Deep Module Architecture in Practice: Fixing a Codebase Wrecked by AI
Use deep module architecture to fix codebases degraded by AI-assisted coding.
AI-assisted coding accelerates codebase decay by generating code faster than teams can review it. This article introduces deep module architecture based on Ousterhout's A Philosophy of Software Design, covering key concepts like deep vs. shallow modules, seams, and adapters. It provides a systematic approach to improving codebase quality through better locality, leverage, and testability.
AI Is Accelerating Codebase Collapse
You've probably seen countless CEOs on LinkedIn proclaiming that "code is getting cheaper" and "development speed is unprecedented." But the reality is that AI hasn't made code better — it's only accelerated the collapse of codebases.
Every change made without considering the big picture can introduce small problems: "quirks" that make the code harder to modify. Over time, these issues snowball until you end up with a massive "Big Ball of Mud" — a tangled, nearly irreversible mess of bad code. The "Big Ball of Mud" concept was formally introduced by Brian Foote and Joseph Yoder in 1997 to describe a system lacking any discernible structure: code grows haphazardly, module boundaries are blurred, and dependency relationships are hopelessly tangled. This architecture is so prevalent because it's often the "path of least resistance" in the short term — every time requirements change, developers tend to patch existing code directly rather than redesign. In the context of AI-assisted coding, this problem is amplified further: AI generates code far faster than humans can review and design it. Without architectural constraints, AI will accelerate the Big Ball of Mud's growth with alarming efficiency.
The good news is that with some classic software design principles, even a seemingly hopeless codebase can be rescued. This article draws on hands-on experience to systematically explain the key concepts behind the deep module architecture methodology, helping you master the critical skill of "improving codebase architecture."
Core Concepts: Building a Shared Architectural Vocabulary
Before fixing a codebase, you need to master a precise set of terminology. This is crucial not only for human-to-human collaboration but equally important for working with AI — when you and AI share a common vocabulary, you can communicate in the same language and describe your architectural needs more precisely.
This vocabulary has been included in a GitHub skills repository with 41.5K stars, demonstrating its recognition within the developer community. Let's break down each core concept.
Module: The Basic Building Block of an Application
A module is an independent unit of functionality within an application. It can take many forms:
- A set of React components that combine to form a page
- A set of functions that handle authentication logic entirely
- A logger responsible for writing logs to the console, files, or third-party services
In a well-structured codebase, these modules communicate with each other through their respective interfaces.
Interface: Everything a Caller Needs to Know
An interface is all the information a caller needs to correctly use a module. For an authentication module, its interface might include a login method and a logout method.

But an interface is more than just method signatures. It also includes somewhat fuzzier information — conventions and documentation about how to call the module. The implementation, on the other hand, is the concrete logic inside the module: what actually happens when you call login or logout.
This is the core primitive we're discussing: modules with both an interface and an implementation, distributed throughout the application.
Deep Modules vs. Shallow Modules: The Dividing Line of Architecture Quality
This is the most critical concept in the entire methodology, originating from John Ousterhout's classic book A Philosophy of Software Design. Ousterhout is a professor of computer science at Stanford University and co-inventor of the Tcl scripting language and the Raft consensus algorithm. Unlike Robert C. Martin's Clean Code, which emphasizes cleanliness at the code level, Ousterhout focuses on complexity management at the module level. His core argument is that the primary goal of software design is to reduce complexity, and the essential sources of complexity are twofold — dependencies and obscurity. The deep module concept is a direct product of this philosophy: by encapsulating complexity behind simple interfaces, you simultaneously reduce both dependencies and obscurity. Notably, this book also directly challenges the popular notion that "classes should be as small as possible," arguing that excessive decomposition actually creates more shallow modules and higher system complexity. Understanding the difference between deep and shallow modules is key to evaluating codebase architecture quality.
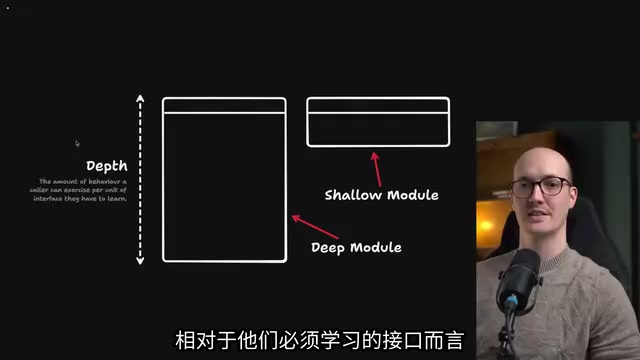
Deep Modules: The Hallmark of Excellent Architecture
A deep module hides a large amount of implementation detail behind a relatively simple interface. Callers only need to understand a small interface to access all the complex functionality behind it.
Excellent open-source libraries like TanStack Query are exemplary deep modules — they hide enormous complexity while exposing only a clean interface. TanStack Query (formerly React Query), created by Tanner Linsley, is considered a deep module exemplar because behind a concise useQuery/useMutation API, it handles extremely complex underlying concerns: automatic caching and cache invalidation, request deduplication, background data refetching, optimistic updates, pagination and infinite scrolling, offline support, garbage collection, and more. Developers only need to pass in a query key and an async function to gain all of these capabilities. Without this deep module, developers would need to manually manage loading/error/success states, handle race conditions, and write caching logic — code that often ends up scattered across dozens of components, creating a classic low-locality problem. Other exemplary deep modules include the date handling library date-fns and the HTTP client axios.
What we mean by "depth" is the ratio of behaviors a caller can trigger relative to the interface they must learn. The higher the ratio, the deeper the module, and the better the architecture.
Shallow Modules: A Signal of Code Rot
Shallow modules are the exact opposite: they have complex interfaces but not much implementation behind them. This means callers need to learn a lot of interface knowledge but get very little functional return.
The core reason deep modules are superior to shallow modules is that they hide more information from callers, reducing cognitive load and improving development efficiency. If you find your codebase riddled with shallow modules, it's often a clear signal of architectural decay.
Seams and Adapters: The Keys to a Testable Architecture
Deep modules alone aren't enough — you also need to understand how modules connect to each other. The concepts of seams and adapters determine whether your codebase has good testability and replaceability.
Seams: The Gaps Between Modules
Modules interact with each other, forming a dependency graph. The gaps between modules — where module interfaces live — are called seams.
Seams are the critical points where you perform unit testing or integration testing. For example, if you want to test a module in isolation, you need to insert a mock object at the seam. Mock objects belong to the "test double" family, which also includes stubs (returning preset data), spies (recording call information), and fakes (providing simplified but working implementations). Gerard Meszaros systematically categorized these concepts in xUnit Test Patterns. The core value of using test doubles at seams is isolation: you can verify business logic correctness without starting a database, connecting to a network, or depending on external services. However, overusing mocks is also a common anti-pattern — if you find you need to mock a large number of dependencies to test a single module, it usually means the module's seam design is poor, or the module itself has taken on too many responsibilities.
Figuring out where seams should go is a critical step toward good architecture.
Adapters: Concrete Implementations at the Seams
Once you've identified where a seam should be, you need something concrete to satisfy that interface — this is the adapter, a concept borrowed from Hexagonal Architecture. Hexagonal Architecture was proposed by Alistair Cockburn in 2005 and is also known as "Ports and Adapters" architecture. Its core idea is to completely decouple an application's business logic from the outside world (databases, UI, third-party APIs, etc.). In this architecture, "ports" define abstract interfaces for interaction between business logic and the external world, while "adapters" are the concrete implementations of those interfaces. This design allows the same business core to be invoked by different drivers (such as REST APIs, CLIs, or message queues) and to connect to different driven sides (such as MySQL, PostgreSQL, or in-memory databases). Hexagonal Architecture, along with the later Onion Architecture and Clean Architecture, together form the infrastructure layer theory of modern Domain-Driven Design (DDD). Their shared principle is: the direction of dependencies should always point inward toward the business core, never outward toward technical details.
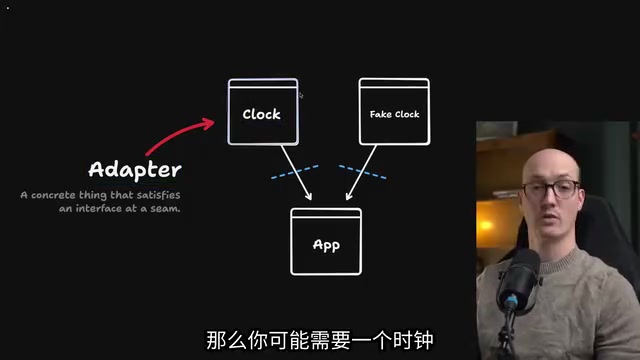
Here's a classic example: if your application depends on a running clock, you might need:
- A real clock adapter: uses the system's real-time clock, for production environments
- A fake clock adapter: for testing environments, so you don't have to actually wait two weeks to complete a test
Both satisfy the interface at the same seam but provide different implementations. This is how seams and adapters work together — allowing your codebase to flexibly switch between different scenarios without modifying core logic.
Two Core Benefits of Deep Modules
With the above concepts understood, we can summarize the two key benefits of deep module architecture:
1. Locality: Changes No Longer Ripple Everywhere
Modifications, bug fixes, and all related changes are concentrated within that single deep module. If logic is scattered across multiple modules, you face the predicament of low locality — fixing one bug requires changing ten files.
The locality principle has deep theoretical roots in software engineering. It's closely aligned with classic principles like "Separation of Concerns" and "High Cohesion, Low Coupling," but places greater emphasis on aggregation along the dimension of change. Kent Beck expressed a similar idea in his design heuristic: "put things that change together, together." In practice, a codebase with low locality has a telltale symptom: "Shotgun Surgery" — a code smell defined by Martin Fowler in Refactoring, referring to a logical change that requires small modifications across multiple classes or modules. In modern frontend development, React's component model and Vue's Single File Components (SFC) are both embodiments of the locality principle — placing template, logic, and styles in the same file because they always change together.
High locality means: group important things that frequently change together and keep them in one place. This not only reduces the probability of errors but also dramatically lowers the difficulty of code reviews.
2. Leverage: Drive Maximum Functionality with Minimal Interface
The deeper the module, the greater the leverage its users gain. In other words, each unit of interface carries more capability. Callers only need to learn a small amount of interface knowledge to drive a large amount of underlying behavior.
This leverage effect is especially evident in team collaboration: new members ramp up faster, and cross-team communication costs are lower.
Practical Advice: Start Improving Your Codebase Today
To apply these concepts to actual codebase repair, follow these steps:
- Identify existing modules: Map out the functional units in your codebase and determine which are deep modules and which are shallow modules
- Locate seams: Find the dependency relationships between modules and determine where interfaces should be placed
- Introduce adapters: Introduce the adapter pattern at critical seams to improve testability
- Merge shallow modules: Consolidate overly fragmented shallow modules into deeper modules to improve locality
- Share the vocabulary with AI: When using AI-assisted programming, use this precise terminology to describe your architectural intent
Codebase decay doesn't happen in a day, and fixing it won't happen overnight either. But once you've mastered the core concepts of deep modules, seams, and adapters, you have a scalpel that lets you precisely refactor your codebase instead of starting from scratch. In an era where AI accelerates everything, this architectural skill is more important than ever.
Related articles

MCP vs Skills: Understanding the Key to AI Testing Efficiency
Understand the key differences between MCP (Model Context Protocol) and Skills through practical analogies and real testing scenarios to boost AI-driven test automation efficiency.
The Essential Difference Between Skill and MCP: A Kitchen Analogy That Makes It Crystal Clear
Skill and MCP are two easily confused core concepts in AI Agent development. This article uses a kitchen analogy to explain how Skill (recipe/methodology) and MCP (kitchen assistant/tool connection) differ and work together.
Ponytail Plugin: The Minimalist Philosophy That Makes AI Coding Agents Write Less Code
Ponytail is a minimalist plugin for Claude Code that uses YAGNI principles and a decision ladder to cut AI-generated bloat. Tests show 47%-77% cost savings and 94% less code.