Compile First: Using AI to Revive the Dormant Files on Your Hard Drive
LLM Wiki compiles local files into an AI knowledge base using a compile-first paradigm.
LLM Wiki is an open-source project inspired by Andrej Karpathy's compile-first paradigm. Unlike traditional RAG systems that retrieve documents at query time, it proactively compiles local files into indexed, interlinked Markdown knowledge bases. With principles of transparency, local-first data, file-first storage, and AI model flexibility, it transforms forgotten hard drive files into a searchable, relationship-mapped personal knowledge brain.
How Many Forgotten Assets Are Hiding on Your Hard Drive?
Expense receipts, project summaries, reading notes, random journal entries… These files sit quietly on your hard drive collecting dust. You know you'll never look at them again, yet you can't bring yourself to delete them. It's only when you switch computers or run out of storage that you even remember they exist.
But what if a "digital twin" could silently read through hundreds of these documents, organize them for you, and deliver precise answers with just a single question? This is no longer a fantasy. A Bilibili creator named "Lizhi" shared his open-source project LLM Wiki, built on cutting-edge AI concepts, turning this vision into reality.
The Theoretical Foundation of LLM Wiki: The Compile-First Paradigm
The inspiration behind this project carries serious weight. Andrej Karpathy — former OpenAI co-founder and Tesla AI Director — recently published a thought piece that sparked widespread discussion in the AI community, proposing a groundbreaking new paradigm: LLM Wiki.
Karpathy is one of the most influential researchers and engineers in deep learning. He completed his PhD at Stanford University under Professor Fei-Fei Li and went on to lead the architecture design of core AI systems at both OpenAI and Tesla. His deep learning tutorial series on YouTube has accumulated tens of millions of views. Every technical insight he shares triggers extensive discussion and practical follow-up across the AI community, and LLM Wiki is his latest contribution.
The core idea can be summed up in two words: Compile First.
Traditional RAG (Retrieval-Augmented Generation) knowledge bases work on a "search when queried" model: user asks a question → retrieve relevant documents → feed them to a large language model to generate an answer. RAG was first proposed by Meta AI's research team in 2020 to address the "hallucination" problem and knowledge freshness issues in large language models. It has since become the dominant architecture for enterprise AI applications, widely used in intelligent customer service, internal knowledge Q&A, and similar scenarios. However, RAG has notable shortcomings: retrieval quality is highly dependent on the semantic matching precision of vector embeddings, there's no cross-document relationship analysis, and each query consumes a large portion of the context window to load raw document chunks.
LLM Wiki takes a fundamentally different approach — it treats the large language model as a full-time digital librarian that proactively starts working the moment new material arrives, rather than waiting for you to ask a question.
Specifically, the AI immediately does three things:
- Updates the index: Creates a quickly searchable directory structure for new content
- Creates overview pages: Extracts core summaries of documents
- Automatically establishes relationships between documents: Discovers hidden connections across different files
Behind this design lies a pragmatic technical consideration: a large model's context window is ultimately finite. The context window refers to the maximum number of tokens a large language model can process in a single inference pass. Early GPT-3.5 had a context window of only 4K tokens (roughly 3,000 English words). Even the most advanced models of 2024 — Claude 3.5 with 200K and GPT-4 Turbo with 128K — still fall short when facing enterprise knowledge bases containing tens of thousands of documents. More critically, research has shown that large models suffer from a "Lost in the Middle" phenomenon — when the context is too long, the model's attention to information in the middle positions drops significantly, leading to inconsistent answer quality.
Therefore, compiling in advance means that when the model answers a question, it only needs to read the index and overviews first, pinpointing the exact source material you need through a much shorter context. This transforms "finding a needle in a haystack" into "following a map to the destination," dramatically improving both retrieval efficiency and answer quality.
Four Design Principles: Why It's Trustworthy
When developing LLM Wiki, the author was dealing with years of accumulated core personal data, so he rigorously adhered to four architectural principles:
1. Transparency
Everything the AI remembers and organizes is presented as plain-text Markdown files — no black boxes. You can open any file at any time to see the AI's "thought process" and organizational results. This stands in stark contrast to traditional RAG systems, which typically rely on vector databases (such as Pinecone, Weaviate, Chroma, etc.) to store semantic embedding vectors of documents. These systems convert text into high-dimensional numerical vectors and retrieve them via cosine similarity. While this enables semantic-level fuzzy matching, the data in vector databases is completely unreadable to humans, creating an unauditable "black box." LLM Wiki replaces vector databases with readable Markdown files, making every processing step clearly visible.
2. Local-First
100% of data stays local — nothing is uploaded to any cloud server. For materials involving personal privacy or company secrets, this is crucial. In an era of increasingly strict data security regulations (such as the EU's GDPR and China's Personal Information Protection Law), local processing isn't just a privacy preference — it's a compliance requirement.
3. File-First
All data is stored purely as Markdown files. Created by John Gruber in 2004, Markdown is a lightweight markup language designed with the philosophy that "even without rendering, the plain text should be highly readable." By contrast, many popular note-taking and document tools have caused data migration headaches when companies went bankrupt or discontinued products — Evernote's .enex format, Notion's proprietary database structure, and Google Notebook's complete shutdown are all cautionary tales. Markdown files are essentially .txt plain text files with a few formatting symbols. Even 30 or 40 years from now, these files can still be read by any text editor on any operating system, with zero risk of format obsolescence or data loss from service shutdowns. This is why an increasing number of knowledge management tools (such as Obsidian and Logseq) have chosen Markdown as their underlying storage format.
4. AI Freedom
No lock-in to any specific AI model — you can freely connect Claude, DeepSeek, Qwen, and other large models, switching at any time to avoid vendor lock-in. This design is especially important given the rapidly shifting AI landscape — model capabilities iterate at breakneck speed, and today's strongest model might be surpassed within six months. Maintaining interface flexibility means your knowledge base can always run on the most advanced AI engine available.
These four principles reflect a mature engineering mindset: data outlives any single piece of software or service.
Real-World Results: What Was I Doing Seven Years Ago?

The author imported over a decade's worth of accumulated "vintage files" into the system in batches. The workflow is remarkably simple: set the corresponding directory path in the terminal, launch the program, and files automatically begin compiling to build your personal AI knowledge base.
The most stunning moment came when opening the relationship graph — LLM Wiki links all related document content and relationships together, displaying a massive knowledge network. This isn't a simple folder tree structure, but an organic, cross-referenced information web.
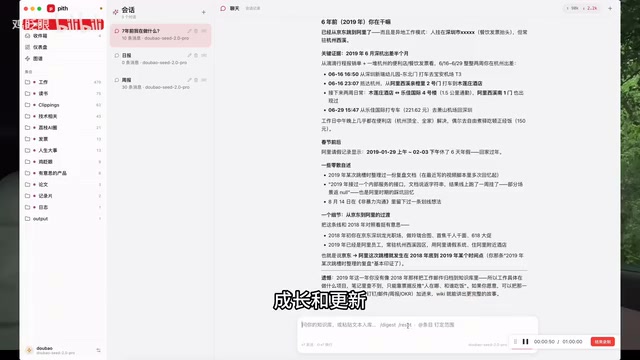
Behind this relationship graph is essentially an automated personal knowledge graph construction. The concept of a Knowledge Graph was first introduced by Google in 2012 to enhance search engines' understanding of entities and their relationships. It has since been widely applied in financial risk management, medical diagnosis, academic research, and other fields. However, traditional knowledge graph construction is extremely expensive, typically requiring domain experts to manually define entity types and relationship schemas. LLM Wiki leverages the semantic understanding capabilities of large language models to automate knowledge graph construction — during the compilation phase, the AI automatically identifies key entities in documents (people, places, events, concepts) and infers the relationships between them, weaving originally isolated file fragments into an organic information network.
Even more impressive was an impromptu test. The author casually asked: "What was I doing exactly seven years ago?" — a question he himself had absolutely no memory of. But the AI answered immediately.
How did it find the answer? The AI discovered ride-hailing receipts and dining expense invoices from that period, piecing together the author's movements and activities from these fragmented bits of information. Even the author himself was caught off guard by the result.
This reveals a deeper value of the compile-first paradigm: traditional knowledge bases merely ingest data mechanically, while LLM Wiki examines your information, intellectual growth, and trajectory of change. It's not just a search engine — it's more like a digital memory that understands the arc of your life.
Compile-First vs. Traditional RAG: Where Do the Paradigms Differ?
To better understand the value of this project, let's compare the core differences between the two paradigms:
| Dimension | Traditional RAG Knowledge Base | LLM Wiki (Compile-First) |
|---|---|---|
| Processing Timing | Retrieves at query time | Compiles at import time |
| Document Relationships | Stored independently, lacking connections | Automatically builds cross-references |
| Context Consumption | Needs to load large amounts of raw text | Reads index and overviews first, pinpoints precisely |
| Data Visibility | Typically stored in vector databases | All readable Markdown files |
| Knowledge Discovery | Passive response | Proactively discovers hidden connections |
The essence of compile-first is front-loading the most time-consuming step: "understanding." Like an excellent librarian who doesn't wait for readers to arrive before flipping through books, but has already organized every book's content, connections, and index in perfect order.
It's worth noting that these two paradigms aren't entirely opposed. In practice, compile-first can complement RAG — the indexes and summaries generated during compilation can serve as high-quality data sources for RAG retrieval, while RAG's real-time retrieval capabilities can handle new query scenarios not yet covered by compilation. Future knowledge management systems will likely merge the strengths of both paradigms into a more intelligent hybrid architecture.
Everyone Deserves Their Own AI Knowledge Brain
This project touches on a far-reaching question: What is the ultimate form of personal knowledge management?
In the past, we used folder hierarchies, note-taking apps, and tagging systems to organize information. But these methods share a common bottleneck — they all depend on active human maintenance. The moment you slack off, your knowledge base degrades into an information graveyard. This problem is known in the knowledge management field as the "entropy increase dilemma": information volume grows continuously over time, but human organizing capacity is finite, so the system's disorder inevitably trends upward.
The compile-first paradigm that LLM Wiki represents makes "zero-maintenance knowledge management" possible for the first time. You just need to drop files in, and the AI handles all the organizing, connecting, and indexing for you. This aligns with the "Second Brain" philosophy — a concept proposed by productivity expert Tiago Forte that advocates freeing the human brain from the burden of memorization. LLM Wiki advances this idea into a new phase of AI automation.
In the future, everyone may have their own dedicated AI brain — one that carries your memories, thinks from your perspective, and lets every past thought generate knowledge compound interest in the future. And the starting point for all of this might just be reviving those long-dormant files on your hard drive.
The project is open source. Interested readers can search for LLM Wiki on GitHub to try it out.
Related articles
AI Summoning Power: Insights and Practices from Zero-Code Game Development with AI
A creator with no coding experience built a complete game using only AI prompts. Explore AI summoning power, zero-code development, and what it means for PMs, developers, and everyone.

GLM-5.2 Deep Dive: Million-Token Context, MIT Open Source & Full-Stack Domestic Chip Training
Deep dive into Zhipu's GLM-5.2: truly usable 1M-token context, MIT open-source strategy, full-stack Huawei Ascend training, and how it compares to Claude Opus. Includes benchmarks, use cases & pricing.
Complete Guide to Connecting UE 5.8 with MCP Server: Codex Plugin Configuration Explained
Complete guide to connecting Unreal Engine 5.8 with MCP Server, covering UE 5.8 installation tips, VS Code Codex plugin setup, API key configuration, and MCP Server launch.