
To understand the context of this story, we need to first look at the current pricing landscape for AI coding APIs. Take OpenAI as an example: GPT-4o's API is priced at $2.50/million tokens for input and $10/million tokens for output; Claude 3.5 Sonnet is priced at $3/million tokens for input and $15/million tokens for output; and premium models specifically designed for coding scenarios like Claude 3.5 Opus are even more expensive. For an active development team, consuming tens of millions of tokens per month is the norm, meaning API costs alone could reach hundreds or even thousands of dollars. While GitHub Copilot offers a $19/month subscription plan, the underlying model capabilities and customization flexibility are correspondingly limited. It's against this industry pricing backdrop that DeepSeek's emergence is particularly noteworthy.
The most jaw-dropping figure: 150 million tokens consumed at a total cost of just 8 RMB (approximately $1.10 USD). The secret behind this number is worth understanding for every developer concerned about AI coding costs.
DeepSeek API Pricing Breakdown: How Can It Be This Cheap?
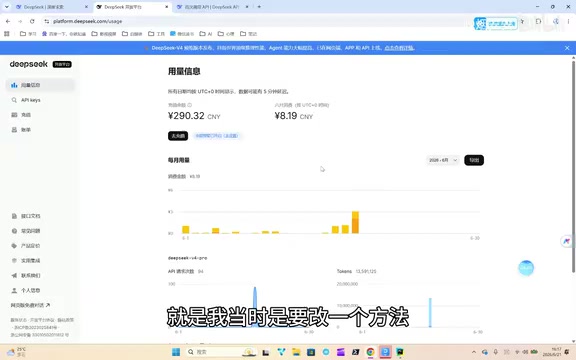
Actual Usage Bill
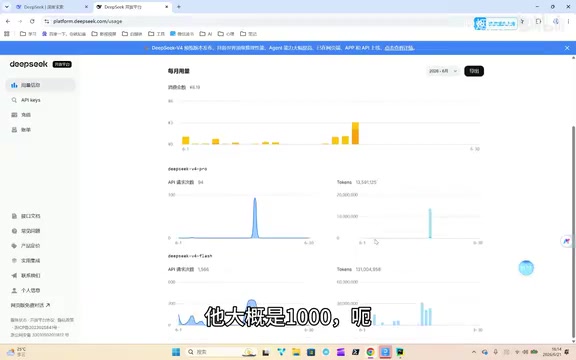
According to the developer's June usage data from the DeepSeek platform, he was using two models simultaneously:
- Flash model: Consumed approximately 130 million tokens
- Pro model: Consumed approximately 10 million tokens
- Total: Approximately 150 million tokens
- Total cost: Just 8 RMB (~$1.10 USD)
If this same volume were run on other mainstream models, the cost could be tens or even hundreds of times higher. Roughly estimating the same 150 million tokens, GPT-4o would cost approximately $375–$1,500 (depending on the input/output ratio), while Claude 3.5 Sonnet would run approximately $450–$2,250. DeepSeek's ability to achieve such low prices is closely tied to its pricing strategy.
DeepSeek API Specific Pricing
DeepSeek's API offers two compatible formats — OpenAI format and Anthropic format — mirroring the interface specifications of ChatGPT and Claude respectively, making it easy for developers to migrate seamlessly. This multi-format compatibility means developers barely need to modify existing code; they only need to swap the API endpoint and key to switch applications originally calling OpenAI or Anthropic over to DeepSeek, dramatically reducing migration costs.
Specific pricing:
- Flash model: Just 0.02 RMB per million tokens on cache hits (2 cents RMB), 1 RMB/million tokens on cache misses
- Pro model: Approximately 0.025 RMB/million tokens on cache hits; 3 RMB for input and 6 RMB for output per million tokens on cache misses
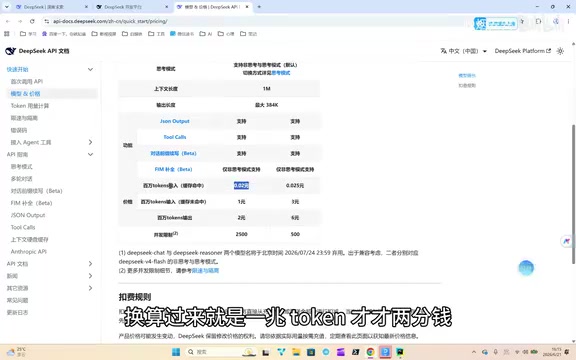
The key concept here is "cache hit" — when your request content has significant overlap with previous requests, the system reads directly from cache, dropping the cost to a nearly negligible level.
From a technical perspective, the "cache" here refers to the KV Cache (Key-Value Cache) mechanism in large language model inference. When a Transformer model processes input text, the attention mechanism at each layer computes a set of Key and Value vectors for every token. These computed results are reused repeatedly during subsequent generation. If two API requests share the same prefix (such as the same system prompt and project context), the KV Cache corresponding to that prefix can be directly reused without recalculation. For GPU clusters, this means massive compute savings — the prefix-matched portion consumes virtually no additional computational resources and only needs to be read from VRAM or high-speed cache. DeepSeek has implemented cross-request KV Cache sharing at the infrastructure level and passes these compute savings back to users through extremely low cache-hit pricing. This also explains why cache-hit prices can be as low as 1/50th of cache-miss prices — because the actual computational resources consumed are indeed only a tiny fraction of the original.
And this is precisely where the Resonix tool plays a critical role.
What Is Resonix? An AI Coding Tool with Up to 95% Cache Hit Rate
Resonix Overview
Resonix is an AI coding tool that uses DeepSeek as its native backend and can be used directly in the terminal. It's positioned similarly to Cursor, Aider, and other AI coding assistants, but is deeply optimized specifically for DeepSeek models.
In the current AI coding tool ecosystem, mainstream products each have their own focus: Cursor is a VS Code-based AI-enhanced IDE starting at $20/month, supporting multiple models but primarily relying on Claude and GPT series; GitHub Copilot is deeply integrated into editors and excels at code completion at $19/month; Aider is an open-source terminal AI coding tool supporting multiple model backends, but users bear the API costs themselves; Windsurf (formerly Codeium) focuses on a freemium model. The common characteristic of these tools is that they either have non-trivial subscription fees, or API costs are borne by users without cost optimization for specific models. What makes Resonix unique is that it's not a general-purpose multi-model client — it's specifically custom-built around DeepSeek's architectural characteristics, with "saving money" as one of its core design goals.
Installation and usage is straightforward:
- Ensure Node.js and Git are installed
- Obtain a DeepSeek API Key
- Navigate to your project directory and run the
npxcommand to start - Enter your API Key on first launch and you're ready to go
Resonix Cache Hit Rate: The Core Secret to Saving Money
The developer particularly emphasized Resonix's outstanding cache hit rate performance:
- Daily usage cache hit rate: Consistently above 90%
- Average level: Approximately 95%
- Peak record: Reaching 98%
This means that in actual use, the vast majority of tokens are billed at the ultra-low cache-hit price. This is the core reason why 150 million tokens cost only 8 RMB — if 95% of tokens are priced at 0.02 RMB per million tokens, the cost is naturally extremely low.
The reason Resonix achieves such high cache hit rates lies in its carefully designed prompt prefix reuse strategy and context window management mechanism. In AI coding scenarios, each request typically contains three parts: the system prompt, project context (relevant code files, directory structure, etc.), and the user's specific instruction. Resonix's optimization approach is to keep the first two parts as consistent and stably ordered as possible across multiple requests. Specifically, it fixes the system prompt at the very beginning, then organizes project file content according to deterministic sorting rules, ensuring that even when users switch between editing different files, the prompt prefix sent to the API overlaps as much as possible with the previous request. Additionally, Resonix intelligently manages incremental updates to the context window — when a user modifies a file, it doesn't reorganize the entire context but instead appends changes at the end of the prompt as much as possible, thereby preserving the cache validity of the prefix. In contrast, other general-purpose coding tools (such as Aider, OpenCode, etc.) tend to dynamically reorganize context according to their own logic when connecting to DeepSeek, causing significant prefix changes with each request and naturally resulting in much lower cache hit rates.
Compared to using other coding tools (such as OpenCode, Claude's official tools, etc.) with DeepSeek models, cache hit rates typically don't reach Resonix's level. This demonstrates that Resonix has made specialized optimizations in request construction and context management to maximize utilization of DeepSeek's caching mechanism.
The Real Shortcomings of DeepSeek's Coding Ability: Incomplete Code Modifications
The Gap with GPT Models
The developer didn't just sing praises — he candidly pointed out DeepSeek's gaps compared to GPT models in coding capability. He gave a typical example:
When needing to modify a method and add new parameters to it, DeepSeek could correctly refactor the method itself, but among three places in the project that called this method, DeepSeek only modified one of them — the other two call sites were missed.
When using GPT models, it would not only modify the method itself but also proactively check all places in the project that call that method and complete the modifications across the board — achieving a "one-shot complete fix."
This "incomplete modification" problem is a frequent shortcoming of DeepSeek in coding scenarios, reflecting the gap between domestic models and top-tier models in global code understanding and cross-reference modification capabilities.
From a technical perspective, this shortcoming involves multiple factors. First is the ability to construct global code dependency graphs: top-tier models (such as GPT-4o, Claude 3.5 Sonnet) can implicitly build function call relationship graphs within the context window when handling code modification tasks, identifying all affected call sites. This capability depends not only on the model's reasoning ability but also on the large volume of real code refactoring examples in the training data — OpenAI and Anthropic have invested heavily in training data curation, particularly for high-value programming scenarios like "cross-file correlated modifications." Second is the granularity of instruction following: when a user asks to modify a method signature, the implicit expectation is that "all callers should be updated accordingly," which requires strong intent inference capabilities. While DeepSeek's foundational code generation ability is already quite impressive (performing well on multiple programming benchmarks), in complex refactoring scenarios requiring a global perspective, it still tends toward "local optima" — it tends to perfectly solve the currently focused code snippet while paying insufficient attention to other related locations in the context. It's worth noting that this isn't unique to DeepSeek; most open-source models exhibit varying degrees of omission in similar scenarios, and this is one of the most significant capability gaps between current open-source and closed-source top-tier models.
The Cost-Performance Tradeoff: Good Enough Is Good Enough
However, the developer offered a pragmatic conclusion:
"The price is right there, and I think it's still a great deal. Even though it has some issues, I'm a programmer myself — I can go in and fix things manually, so it's not a big deal."
This actually represents the real mindset of many developers — an AI coding assistant doesn't need to be 100% perfect. As long as it covers the majority of the workload, significantly boosts efficiency, and keeps costs under control, it's already practical enough. For developers with a solid programming foundation, spending a few minutes manually completing modifications that the AI missed is far more acceptable than paying hundreds of dollars per month in API fees.
From an economics perspective, this is actually a classic diminishing marginal returns problem. Going from DeepSeek to GPT-4o, the coding capability improvement might be from 85 points to 95 points, but the cost increase is tens or even hundreds of times greater. For most everyday coding tasks — writing CRUD endpoints, debugging, generating unit tests, writing documentation — 85 points of capability is more than sufficient. Only in scenarios involving large-scale refactoring or complex architectural design does that extra 10 points truly demonstrate its value. Therefore, flexibly choosing models based on project needs, or even mixing different models within the same project (DeepSeek for daily tasks, GPT for critical refactoring), may be the most rational strategy currently available.
Summary: Which Developers Is DeepSeek + Resonix Best Suited For?
For developers on a budget who still want to experience AI-assisted programming, the DeepSeek + Resonix combination is definitely worth trying:
- Extremely low cost: Thanks to DeepSeek's inherently low pricing and Resonix's high cache hit rate, daily coding API costs are virtually negligible
- Easy to get started: Node.js + Git + a single
npxcommand to launch - Capable enough: While it falls short of GPT models in global code understanding, it's more than sufficient for everyday coding tasks
Of course, if your project demands extremely high completeness in code modifications or involves extensive complex refactoring work, you may still need to consider more powerful models. But from a cost-performance perspective, this combination is currently the "people's choice" in the AI coding space.
It's worth noting that the cost landscape of AI coding tools is evolving rapidly. As domestic models like DeepSeek continue to iterate, open-source model capabilities keep improving, and vendors engage in an arms race on inference efficiency optimization, the barrier to AI-assisted programming will only continue to drop. For individual developers and small-to-medium teams, now is the best time to embrace AI coding at minimal cost.
Key Takeaways
Related articles

AI Programming: Can You Really Build Apps Without Coding? An In-Depth Analysis of Real Capabilities and Monetization Paths
Can AI programming tools really let non-coders build and monetize apps? This article analyzes AI coding's true capabilities, viable monetization paths, and common misconceptions.
OpenAI's New Research: Keeping AI Safe During High-Stakes Tasks
OpenAI's new research on "broadly and persistently beneficial" AI explores how to keep models safe in high-stakes scenarios beyond their training distribution.

Ponytail Plugin for Claude Code Tested: Dramatically Less Code, 50% Lower Costs
Real-world testing of Claude Code plugin Ponytail: YAGNI decision ladder dramatically reduces AI-generated code, cutting costs 47%-77% with weather dashboard comparison and benchmark analysis.