DeepSeek V4 Pro In-Depth Review: Performance Rivaling GPT-5.5 at 1/12 the Cost
DeepSeek V4 Pro delivers GPT-5.5-level performance at just 1/12 the cost.
DeepSeek V4 Pro matches top closed-source models like GPT 5.5 and Claude Opus 4.7 across coding, reasoning, and Agent benchmarks — while costing roughly 1/12 the price. This in-depth review covers benchmark results on SweetBench Pro, GPQA Diamond, and Agent tests, analyzes its MoE architecture advantages, and includes a hands-on coding demo using Pi Agent.
Introduction
DeepSeek released two new models last Friday — DeepSeek V4 Pro and DeepSeek V4 Flash. As the Chinese AI company that sparked the open-source LLM revolution with its R1 model, DeepSeek has once again proven that open-source models can not only match or even surpass closed-source models in performance, but do so at a fraction of the cost.
The competition between open-source and closed-source LLMs is one of the most important narratives in the AI industry today. Closed-source models (such as OpenAI's GPT series and Anthropic's Claude series) are typically developed by well-funded companies that keep model weights proprietary — users can only access them through paid API calls. Open-source models (such as DeepSeek and Meta's Llama series) publish their model weights, allowing developers to freely download, deploy, and fine-tune them. The core advantages of open-source models are clear: enterprises can deploy them on their own servers to ensure data privacy, fine-tune them for specific needs, and avoid being locked into a single vendor's pricing and terms of service. DeepSeek's rise is particularly significant — it has proven that a Chinese team can train world-class open-source models at relatively low cost, shattering the industry assumption that "only Silicon Valley giants can train top-tier models."
This article provides a comprehensive analysis of DeepSeek V4 Pro's real-world performance across three dimensions: benchmark results, pricing comparisons, and hands-on usage.
DeepSeek V4 Pro Benchmarks: Going Head-to-Head with Top Closed-Source Models
DeepSeek V4 Pro continues to use the Mixture of Experts (MoE) architecture — the model has a massive total parameter count, but only activates a subset of parameters for each request, achieving high performance while dramatically improving inference speed.
The MoE architecture is one of the most important architectural innovations in the LLM space today. Traditional dense models activate all parameters during every inference pass, meaning computational cost scales linearly with parameter count. The MoE architecture introduces a "Gating Network" that selectively activates only a subset of "expert" sub-networks during each forward pass. For example, a 600-billion-parameter MoE model might only activate 37 billion parameters per inference. This means the model can have enormous knowledge capacity (determined by total parameters) while maintaining low computational cost (determined by activated parameters). Since V2, DeepSeek has deeply optimized its MoE architecture, including its proprietary DeepSeekMoE fine-grained expert allocation strategy and Multi-head Latent Attention (MLA) mechanism. The latter dramatically reduces VRAM usage during inference by compressing the KV cache — this is the technical foundation that enables DeepSeek to offer high-performance inference at extremely low cost.
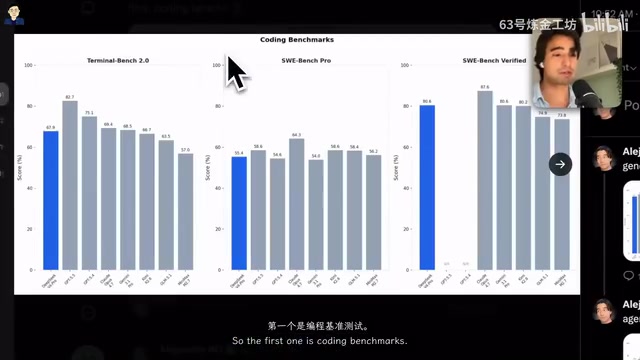
Coding Ability: SweetBench Pro Score Surpasses GPT 5.4
In the coding domain, DeepSeek V4 Pro delivers impressive results:
- Terminal Bench (terminal operation capability): On par with Claude Opus 4.7 and Gemini 3.1 Pro, slightly above open-source models like Kimi K2.6, GLM 5.1, and Minimax M2.7
- SweetBench Pro (GitHub Issue resolution capability): Score even surpasses GPT 5.4, only slightly below GPT 5.5 and Claude Opus 4.7
SweetBench Pro (also commonly written as SWE-bench) is a coding benchmark developed by a Princeton University research team. It extracts real Issues and corresponding Pull Requests from actual GitHub open-source projects, requiring AI models to understand the problem description, independently locate relevant code files, comprehend the code context, and generate correct patches to resolve the issue. Unlike traditional coding benchmarks (such as HumanEval and MBPP) that only test single-function generation, SweetBench Pro requires cross-file reasoning, understanding of project architecture, and handling of dependencies — real software engineering skills. This is why it's considered one of the most valuable benchmarks for measuring AI coding capability. DeepSeek V4 Pro's strong performance on this test demonstrates that it's already capable of handling real-world engineering problems.
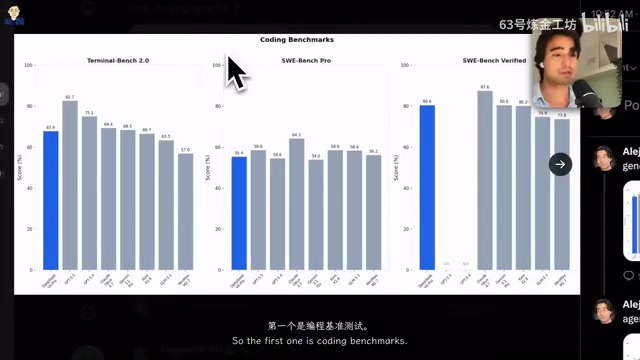
General Reasoning: GPQA and Humanity's Last Exam Performance
In non-coding reasoning tests:
- GPQA Diamond and MMLU Pro: DeepSeek V4 Pro falls only slightly below top closed-source models, roughly on par with Kimi K2.6
- Humanity's Last Exam: An extremely challenging benchmark with questions created by top experts across various fields, covering classics, ecology, mathematics, computer science, linguistics, chemistry, and more. DeepSeek V4 Pro scored 37.7, slightly above Kimi but below other SOTA models
GPQA (Graduate-Level Google-Proof Questions and Answers) is a graduate-level reasoning benchmark developed by NYU and other institutions. The Diamond subset contains the most rigorously filtered questions — each one requires domain experts to spend significant time answering, and non-experts struggle to find answers even with search engines. GPQA Diamond covers deep reasoning problems in physics, chemistry, biology, and other natural sciences, making it a key indicator of a model's reasoning depth in specialized academic domains. MMLU Pro is an upgraded version of the classic MMLU benchmark, featuring more complex multi-step reasoning problems and fewer simple multiple-choice questions that can be answered by guessing.
One notable detail: Humanity's Last Exam is far more difficult than other benchmarks — most models score around 90/100 on other tests but perform significantly worse here, making the gaps between models much more meaningful.
Agent Capabilities: Tool Use and Multi-Step Task Execution
AI Agents are one of the core development directions for LLM applications today. Unlike traditional Q&A interactions, Agents can autonomously plan task steps, call external tools (such as search engines, code executors, API endpoints, etc.), dynamically adjust strategies based on intermediate results, and ultimately complete complex multi-step tasks. On Agent benchmarks measuring this critical capability, DeepSeek V4 Pro performs particularly well:
- MCP Atlas and Toolethlon: Scores surpass GPT 5.4, Gemini 3.1 Pro, and Kimi K2.6, second only to GPT 5.5 and Claude Opus 4.7
- BrowseComp (multi-website information retrieval): Approaches GPT 5.5 and Gemini 3.1 Pro levels, even surpassing Claude Opus 4.7
It's worth explaining that MCP (Model Context Protocol) is a protocol proposed by Anthropic to standardize interactions between AI models and external tools and data sources — think of it as the "USB-C port" of the AI world. BrowseComp tests a model's ability to retrieve and synthesize information across multiple websites, simulating real research and investigation scenarios. These Agent benchmarks are important because they directly reflect a model's ability to autonomously complete complex tasks in real production environments — which is the application scenario enterprises care about most.
Overall, DeepSeek V4 Pro outperforms GPT 5.4 in most scenarios and falls just slightly below GPT 5.5 — and GPT 5.4 is already an excellent model in its own right.
DeepSeek V4 Pro Pricing: The Ultimate Value Proposition of Open-Source Models
Performance that rivals top closed-source models, but at a dramatically different price point:
| Model | Input Price (per million tokens) | Output Price (per million tokens) |
|---|---|---|
| DeepSeek V4 Pro | $1.74 | $3.48 |
| GPT 5.5 | ~$20+ | ~$40+ |
| Claude Opus 4.7 | ~$15+ | ~$75+ |
DeepSeek V4 Pro costs roughly 1/12 of GPT 5.5, and an even smaller fraction of Claude Opus 4.7. Even more exciting, DeepSeek is currently running a 75% discount promotion (through May 5th), bringing usage costs down to almost unbelievable levels.
This extreme cost-effectiveness is built on DeepSeek's deep engineering optimizations. The MoE architecture itself dramatically reduces computation per inference, and combined with MLA's efficient VRAM utilization, FP8 mixed-precision training, and other techniques, DeepSeek can serve far more concurrent requests on the same hardware — passing the cost savings directly to end users.
For developers and enterprises making frequent API calls, this translates to savings of thousands or even tens of thousands of dollars per month in inference costs.
Hands-On Demo: Using DeepSeek V4 Pro with Pi Agent
Introduction to Pi Agent
Pi is a minimalist Agent framework — think of it as a streamlined version of OpenCode. It's not just a coding assistant but also an SDK that can add Agent capabilities to applications.
Installation is dead simple — just a single command. Pi's design philosophy is to ship with minimal out-of-the-box features, but you can have Pi implement new features for itself — which is in itself an elegant demonstration of AI coding capability. This "bootstrapping" design philosophy is increasingly common in developer tools, reducing the tool's own maintenance complexity while offering users extremely high customizability.
How to Configure the DeepSeek V4 Pro API
There are two ways to connect to DeepSeek V4 Pro:
- Official API: Visit deepseek.com, create an account, add funds, and obtain an API key
- HuggingFace Inference Providers: Call the model indirectly through HuggingFace's inference providers
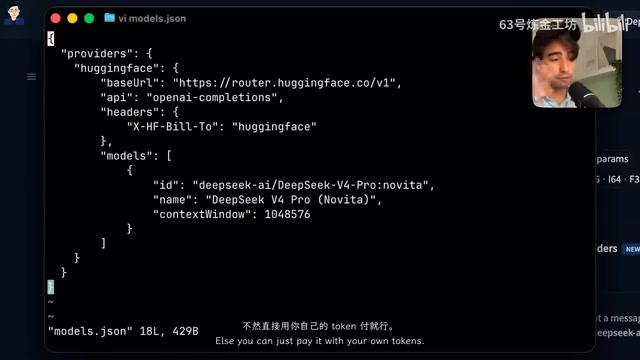
By editing Pi's models.json configuration file and adding the HuggingFace provider information and model ID, you can use DeepSeek V4 Pro within Pi. The model supports a million-token context window, which is extremely beneficial for working with large codebases.
A million-token context window means the model can read and understand approximately 750,000 English words or hundreds of thousands of lines of code in a single pass. For software development, this means developers can feed an entire medium-to-large project's codebase into the model at once, allowing it to generate code, fix bugs, or refactor architecture with full understanding of the project. By comparison, early GPT-3.5 only supported a 4K token context window — even moderately large files had to be split into segments, severely limiting practical use cases. Million-level context windows have been made possible by recent technical breakthroughs in positional encoding (such as RoPE extrapolation techniques) and attention mechanism optimization (such as sparse attention and sliding window attention).
Real-World Coding Test Results
In our hands-on test, we asked DeepSeek V4 Pro to build a browser-based code playground (similar to CodeSandbox) with HTML, CSS, and JavaScript editors plus live preview functionality, with auto-save support.
The entire build process took only about 5 minutes, and the resulting application was fully functional: responsive editor updates, working live preview, and a functional reset feature. While this was just a simple demo, combined with the benchmark data above, it clearly demonstrates DeepSeek V4 Pro's viability in real development scenarios.
Conclusion: Is DeepSeek V4 Pro Worth Switching To?
The release of DeepSeek V4 Pro reinforces a clear trend: open-source models are catching up to closed-source models at an astonishing pace — not only matching them in quality, but at a fraction of the cost.
For developers and enterprises currently using GPT 5.5 or Claude Opus 4.7 via API, switching to DeepSeek V4 Pro is worth serious consideration — you can get over 90% of the performance while paying less than 10% of the price. Of course, there are practical factors to consider before making the switch: data privacy policies (whether data passes through Chinese servers), API service stability and availability, and whether actual performance on your specific tasks meets expectations. We recommend running thorough A/B tests on your core use cases before committing to a full migration.
If you're looking for an AI model solution that balances performance and cost, DeepSeek V4 Pro is undoubtedly one of the most competitive options available today.
Key Takeaways
Related articles
Loop Engineering from Beginner to Expert: A Complete Guide to Agent Loop Development
A deep dive into Loop Engineering covering Agent Loop workflows, code implementation (While loops and Graph patterns), and how it differs from Prompt Engineering.
Coze Workflow Development Tutorial: A Complete Guide to Building AI Apps with Zero Code
Complete guide to Coze workflow development covering Agent building, node orchestration, plugin systems, API integration, and a Coze vs Dify comparison.
Building Tetris with Zero Coding Using Trae: A Complete AI Programming Walkthrough
A complete walkthrough of building Tetris from scratch using Trae AI IDE with zero coding, covering 4 rounds of iterative AI dialogue, bug fixes, and practical tips for AI-assisted programming.