Cursor Composer 2.5 In-Depth Review: One-Tenth the Cost of Opus — Is It Worth Using?
Composer 2.5 delivers near-Opus coding performance at one-tenth the cost, though frontend design aesthetics lag behind.
Cursor's Composer 2.5 ranks third on AI coding benchmarks behind Opus 4.7 and GPT 5.5, yet costs just 7 cents per task versus Opus's $4-5. Real-world tests show strong performance in code generation, debugging, and 3D scenes, but it falls short in frontend design aesthetics. Built on the open-source Kimi K2.5 base with deep fine-tuning, it represents the democratization of top-tier AI coding at a fraction of the cost.
The Cursor team recently released Composer 2.5, a coding model that claims performance close to Opus 4.7 at just one-tenth the cost. This model ranks third on Artificial Analysis's AI coding agent leaderboard, behind only Opus 4.7 and GPT 5.5. Artificial Analysis is an independent AI model evaluation organization that focuses on standardized comparisons of large language model performance, speed, and cost. Their AI coding agent ranking comprehensively assesses model performance across multiple programming subtasks including code generation, debugging, and refactoring, making it one of the industry's most authoritative references. Opus 4.7, mentioned in this article, is Anthropic's flagship coding model in the Claude series, while GPT 5.5 is OpenAI's latest-generation large language model — both represent the current ceiling of AI programming capability. Can it really rival these top-tier models? This article puts it through multiple real-world scenarios to find out.
Composer 2.5's Core Advantage: Just 7 Cents Per Task
Composer 2.5's most striking feature is its incredible cost-effectiveness. The standard version averages just 7 cents per task, while fast mode costs only 44 cents. By comparison, Opus models cost $4 to $5 per task, and GPT 5.5's comparable versions are similarly expensive — the price gap can be tens of times larger.
In terms of API pricing, standard Composer 2.5 costs just 50 cents per million input tokens and $2.50 per million output tokens; the fast version is slightly more expensive ($3/million input tokens, $15/million output tokens) but faster and equally intelligent. To explain the concept of tokens: a token is the basic unit that large language models use to process text, roughly equivalent to three-quarters of an English word or one Chinese character. API pricing is typically calculated per million tokens, split into input tokens (the prompt content users send to the model) and output tokens (the model's generated response), with output tokens usually being more expensive due to higher computational demands during generation. At the standard rate of 50 cents per million input tokens, processing a 100,000-character Chinese technical document costs just a few cents — an extremely competitive price point in today's market.
Even more noteworthy: with a Cursor Pro subscription ($20/month), users get extremely generous usage allowances. The tester consumed only 1% of their quota after recording the entire review video — a stark contrast to the experience with Claude where "a single conversation can exhaust your quota."
Benchmark Performance: Crushing the Previous Composer 2 Across Multiple Dimensions
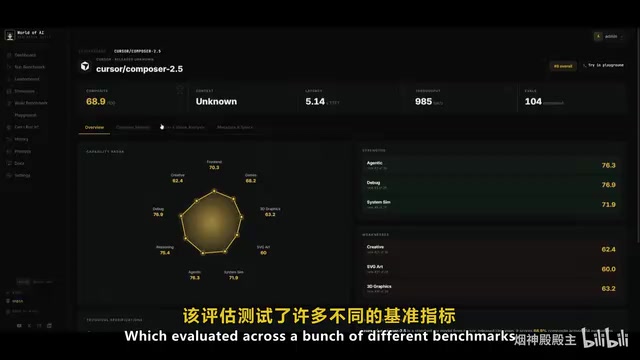
Composer 2.5 delivers impressive results across multiple authoritative benchmarks, including Terminal Bench 2.0, SWE-Bench, multi-dimensional tests, and Cursor Bench. Some metrics even surpass Opus and GPT 5.5, comprehensively outperforming the previous Composer 2.
SWE-Bench is a software engineering benchmark created by a Princeton University research team, containing thousands of issues and corresponding pull requests extracted from real GitHub repositories, designed to evaluate AI models' ability to solve actual software engineering problems. Terminal Bench focuses on assessing models' ability to execute complex multi-step tasks in terminal environments, including file operations, environment configuration, and system debugging. Unlike traditional code completion evaluations, these benchmarks more closely mirror real development scenarios, requiring models to understand project context, identify root causes, and generate complete fix solutions.
On the comprehensive AI benchmark leaderboard, the model currently ranks eighth. Across various dimensions, it excels particularly in code writing, debugging, and logical reasoning. However, it falls slightly short in the creativity dimension — foreshadowing the frontend design aesthetic shortcomings revealed in subsequent hands-on tests.
A notable detail: Composer 2.5 is built on the same open-source base model as Composer 2 — Kimi K2.5 — but the Cursor team performed deep training optimization, particularly resolving many autonomous exploration and MCP (Model Context Protocol) stability issues that were long-standing pain points for previous Composer users.
Kimi K2.5 is an open-source large language model base released by Moonshot AI, featuring strong long-context processing and code comprehension capabilities. Cursor's strategy of deep fine-tuning on an open-source base rather than training from scratch significantly reduces R&D costs while enabling specialized optimization for programming scenarios. MCP (Model Context Protocol) is an open standard introduced by Anthropic in late 2024, designed to provide AI models with a unified interface for interacting with external tools, data sources, and development environments. In programming scenarios, MCP stability directly determines whether an AI agent can reliably read project files, execute terminal commands, and call third-party APIs. Composer 2's previous instability in this area seriously impacted user experience, and version 2.5 has made this a priority fix.
Hands-On Test 1: macOS Interface Clone
The first test asked the model to clone the macOS interface and create a web-based version of the system. Composer 2.5 performed well overall, excellently reproducing nearly all macOS features — users could even open various apps and folders, including Photos, Notes, Music, and Settings. It also generated a small game plus tools like Terminal and Calculator.
However, there were notable shortcomings: the top status bar was non-functional, and the Safari browser interface was mediocre. The tester gave it a 7 out of 10, noting that "in web development, it still can't fully match Opus."
Hands-On Test 2: Product Landing Page Generation
In the NVIDIA RTX 5090 landing page generation test, the gap between the three models became much more apparent. Composer 2.5 could indeed complete the work quickly, generating a basic landing page with multiple components, various animations, and layout styles, plus sound effects as requested.
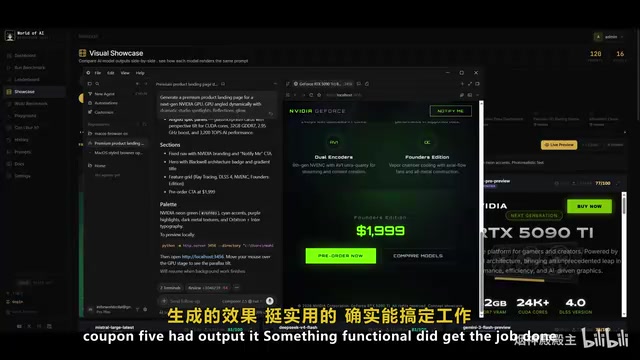
However, comparing it with GPT 4.5 and Opus 3.7's outputs, the difference was immediately obvious. GPT 4.5's NVIDIA GPU page had "excellent dynamic effects and outstanding details throughout the entire landing page"; Opus 3.7's result was "absolutely stunning," with nearly all components fully generated and completely meeting requirements. While Composer 2.5 was faster, it simply couldn't match those two models in visual quality, especially in frontend design aesthetics.
Hands-On Test 3: 3D Scene Generation and Speed Advantage
In the 3D scene generation test, Composer 2.5's speed advantage was fully demonstrated. The tester requested "an exquisite and interactive isometric 3D cozy cottage," and the model spent only about two seconds reasoning before completing the entire isometric 3D room in approximately 10 seconds — including bookshelves, wall paintings, and various other objects.
Isometric Projection is a three-dimensional projection method without perspective scaling, where the angles between all three coordinate axes are 120 degrees, commonly seen in strategy games and architectural visualization. The difficulty of AI models generating such 3D scene code lies in simultaneously handling geometric modeling, texture mapping, lighting calculations, and interaction logic, placing high demands on both spatial reasoning ability and code organization skills.
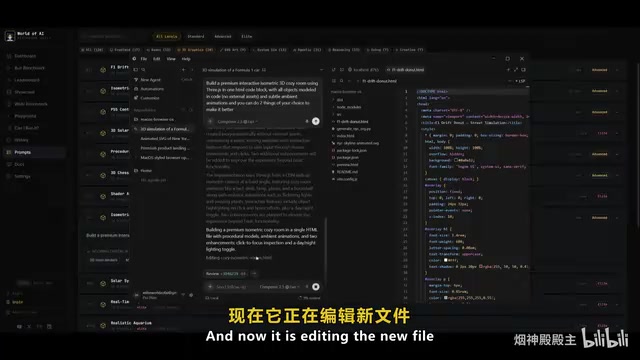
In the Figma file generation test, the model created a New York City scene featuring bridges, a city skyline, moving vehicles, the Statue of Liberty, and even day-night cycle effects — quality that "somewhat approaches what Sonnet or even Opus can generate in certain cases." In the F1 racing drift simulation test, it perfectly rendered the environment scene, automatically generating camera angles and various operational logic.
However, when compared with Opus's output quality in Three.js, there's "clearly a noticeable leap" between the two models. Three.js is currently the most popular JavaScript 3D graphics library, rendering complex three-dimensional scenes in browsers based on WebGL technology, widely used in data visualization, game development, and interactive web design. The level of detail and visual expressiveness Opus demonstrates in Three.js scene generation remains a height that Composer 2.5 currently struggles to reach.
Known Shortcomings and Usage Recommendations
Despite its impressive performance, Composer 2.5 still has some noteworthy issues:
- Insufficient frontend design aesthetics: Falls behind Opus in web development and design quality, with limited creative expressiveness
- Occasional execution stability fluctuations: Sometimes tasks fail to execute successfully after receiving instructions
- Single-minded problem-solving approach: Tends to fixate on one solution without providing pros-and-cons analysis
The tester offered practical advice: if you have high design quality requirements, you can compensate for the model's design shortcomings by providing more detailed prompt instructions, specifying aesthetic styles, and clearly defining development standards and details — this can still achieve results close to Opus's high standards. This strategy of using refined Prompt Engineering to compensate for model weaknesses is highly practical in real development — essentially combining human design judgment with the model's code execution capability, leveraging the strengths of each.
Conclusion: A High-Value Choice Balancing Speed and Intelligence
Composer 2.5 is an AI coding model that achieves a breakthrough in cost-effectiveness. While it hasn't fully reached Opus's level, it's nearly on par with Opus in version iteration, debugging quality, and agentic workflows. For developers who prioritize rapid iteration and are cost-sensitive, it's undoubtedly one of the most worthwhile AI coding tools to try right now.
With this release, the Cursor team has demonstrated an important trend: top-tier AI programming capability is rapidly democratizing. Developers no longer need to pay several dollars per task to get a coding experience approaching the strongest models. Behind this trend is the maturation of the open-source model ecosystem — when high-quality open-source base models (like Kimi K2.5) can be freely accessed and fine-tuned, startup teams can concentrate resources on scenario optimization and user experience rather than base model training, delivering competitive products at costs far below those of leading research labs.
Related articles
Freely Switch Between Claude/DeepSeek and Other AI Models in Codex: CPA Deployment Guide
Learn how to use CLI Proxy API (CPA) to aggregate Claude, DeepSeek, Grok, and Gemini models into OpenAI Codex via VPS deployment, Docker setup, and Codex++ integration.
Codex vs Claude Code: An In-Depth Comparison of AI Coding Agents
In-depth comparison of Codex, Claude Code, and Cursor across pricing, features, GitHub integration, and team collaboration to help developers pick the best AI coding agent.

Use Claude Code for Just ¥7.9: A Complete Guide to Affordable Alternatives with Chinese AI Models
Learn how to set up Claude Code with affordable Chinese AI model alternatives. Use providers like SiliconFlow and DeepSeek starting from just ¥7.9, with full environment variable configuration guide.