Deconstructing the Core Principles of AI Agents: A Deep Dive into the Control, Perception, and Action Modules
A deep dive into AI Agent architecture: Control, Perception, and Action modules with classic implementations.
This article systematically deconstructs AI Agent architecture into three core modules — Control (the brain), Perception (eyes and ears), and Action (hands and feet). It analyzes four classic implementations: AutoGPT's prompt engineering, BabyAGI's recursive task decomposition, HuggingGPT's multi-model collaboration, and LlamaIndex's RAG-based knowledge system. It also covers Chain-of-Thought reasoning strategies including standard CoT, CoT-SC voting, and Tree of Thoughts search.
LLMs hallucinate, lack real-time information, and can't handle complex calculations — these "artificial idiocy" moments are a constant headache. The Agent architecture was born to solve exactly these problems. There's nothing mystical about it — at its core, it's simply LLM + external tools + execution workflow. This article systematically deconstructs the core principles, common architectures, and practical applications of AI Agents.
The Essence of Agents: A "Plugin System" for LLMs
If you think of an LLM as a battery, then an Agent is the complete electric vehicle. LLMs possess powerful language understanding capabilities, but they have three fatal shortcomings:
- Hallucination: Generating content that sounds plausible but is actually fabricated
- Knowledge lag: Unable to access real-time information, such as today's weather or the latest news
- Computational inability: Struggling with complex mathematical operations (e.g., calculus)
LLM hallucination stems from the generation mechanism itself — the Transformer architecture predicts the next token based on probability rather than retrieving facts from a verifiable knowledge base. During training, the model learns statistical patterns of language rather than building logical reasoning chains. When the model encounters domains insufficiently covered in its training data, it "fabricates" plausible-sounding content based on learned language patterns. This is why hallucination is particularly severe in specialized domains (such as medicine and law) — training data for these fields is relatively scarce, yet the model still confidently provides answers.
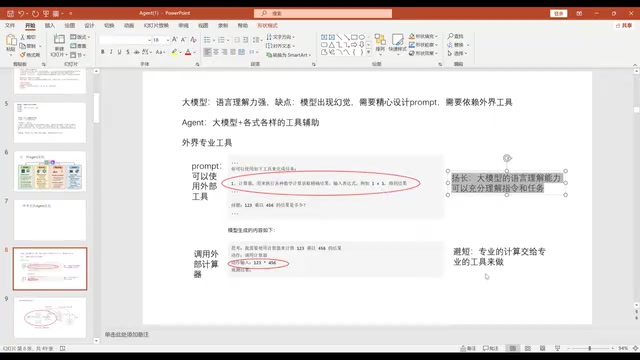
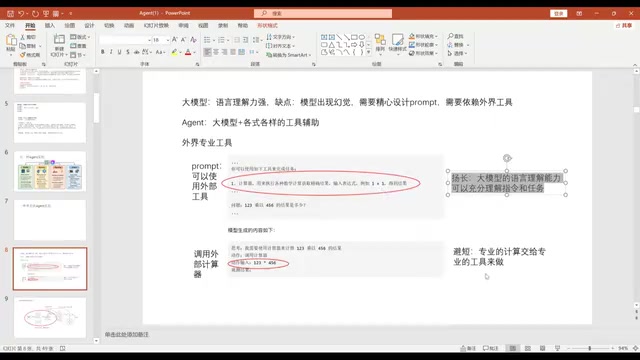
The core philosophy of Agents is to leverage strengths while compensating for weaknesses — using the LLM's powerful language understanding to "direct" external tools to complete specialized tasks. The LLM handles intent understanding and step planning, while the actual execution is delegated to calculators, search engines, API endpoints, and other external tools.
The Three Core Modules of an Agent: Control, Perception, and Action
A complete Agent architecture can be broken down into three modules, corresponding to the LLM's "brain," "eyes and ears," and "hands and feet."
Control Module — The Agent's Brain
The control module is the Agent's core, responsible for five key capabilities:
- Natural Language Processing: Understanding user intent — this is the LLM's bread and butter
- External Knowledge Acquisition: Supplementing knowledge the LLM doesn't possess through methods like RAG, such as company policies or real-time news
- Memory System: Including short-term memory (multi-turn conversation context) and long-term memory (historical interaction data)
- Reasoning and Planning: Decomposing complex tasks into subtasks. For example, the question "Who was Alibaba's CTO during the Trump era?" requires first determining Trump's term dates, then querying Alibaba's CTO during that period
- Transfer and Generalization: Flexibly adapting to different scenarios and contexts
RAG (Retrieval-Augmented Generation) is a technical paradigm proposed by Facebook AI Research in 2020. Its core idea is to retrieve relevant document fragments from an external knowledge base before the LLM generates an answer, injecting the retrieved results as context into the prompt so the model generates answers based on real data. This approach effectively mitigates hallucination and knowledge lag issues, since the knowledge base can be updated at any time without retraining the model. Key components of RAG include: document chunking, vectorization (Embedding), similarity retrieval, and context assembly.
Perception Module — The Agent's Eyes and Ears
The perception module handles multimodal inputs: text, images, audio, and more. It's essentially an application of multimodal technology — converting images to encodings, speech to text, and ultimately interfacing with the language model.
The core challenge of multimodal technology lies in mapping information from different modalities into a unified semantic space. Taking vision-language models as an example, a Vision Transformer (ViT) is typically used to split images into patches and encode them as vector sequences, then a cross-modal alignment module (such as Q-Former or linear projection layers) maps visual features into the language model's embedding space. For the audio modality, ASR (Automatic Speech Recognition) models like Whisper convert audio to text, or audio encoders directly extract acoustic features. This multimodal fusion enables Agents to handle the diverse input forms found in the real world.
Action Module — The Agent's Hands and Feet
The action module is the Agent's execution layer. The most basic output is text, while advanced capabilities include: calling calculators for mathematical operations, calling weather APIs for real-time information, calling image generation models to create pictures, calling speech models for audio narration, and more.
Agents in Practice: Four Classic Architecture Analyses
AutoGPT: Prompt Engineering Taken to the Extreme
AutoGPT is essentially a meticulously designed prompt engineering framework. Its input includes: task objectives, constraints, available tools (such as Google Search, browser), available resources, and output format specifications. The LLM understands and executes tasks based on this comprehensive contextual information.
Prompt Engineering is far more than simple text concatenation. In Agent scenarios, it involves the structured design of System Prompts, including role definition, capability boundary declarations, tool descriptions (typically in JSON Schema format), output format constraints, and more. High-quality prompts must account for the model's attention allocation mechanism — Transformer self-attention exhibits a "Lost in the Middle" phenomenon when processing very long contexts, making the positional arrangement of key information crucial. Additionally, the selection and ordering of few-shot examples significantly impact model performance.
However, AutoGPT has two obvious limitations: first, a high model threshold — small-parameter models struggle to understand such complex prompts, typically requiring models with over 10 billion parameters; second, poor transferability — prompts tuned for GPT may completely fail on LLaMA, requiring adjustments for each model.
BabyAGI: Task Decomposition and Recursive Execution
BabyAGI's core idea is to recursively decompose complex tasks into subtasks, then execute them one by one.
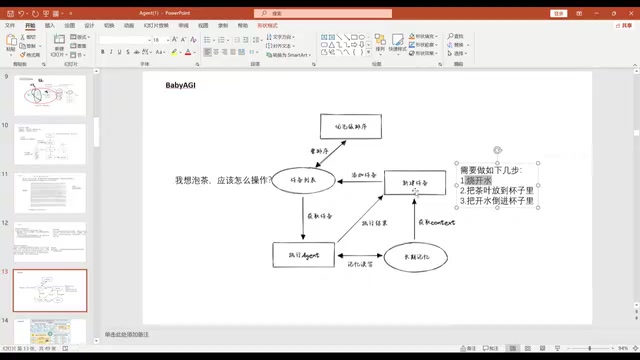
Take "How should I make tea?" as an example: the LLM first decomposes the task into three steps — boil water, buy tea leaves and put them in a cup, pour the boiling water. Then for the subtask "boil water," the LLM is called again to produce finer steps: put cold water in the kettle, plug it in. This recursion continues until each subtask is simple enough to execute directly.
The core difficulty of this approach lies in workflow design — how to reasonably decompose tasks and how to aggregate all subtask results into a final answer.
HuggingGPT: Multi-Model Collaborative Agent
HuggingGPT demonstrates a more complex Agent pattern — task decomposition + model selection + multi-model collaboration.
For example, given an image with the instruction "Generate an image of a little girl reading a book, with the same pose as the original image," the system would:
- Call a pose estimation model to extract the pose from the original image
- Call a pose-to-image generation model to create the target image
- Call an object detection model to frame the generated result
- Call an image captioning model to convert it to text
- Call a speech model for audio narration
This architecture can handle complex tasks that a single model cannot process end-to-end, but excessively long pipelines are its greatest risk — an error at any stage affects everything downstream. Currently, such solutions are still at the demo stage, solving the "can it be done at all" question, and are still far from production-grade reliability.
LlamaIndex: A RAG-Based External Knowledge System
LlamaIndex focuses on augmenting model memory and is a classic implementation of RAG (Retrieval-Augmented Generation). It stores external knowledge in various data structures and provides multiple retrieval methods:
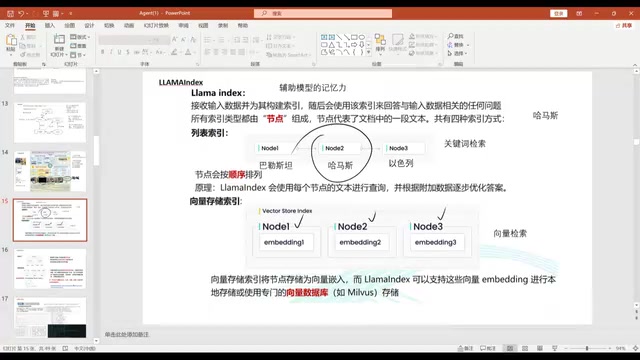
- Keyword Retrieval: Exact matching — searching for "Hamas" only finds documents containing that exact keyword
- Vector Retrieval: Semantic matching — searching for "Hamas" can also surface related content about "Palestine," "Israel," etc.
- Tree-based Retrieval: Organizes knowledge in hierarchical structures, such as "Middle East situation → Israeli-Palestinian conflict → Hamas," allowing retrieval of context from the entire branch
- Knowledge Graph: Multi-hop retrieval through entity relationships, providing stronger associative connections
The core of vector retrieval is converting text into high-dimensional vectors (typically 768 or 1536 dimensions) through Embedding models (such as OpenAI's text-embedding-ada-002, BGE, etc.), then calculating semantic similarity using cosine similarity or Euclidean distance. Unlike traditional keyword retrieval that relies on exact character matching, vector retrieval captures similarity at the semantic level. To achieve efficient retrieval among massive vectors, Approximate Nearest Neighbor (ANN) algorithms are typically used, such as HNSW (Hierarchical Navigable Small World graphs) and IVF (Inverted File Index), combined with vector databases (such as Milvus, Pinecone, Weaviate) to achieve millisecond-level retrieval.
Knowledge Graphs store structured knowledge in the form of triples (entity-relationship-entity), such as (Hamas, located_in, Gaza Strip), (Gaza Strip, belongs_to, Palestine). Multi-hop retrieval refers to multi-step reasoning along entity relationship chains — starting from "Hamas," passing through "Gaza Strip" to reach "Palestine," then connecting to "Israel." This structured knowledge representation enables Agents to perform logical reasoning rather than relying solely on semantic similarity. Typical knowledge graph tools include Neo4j, Apache Jena, etc., and combining knowledge graphs with LLMs (GraphRAG) is a current research hotspot.
This is particularly important in enterprise vertical scenarios — for example, building an internal company policy Q&A system by vectorizing and storing policy documents, retrieving relevant content when employees ask questions, and having the LLM generate accurate answers.
Chain-of-Thought (CoT): Teaching LLMs to "Think Step by Step"
Chain-of-Thought is a crucial reasoning strategy in Agents. The core idea is: don't expect the LLM to get it right in one shot — instead, guide it to reason step by step.
Chain-of-Thought (CoT) was proposed by the Google Brain team in 2022, with its theoretical foundation rooted in the cognitive science concept of "working memory." When humans solve complex problems, they externalize intermediate steps (such as writing equations on paper) to reduce working memory burden. Similarly, having an LLM explicitly output intermediate reasoning steps is like providing the model with "scratch paper" — each intermediate token becomes a conditional input for subsequent reasoning, effectively extending the model's reasoning depth. Research shows that CoT effectiveness is positively correlated with model scale, typically emerging reliably only in models with 100B+ parameters.
Standard CoT: Showing the Reasoning Process
Take a math problem as an example: "Roger has 5 tennis balls. He buys 2 cans of 3 tennis balls each. How many does he have now?" If you only give the LLM a sample answer, it might get it wrong. But if you show the calculation process in the example (5 + 2×3 = 11), the LLM learns the reasoning steps and can correctly answer similar questions.
CoT-SC: Self-Consistency Voting for Higher Accuracy
Leveraging the randomness of LLM outputs, the same question is called multiple times (or called on different models), and then the results are voted on, selecting the most frequently occurring answer as the final result. This effectively improves accuracy.
ToT (Tree of Thoughts): Search, Evaluation, and Backtracking
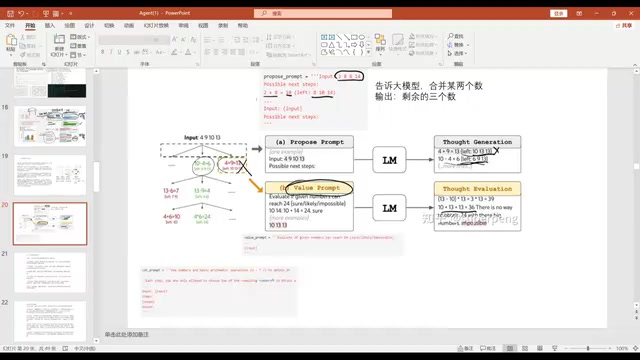
ToT is the most complex reasoning architecture, featuring search, evaluation, and backtracking capabilities. Take the Game of 24 as an example: given four numbers, the LLM first tries combining two of them, generating multiple candidate solutions; then the LLM evaluates each solution's likelihood of reaching 24, pruning infeasible branches; finally, it recursively solves along the optimal path. This is essentially having the LLM perform tree search and pruning.
ToT fundamentally introduces classical search algorithms into the LLM reasoning process. Its search strategy draws from Breadth-First Search (BFS) and Depth-First Search (DFS), while evaluation and pruning resemble Alpha-Beta pruning or Monte Carlo Tree Search (MCTS) — the latter being the core algorithm behind AlphaGo. In ToT, the LLM simultaneously plays two roles: "generator" (producing candidate solutions) and "evaluator" (judging solution feasibility), finding optimal solutions through a self-play style search. The cost of this approach is significantly increased computational overhead, with a single inference potentially requiring dozens of model calls.
Limitations and Future Outlook for Agents
Despite the promising prospects of Agent architectures, five core challenges remain:
- Heavy dependence on LLM capability: If the battery is weak, even the best electric car is useless
- Long pipelines are error-prone: In a serial structure, failure at any single link causes the entire system to fail
- Low efficiency from multiple calls: Repeatedly calling the LLM introduces latency and cost issues
- Weak transferability: Prompts tuned for GPT may fail when switched to other models
- High dependence on prompt design quality: An Agent's performance ceiling is determined by the prompt engineer's skill
However, in the long run, simply scaling up LLM parameters has a capability ceiling, and while end-to-end solutions are ideal, they cannot solve all complex problems. The Agent's "divide and conquer" architecture will become the mainstream paradigm for deploying LLMs in production — ultimately, all LLM products will be delivered in the form of Agents.
Related articles
Free Full-Power GPT on AI Aggregation Platforms? The Risks and Truth Behind Shared Accounts
Deep analysis of AI aggregation platforms promoted on Bilibili, exposing privacy leaks and legal risks of shared account pools for free GPT and Claude access, plus safe alternatives like OpenRouter and DeepSeek.
GPT, Claude, Gemini vs. China's Top Three: A Complete Comparison of Coding Ability, Chinese Language Performance & Pricing
A side-by-side comparison of GPT, Claude, Gemini, Tencent Hunyuan, Qwen, and DeepSeek across coding ability, Chinese language performance, and API pricing to help you find the best fit.
Learn to Code with AI from Scratch: A Complete Learning Path from Beginner to Deployment
A complete learning path for coding with AI from scratch — from concepts and environment setup to using Cursor, Claude, and other AI tools to build and deploy your first project.