LifeSciBench: A Life Science AI Benchmark Built by 173 Scientists
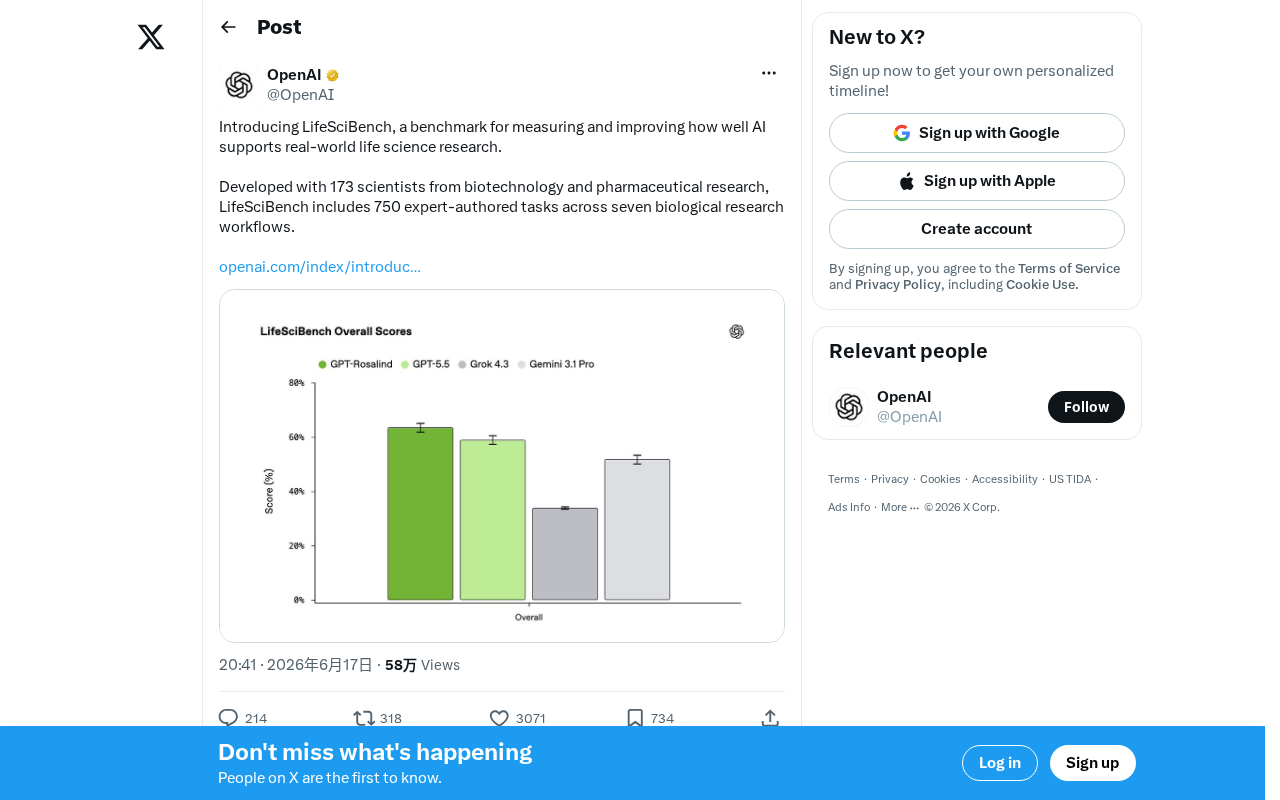
173 scientists built LifeSciBench, a 750-task benchmark to evaluate AI in life science research.
LifeSciBench is a new AI benchmark for life sciences, co-developed by 173 biotech and pharmaceutical scientists. It features 750 expert-authored tasks spanning seven biological research workflows, addressing the limitations of general-purpose benchmarks like MMLU and HumanEval. The benchmark aims to drive targeted AI model optimization, accelerate pharmaceutical AI adoption, and bridge the gap between scientists and AI developers.
A Professional AI Evaluation Standard Arrives for Life Sciences
AI adoption in life sciences is accelerating, but a critical question has remained unanswered: how do we measure AI's actual performance in real-world research scenarios? General-purpose AI benchmarks often fail to capture the complexity and specialization inherent in life science research.
Recently, a new benchmark called LifeSciBench was officially released, designed to systematically measure and improve AI's ability to support real life science research. Developed collaboratively by 173 scientists from the biotechnology and pharmaceutical research sectors, it encompasses 750 expert-authored tasks spanning seven major biological research workflows.
Why Do We Need a Dedicated Life Science AI Benchmark?
The Limitations of General-Purpose Benchmarks
Current mainstream AI benchmarks (such as MMLU, HumanEval, etc.) primarily focus on general knowledge Q&A or programming ability, leaving significant evaluation blind spots for highly specialized fields like life sciences. MMLU (Massive Multitask Language Understanding), proposed in 2021 by UC Berkeley and other institutions, covers approximately 15,000 multiple-choice questions across 57 subjects and mainly tests a model's breadth of knowledge. HumanEval, released by OpenAI, contains 164 hand-written programming problems for evaluating code generation capabilities. While these benchmarks serve as important standards in their respective domains, their highly standardized evaluation dimensions cannot simulate the complex cognitive processes common in life science research — such as open-ended problem solving, multi-step reasoning chains, and cross-modal data integration.
Life science research involves complex experimental design, data interpretation, literature analysis, and hypothesis validation — capabilities that go far beyond simple multiple-choice questions or text generation. Modern life science research typically follows a highly systematic workflow: from literature review and scientific hypothesis formation, to experimental design and execution, to multi-omics data integration (genomics, proteomics, metabolomics, etc.), and finally to result validation and manuscript writing. Each stage involves extensive domain-specific knowledge — for example, experimental design requires understanding special biological sample handling requirements, statistical power analysis, and ethical review standards. This end-to-end complexity means that general-purpose AI tools often fall short in real research scenarios.
Real Needs from Frontline Scientists
The core value of LifeSciBench lies in the authority of its source — all 173 scientists involved in its development come from the frontlines of biotechnology and pharmaceutical research. This means every task in the benchmark is rooted in real research scenarios rather than academic hypotheticals. This "bottom-up" design approach ensures that evaluation results are highly aligned with actual research needs.
Core Design and Task Composition of LifeSciBench
750 Expert-Authored Tasks
LifeSciBench contains 750 evaluation tasks carefully crafted by domain experts — a considerable scale for life science AI evaluation. Each task has undergone rigorous peer review to ensure scientific accuracy and evaluation validity.
Covering Seven Major Biological Research Workflows
The benchmark covers seven key biological research workflows. While the official documentation has not yet disclosed all workflow details, based on the general scope of life science research, these workflows likely include:
- Literature Search and Review: Evaluating AI's ability to integrate and analyze scientific literature
- Experimental Design: Testing AI's proficiency in assisting with experimental protocol development
- Data Analysis and Interpretation: Measuring AI's accuracy in processing biological data
- Target Discovery and Validation: Assessing AI's supportive capabilities in early-stage drug development
- Sequence and Structure Analysis: Testing AI's depth of understanding of biomolecular information
Among these, target discovery is the starting point of new drug development — it refers to identifying biological molecules (typically proteins) closely associated with disease onset and progression. Traditional target discovery relies on extensive wet-lab validation, is time-consuming and costly, and typically takes 3–5 years from discovery to validation. In recent years, AI technologies have significantly accelerated this process by integrating multi-source information such as genome-wide association studies (GWAS), protein interaction networks, and single-cell transcriptomic data. DeepMind's AlphaFold breakthrough in protein structure prediction has provided an entirely new tool for structure-based target validation. LifeSciBench's evaluation of this stage will directly reflect AI's practical effectiveness at the most critical initial phase of drug development.
This multidimensional evaluation framework enables LifeSciBench to comprehensively reflect AI's overall performance in life science research, rather than testing just a single capability.
LifeSciBench's Far-Reaching Industry Impact
Driving Targeted Optimization of AI Models
With a standardized evaluation system in place, AI developers can optimize model performance in life sciences with much greater precision. In the past, the lack of specialized benchmarks meant model development could only rely on general metrics, leading to underwhelming performance in actual research applications. LifeSciBench provides a clear directional guide for model iteration.
Accelerating AI Adoption in Pharmaceuticals
The pharmaceutical industry is one of the most commercially valuable areas for AI application. According to estimates from Boston Consulting Group, McKinsey, and other institutions, AI has the potential to shorten drug development cycles by 30%–50% and reduce R&D costs by billions of dollars. Currently, there are over 100 AI pharmaceutical companies worldwide, including leading players such as Recursion Pharmaceuticals, Insilico Medicine, and Exscientia. Notably, Insilico Medicine's AI-discovered drug ISM001-055 has entered Phase II clinical trials, marking a milestone in the AI pharma space. However, the industry also faces skepticism about "AI hype" — many companies' AI pipelines have yet to produce an approved drug, making objective evaluation of AI tools' real effectiveness a major industry pain point.
A benchmark widely recognized by the industry can help pharmaceutical companies evaluate and select AI tools more scientifically, reducing the risk of technology selection. At the same time, it provides AI companies with a stage to demonstrate their capabilities — strong performance on LifeSciBench will serve as powerful market validation.
Building a Bridge Between Scientists and AI Developers
The deep involvement of 173 scientists is itself a successful cross-disciplinary collaboration. This model — having end users deeply participate in defining AI evaluation standards — is worth emulating in other specialized fields. It ensures that technological development remains user-need-driven and prevents technology from becoming disconnected from practical applications.
Outlook and Reflections
The release of LifeSciBench signals that AI applications in life sciences are transitioning from an exploratory phase to a standardization phase. When a field begins establishing systematic evaluation standards, it often means that AI applications in that field are about to enter a period of rapid maturation.
However, the benchmark itself faces challenges. Life science research evolves rapidly — can 750 tasks continue to reflect cutting-edge needs? How should evaluation standards be dynamically updated as technology advances? These questions will need to be addressed through subsequent iterations. It's worth noting that "data contamination" in benchmarks is a long-standing challenge in AI evaluation — when training data includes benchmark questions, model scores become artificially inflated and fail to reflect true capabilities. Additionally, the life sciences field publishes over 1.5 million papers annually, with frontier technologies like CRISPR gene editing, spatial transcriptomics, and AI protein design constantly emerging, meaning static evaluation sets quickly become outdated. Industry strategies to address this include regular question bank updates, dynamic generation mechanisms, and establishing "living benchmark" systems that allow evaluation standards to evolve in sync with scientific frontiers.
Regardless, LifeSciBench has taken an important step — for the first time, it gives us a reliable yardstick to measure the extent to which AI can truly advance life science research.
Key Takeaways
Related articles

Ponytail Plugin for Claude Code Tested: Dramatically Less Code, 50% Lower Costs
Real-world testing of Claude Code plugin Ponytail: YAGNI decision ladder dramatically reduces AI-generated code, cutting costs 47%-77% with weather dashboard comparison and benchmark analysis.
DeepSeek + Resonix: A Low-Cost AI Coding Solution — 150 Million Tokens for Just $1.10
Real-world test: DeepSeek API + Resonix coding tool consumed 150M tokens for just $1.10. Deep dive into DeepSeek pricing, Resonix's 95% cache hit rate, and honest comparison with GPT models.

OpenAI o3 Diagnoses Rare Childhood Diseases: A Deep Dive into the NEJM AI Study
OpenAI and Boston Children's Hospital published research in NEJM AI showing how the o3 Deep Research model helps clinicians diagnose previously unresolved rare childhood diseases.