DeepSeek Image Recognition Mode Tested: Screenshot-to-Code Achieves Up to 80% Accuracy
DeepSeek's image recognition mode excels at screenshot-to-code, achieving ~80% UI replication accuracy.
DeepSeek's newly launched image recognition mode shines not in facial recognition but in converting UI screenshots to front-end code. Tests across Ant Design, Baidu, Bilibili, and Apple websites show approximately 80% layout accuracy. The feature serves as a rapid prototyping tool for developers and designers, competing with tools like v0.dev and Bolt.new, though it currently lacks interaction logic and image asset reproduction.
Image Recognition Mode Fully Launched: The Real Value Isn't Face Recognition
DeepSeek recently made its "Image Recognition Mode" — previously available only to a small group of users — officially accessible to everyone. Many bloggers rushed to test it, but most focused on facial recognition, which naturally yielded disappointing results. Bilibili creator Xiaoyou demonstrated through a series of practical cases that the real value of DeepSeek's image recognition mode lies not in identifying faces, but in generating UI prototype code from screenshots.
Facial Recognition Is Not Its Strength
Many reviewers took the same approach: feed DeepSeek a photo of a person and see if it could identify them correctly. The results showed that even for public figures easily recognized by other models (such as Liang Wenfeng himself), DeepSeek's image recognition mode returned incorrect answers.
This is hardly surprising. Current mainstream multimodal large models (such as GPT-4o, Claude, Gemini, etc.) have all proactively restricted facial recognition capabilities, due to considerations around privacy protection, portrait rights, and potential misuse risks. The EU's AI Act has explicitly classified real-time remote biometric identification as a high-risk application, and China's Personal Information Protection Law also imposes strict compliance requirements on the processing of facial information. Therefore, DeepSeek's decision to downplay facial recognition in its image recognition mode is both a necessary compliance measure and a strategic choice to focus limited model capabilities on scenarios with greater productivity value.
DeepSeek's image recognition feature was never designed for portrait identification. It focuses more on understanding the structure and styling of UI screenshots and generating corresponding front-end code. Only with this understanding can we properly evaluate its capabilities and limitations.
UI Replication Tests: From Simple to Complex
Ant Design Website Replication
The first test case involved feeding a screenshot of the Ant Design website to DeepSeek and asking it to replicate the interface.
Ant Design (commonly known as antd) is an enterprise-level UI design language and React component library open-sourced by Ant Group. It's one of the most widely used front-end component libraries in China and globally, with over 90,000 GitHub stars. Choosing it as a test subject is highly representative: its page structure is standardized, its design language is consistent, and its component styles are well-known in the front-end community — making it ideal for evaluating the accuracy of AI-generated code.
The results were impressive: DeepSeek correctly identified it as the Ant Design website and generated corresponding static page code. Button styles and overall aesthetics closely matched the original. While the navigation area in the upper left corner was missing icon graphics, the overall layout accuracy was remarkably high. The fact that DeepSeek recognized it as the Ant Design website suggests the model learned visual features of major front-end frameworks and design systems during training.
Baidu Homepage and Bilibili Homepage
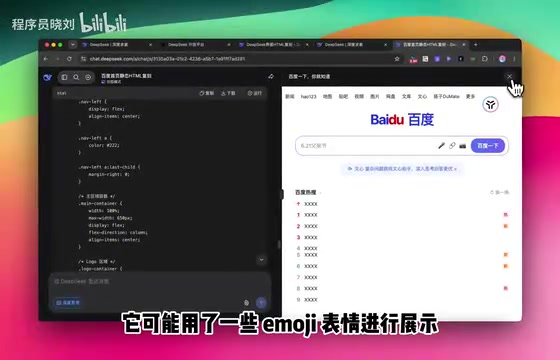
Next came homepage replications of two iconic Chinese products. The Baidu homepage reproduction turned out well — DeepSeek even cleverly used emoji to substitute for certain icon elements. While not perfectly precise, the approach was quite ingenious.
The Bilibili homepage replication was equally satisfying. Although the generated page lacked click interactions, the static layout accuracy was already quite impressive. This demonstrates that DeepSeek's image recognition mode can accurately extract layout structure, color schemes, and element hierarchy from pages.
iPhone Website: Tackling High-Design Pages
Apple's website is renowned for its minimalist yet refined design, presenting a tougher challenge for AI screenshot-to-code capabilities.
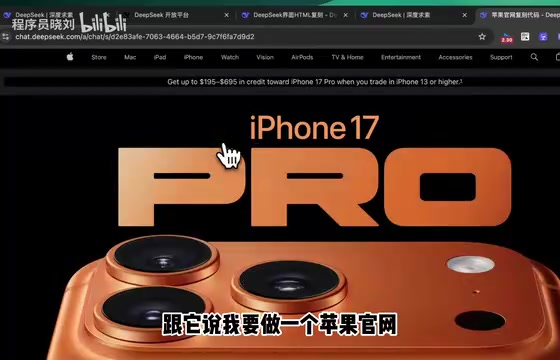
Test results showed that DeepSeek not only identified the "iPhone 17 Pro" product title but also attempted to draw product outlines using SVG and replicate the page structure with div layouts. SVG (Scalable Vector Graphics) is an XML-based vector image format that can be embedded directly in HTML code. In screenshot-to-code scenarios, SVG plays a crucial "image substitute" role: when the model can't access original image assets, it can use SVG paths to draw simplified graphic outlines as placeholders. This is more informative than blank placeholders because SVG preserves the basic shape and proportions of objects. However, SVGs generated by most models currently remain at a rough sketch level.
While it couldn't perfectly reproduce Apple's pixel-perfect visual effects (the original relies heavily on high-quality product photography), from a front-end development perspective, the generated code framework already offers considerable reference value.
DeepSeek Replicating Its Own Interface
Perhaps the most interesting test was having DeepSeek replicate its own interface. The creator captured a DeepSeek interface with three tab switches and asked it to reproduce it.
The results were again satisfying — the tab switch layout, overall color scheme, and element arrangement were all well reproduced. This "self-replication" test also indirectly demonstrates the image recognition mode's general capability in understanding UI components.
Core Value: Rapid UI Prototype Generation
Through the cases above, we can identify three core application scenarios for DeepSeek's image recognition mode:
Screenshot-to-Code
This is currently the most practical scenario. Screenshot-to-Code has been one of the hottest directions in AI front-end development over the past two years. Its core principle leverages multimodal large models (Vision-Language Models) to simultaneously understand visual information from images and semantic structure of code, mapping visual elements like layout, color, fonts, and spacing from UI screenshots into corresponding HTML/CSS code. Before DeepSeek, several open-source and commercial projects had already explored this direction, such as the open-source project screenshot-to-code (based on GPT-4V) and Google's WebSight dataset training approach.
Whether for competitive analysis, design reference, or rapid prototyping, a single screenshot can yield a front-end code framework with roughly 80% accuracy, dramatically shortening the design-to-development conversion time.
Style Extraction
DeepSeek can analyze color schemes, font hierarchies, spacing ratios, and other design elements from screenshots, reflecting them in the generated code. This is extremely valuable for developers who need to quickly understand and reuse a particular design style.
Low-Barrier UI Prototyping
For product managers or designers unfamiliar with front-end development, simply capturing a screenshot of a reference interface can produce a runnable HTML prototype for internal communication and concept validation.
The traditional front-end development workflow typically goes: designers complete mockups in Figma/Sketch → developers manually translate mockups into HTML/CSS code → iterative pixel-level adjustments against the design. This "Design-to-Code" process often accounts for 30%-50% of front-end development workload and frequently suffers from insufficient design fidelity. DeepSeek's image recognition mode offers a new shortcut for this workflow: even without Figma source files, a single screenshot can generate a code framework with 80% accuracy, and developers only need to fine-tune and add interactions on top of it. This puts it in direct competition with AI front-end generation tools like Vercel's v0.dev and Bolt.new, but DeepSeek's advantage is that it's a built-in capability of a general-purpose conversational model — no extra payment or tool switching required.
Limitations and Outlook
Of course, DeepSeek's image recognition mode currently has some notable limitations:
- Cannot handle interaction logic: It generates static pages; click events, animations, and other interactions must be added manually
- Cannot reproduce image assets: Product photos, background images, etc. can only be replaced with placeholders or SVG sketches
- Limited precision for complex components: Accuracy decreases for highly customized UI components
- Weak at recognizing people and objects: Not suitable for general image recognition tasks
However, for a "first version of a full public release," this capability already demonstrates considerable practicality. As the model continues to iterate, there's good reason to expect further improvements in interaction reproduction, component recognition accuracy, and more.
Conclusion
DeepSeek's image recognition mode is not a general-purpose "describe what you see" tool — it's a screenshot-to-code powerhouse built for developers and designers. If you're still using it to test facial recognition, you'll certainly be disappointed. But if you apply it to UI prototype generation, its 80% accuracy is more than enough to make it an efficient assistant in your daily workflow. When used in the right scenario, DeepSeek's image recognition feature truly delivers.
Related articles
Elastic Acquires Deductive AI for $85M, Accelerating the AI-Powered Debugging Market
Elastic acquires AI debugging startup Deductive AI for up to $85M, boosting its observability and security platform. Analysis of the deal's strategy, competitive landscape, and industry impact.
Baseten Raises $1.5 Billion: Why AI Inference Infrastructure Has Become a Capital Darling
AI inference startup Baseten is raising $1.5B at a $130B valuation. We analyze why inference infrastructure is booming, the competitive landscape, and what this mega-round signals.
Did ASML's Most Advanced EUV Lithography Machines Reach China? The Full Story Behind the US-Netherlands Dispute
The US claims ASML's most advanced EUV lithography machines may have reached China; ASML firmly denies it. A deep dive into the commercial logic, export control gray areas, and semiconductor geopolitics.