Deep Dive into Claude Cloud Agent Memory System Architecture: CMA Design Philosophy and Technical Choices
Deep dive into Anthropic CMA's file-first memory architecture, Dreaming mechanism, and cross-Agent memory reuse design.
This article reverse-engineers Anthropic's Cloud Managed Agents (CMA) memory system, revealing its file-first storage strategy that avoids Embedding complexity, the FUSE-based cross-Agent memory store reuse abstraction, and the Dreaming mechanism for asynchronous memory consolidation. It compares CMA with Claude Code's memory system and explains the engineering philosophy behind key design trade-offs.
Anthropic recently launched its ambitious next-generation product—Cloud Managed Agents (CMA), upgrading Claude Code from a local tool to a cloud-hosted Agent service. This article is based on a deep reverse-engineering analysis of the CMA memory system, breaking down its core design philosophy, technical choices, and key differences from the Claude Code memory system.
What Are Cloud Managed Agents?
CMA is essentially Anthropic's "Agent as a Service" product. Unlike the locally-running Claude Code, CMA fully hosts the Agent on Anthropic's cloud infrastructure, making it closer to a cloud service paradigm.
Agent as a Service (AaaS) is an emerging cloud service model following SaaS and PaaS. Traditional AI API services (like the OpenAI API) provide single-inference capabilities, while AaaS hosts the complete Agent lifecycle—including task planning, tool invocation, state management, and error recovery—entirely in the cloud. The rise of this model stems from real-world challenges in enterprise Agent deployment: locally-running Agents are constrained by single-machine compute power, network stability, and operational costs, making it difficult to support complex workflows that need to run for extended periods. CMA's launch marks Anthropic's strategic transformation from a model provider to an Agent platform operator.
From an architectural perspective, CMA's core Harness (i.e., the Agent runtime engine) is still Claude Code, but it externalizes all dependent capabilities—Session storage, external orchestration, sandbox execution, tool invocation, MCP integration—to the cloud platform. This is fundamentally different from the earlier Remote Control approach: Remote Control remotely controls a Claude Code instance running on the user's local machine, while CMA runs Claude Code directly on Anthropic's cloud.
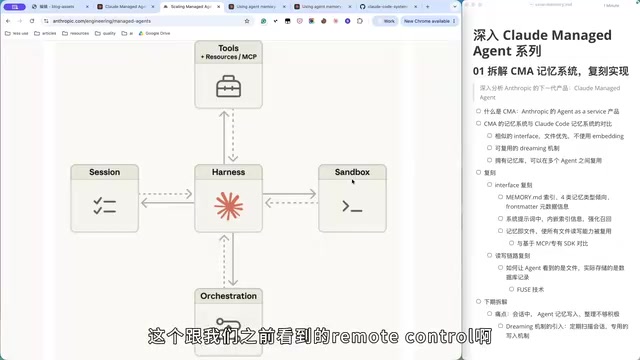
The core value of this architectural design lies in supporting long-running Agent tasks. When an Agent needs to execute complex orchestrations continuously for hours or even days, the limitations of local execution become apparent—network disconnections, machine sleep, and killed processes can all interrupt tasks—while cloud hosting naturally provides elastic scaling and high availability.
Core Comparison: CMA vs. Claude Code Memory Systems
Shared Design DNA
The CMA and Claude Code memory systems share a significant amount of underlying design, stemming from their common core engine—the Claude Agent SDK. Key commonalities include:
File-first, no Embedding. This is the technical direction Anthropic has consistently maintained for memory. They have never introduced a vector layer for RAG or semantic retrieval, instead fully leveraging the Agent's ability to understand files.
To understand the deeper logic behind this choice, one needs to understand the real-world pain points of Embedding and RAG solutions. Embedding is the technology of converting text into high-dimensional vector representations, forming the foundation of RAG (Retrieval-Augmented Generation) systems. A typical RAG workflow involves: chunking knowledge base documents, converting them to vectors via an Embedding model, storing them in a vector database (such as Pinecone or Milvus), vectorizing user queries for similarity search, and injecting retrieved results as context into the LLM. The pain points of this approach include: chunk splitting strategies directly impact retrieval quality, Embedding models have limited expressiveness for specialized terminology, vector similarity doesn't equal semantic relevance, and index updates have latency. Furthermore, as context windows expand from 4K to 200K and beyond, the brute-force approach of feeding complete files directly to the model is already "good enough" in many scenarios, making RAG's engineering complexity more of a burden.
From a practical standpoint, Anthropic's choice effectively avoids the additional complexity and instability that Embedding introduces—vector retrieval quality is often limited by the Embedding model's expressiveness, while directly operating on files allows the Agent to leverage its powerful contextual understanding for more precise information extraction.
Shared Dreaming mechanism. Both reuse a memory consolidation mechanism called "Dreaming" (analyzed in detail later).
Key Difference: Cross-Agent Memory Store Reuse Abstraction
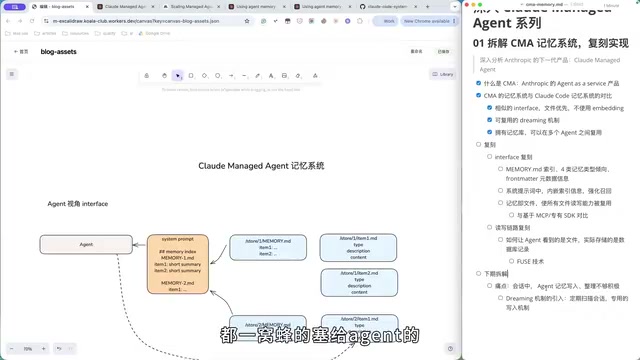
The most critical difference in CMA's memory system is the introduction of the "Memory Store" abstraction layer. Claude Code's memory is stored directly on the user's local machine, while CMA's memory stores support cross-Agent reuse.
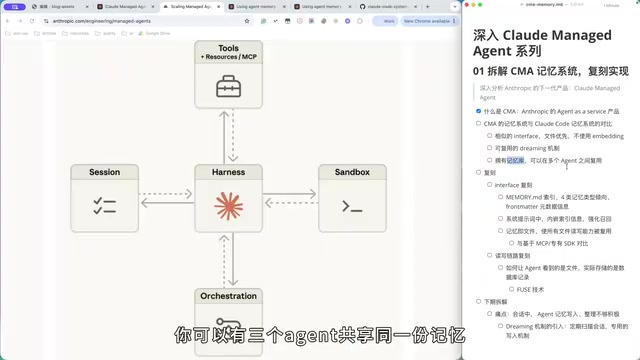
Specifically, you can have three cloud Agents share the same memory store while each Agent also maintains its own independent memory. This design is extremely valuable in practical scenarios—for example, a code review Agent and a documentation writing Agent can share project context memory while each retains its own specialized work preference memory.
To enable this reuse capability, CMA's data pipeline is fundamentally different from local Claude Code. Based on reverse engineering analysis, CMA most likely employs FUSE (Filesystem in Userspace) technology: memory files are actually stored in a database, but the Agent still sees a standard filesystem interface when operating.
FUSE is a technology framework that allows non-privileged users to create custom filesystems in userspace, originally developed by the Linux community. Traditional filesystems run in kernel space, and modifying or extending them requires writing kernel modules—an extremely high barrier. FUSE provides a generic filesystem bridge module in the kernel that forwards file operation requests to a userspace daemon for processing. This means developers can implement filesystem logic in any programming language—for example, disguising database queries as file reads or mapping network storage as local directories. In CMA's scenario, FUSE allows the Agent to access memory data actually stored in a distributed database using standard file I/O operations (open, read, write) without modifying the Agent's core code logic.
This design maintains the consistency of the "file-first" approach while achieving flexibility and shareability in the underlying storage.
No Embedding, No MCP: The Deeper Logic Behind Design Trade-offs
Anthropic's technical choices for the memory system reflect strong deliberate trade-offs. Not using Embedding, not relying on MCP or dedicated SDKs—these "not doing" decisions are backed by a clear engineering philosophy:
Reducing system complexity. Embedding solutions require maintaining vector databases, handling index updates, and tuning retrieval parameters—each layer is a potential failure point. The file-based approach has an extremely simple pipeline—read files, write files, understand file content—the Agent itself is the best "retrieval engine."
Improving debuggability. Files are human-readable; developers can directly view and edit memory content, while information in vector space is nearly uninterpretable. When Agent behavior becomes anomalous, developers can directly open memory files to check whether their content is correct—this is enormously valuable for troubleshooting in production environments. In contrast, high-dimensional vectors in vector databases are completely opaque black boxes to humans.
Fully leveraging model capabilities. As context windows continue to expand (from early 4K to today's 200K) and model comprehension improves, having models directly process structured files already works well enough, and Embedding's marginal returns are diminishing. Anthropic is clearly betting that continued growth in model capabilities will further reduce the necessity of RAG solutions.
Agent Memory Write Proactiveness: Core Pain Point and the Dreaming Solution
Whether for CMA or other Agent systems, memory retrieval can be optimized through prompt engineering—for example, "when the user mentions identity information, proactively query memory." But writing is a deeper challenge.
Current Agents generally lack the ability to spontaneously decide to write to memory during long conversations. In practice, whether it's frontier Agents or simple developer-built Agents, most still rely on users explicitly prompting "remember this for me." Agents' autonomous memory write triggers are extremely passive, and when memory accumulates to a certain volume, consolidation and deduplication similarly lack proactiveness.
Autonomous Agent memory writing is one of the recognized hard problems in the AI Agent field today. The root of the problem is: the model needs to judge "what information is worth remembering long-term" while simultaneously executing tasks—this itself is a higher-order decision requiring metacognitive ability. Current mainstream approaches in the industry include: rule-based triggers (e.g., automatically recording when user preference expressions are detected), importance-score-based writing (e.g., the importance scoring mechanism proposed in Stanford's Generative Agents paper, which has the LLM score each piece of information from 1-10 on importance to decide whether to write to long-term memory), and explicit user command triggers. But these approaches either have insufficient coverage or cause memory bloat through excessive writing.
To address this pain point, Anthropic introduced the Dreaming mechanism: the system periodically scans conversation history and comprehensively consolidates existing memory through a proprietary write process. Even if memory writes weren't triggered in time during conversation, as long as the conversation data still exists, Dreaming can retroactively record it.
The naming of the Dreaming mechanism is no coincidence—it directly draws from cognitive neuroscience research on sleep and memory consolidation. The human brain continuously receives information while awake, but true memory integration—including the transfer of short-term to long-term memory, forgetting of irrelevant information, and strengthening of associated memories—primarily occurs during sleep, especially during rapid eye movement (REM) sleep. The brain "replays" daytime experiences, filters out important information, and encodes it into long-term storage. CMA's Dreaming mechanism follows the same paradigm: the Agent focuses on current work while "awake" executing tasks, while memory consolidation, deduplication, and structuring are handled by an independent asynchronous process during "offline" time. This design avoids the interference of real-time memory writing on task execution while ensuring memory quality.
This essentially downgrades "real-time memory" to "asynchronous memory," replacing non-deterministic real-time triggers with deterministic batch processing—a very pragmatic engineering approach.
Summary: Transferable Value of CMA's Memory Architecture
CMA's memory system design reflects Anthropic's consistent engineering style: making clear trade-offs on key technical choices (file-first, no Embedding), pursuing practicality in product capabilities (memory store reuse, Dreaming mechanism), and maintaining simplicity and extensibility in architecture (FUSE abstraction layer).
The design philosophy of this memory system is not limited to CMA itself. Its core principles—file-first storage, on-demand retrieval, and asynchronous batch write consolidation—are fully transferable to other Agent frameworks. For developers building Agent memory systems, Anthropic's approach provides a reference architecture validated at scale.
It's worth noting that this architecture's applicability is closely tied to the development of model capabilities. As context windows continue to expand and model reasoning capabilities continue to strengthen, the advantages of the "file-first" strategy will only become more apparent. And the Dreaming mechanism, as a general asynchronous memory consolidation paradigm, can be adopted by any Agent framework regardless of the underlying storage solution.
Related articles
Musk's Never Give Up Philosophy: From Near Bankruptcy to Industry Disruption
Decoding the real stories behind Musk's 'I don't ever give up' — from SpaceX's three failed launches to Tesla's production hell, and what his extreme persistence means for tech entrepreneurs.

Claude Code with Local LLMs: Token-Free Deployment Guide & Configuration
Learn how to connect Claude Code to local LLMs for token-free AI coding. Covers three-layer architecture, Ollama/LM Studio/vLLM setup, protocol translation, and hardware selection.
Inventory-Free Game Design and Godot Sprite Occlusion Sorting: A Practical Tutorial
Explore inventory-free game design with mouse-drag interactions. Learn Godot sprite occlusion sorting pitfalls and solutions, plus AI-generated shader tips.