Enterprise RAG Implementation: Architecture Principles and Production-Grade Optimization Guide

Enterprise RAG architecture, deployment challenges, and production-grade optimization strategies explained
This article systematically covers how RAG (Retrieval-Augmented Generation) combines enterprise private data with LLMs for precise question answering. It details the complete pipeline across data indexing (extraction, chunking, vectorization, vector database storage) and query retrieval phases, analyzes three core enterprise deployment challenges—index optimization, retrieval quality, and generation quality control—and introduces frontier optimization directions including hybrid retrieval and GraphRAG.
Why Do Enterprises Need RAG?
More and more enterprises are looking to combine large language models with their own business data to reduce costs and improve efficiency. However, using general-purpose LLMs directly often fails to meet the precise demands for domain-specific knowledge—the model doesn't know your product manuals, internal policies, or industry know-how.
RAG (Retrieval-Augmented Generation) is the core technical solution to this pain point: it enables LLMs to first retrieve relevant content from an enterprise's private knowledge base before generating precise answers based on that content.
RAG was originally proposed by Meta AI's research team in 2020 in the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, designed to address the problems of outdated knowledge and hallucinations in open-domain question answering. With the commercial adoption of LLMs like GPT-4 and Claude, RAG has rapidly transitioned from academic research to enterprise implementation, becoming one of the most mature engineering approaches in LLM application development today.
This article draws on hands-on experience from frontline LLM commercialization projects to systematically outline the complete RAG architecture and explore the common technical challenges and optimization strategies encountered during enterprise-grade deployment.
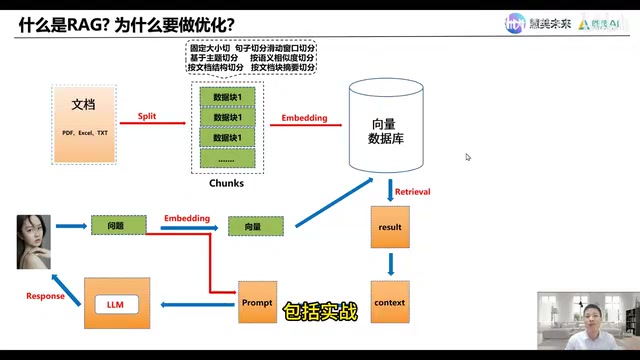
RAG Core Architecture: The Complete Data Indexing and Query Retrieval Pipeline
The core idea of RAG can be summarized in one sentence: Bridge enterprise private data with LLM capabilities, enabling the model to generate precise answers based on the enterprise's proprietary knowledge base.
The entire pipeline is divided into two major phases: the Data Indexing Phase and the Query Retrieval Phase.
Data Indexing Phase: Building the Enterprise Knowledge Base
The goal of this phase is to process enterprise business data and store it in a vector database, preparing it for subsequent retrieval.
Step 1: Data Extraction. Enterprise business data comes in diverse formats—text documents, images, audio, spreadsheets, PDFs, Word documents, and even technical documents containing complex formulas. Traditional relational databases like MySQL struggle to efficiently handle this unstructured data, so specialized techniques are needed for accurate extraction.
Step 2: Document Chunking. The extracted data is typically massive, making direct processing inefficient. Documents need to be split into reasonably sized chunks using strategies such as paragraph-based, semantic-based, or fixed-length splitting. The choice of chunking strategy directly impacts retrieval quality downstream, making it one of the key optimization points.
Common chunking strategies include: Fixed-length chunking (splitting by character count or token count—simple to implement but may truncate semantics), Recursive chunking (prioritizing natural boundaries like paragraphs and sentences while maintaining semantic completeness), and Semantic chunking (using Embedding models to detect semantic boundaries—highest quality but computationally expensive). In practice, a certain percentage of sliding window overlap is typically configured to prevent critical information from being cut off at chunk boundaries.
Step 3: Vectorization (Embedding). This is the most critical step in the entire pipeline. LLMs fundamentally understand mathematical semantic representations, not raw text. Just as communication between a Chinese speaker and an English speaker requires translation, we need Embedding models to convert text chunks into high-dimensional vector representations that LLMs can understand.
Embedding models map text into a high-dimensional semantic space (typically 768 to 4096 dimensions), where semantically similar texts are closer together in vector space—this is the mathematical foundation for subsequent similarity retrieval. Popular models include OpenAI's text-embedding-3 series, and open-source options like BGE (from Beijing Academy of Artificial Intelligence) and E5. Notably, for Chinese-language scenarios, Embedding models specifically trained on Chinese corpora should be selected to ensure accurate semantic representation and retrieval quality. Additionally, the indexing phase and query phase must use the same Embedding model; otherwise, inconsistent vector spaces will cause retrieval to fail completely.
Step 4: Storage in Vector Database. The generated vectors and their corresponding original text are stored in a vector database (such as Milvus, Pinecone, Weaviate, etc.). At this point, the enterprise's private knowledge base is fully constructed.
Vector databases are database systems specifically designed for high-dimensional vector storage and similarity retrieval. Their core algorithms include HNSW (Hierarchical Navigable Small World) and IVF (Inverted File Index) approximate nearest neighbor (ANN) search algorithms, capable of performing similarity matching across billions of vectors in milliseconds. Compared to traditional relational databases, vector databases natively support the "semantic similarity" fuzzy query paradigm, making them indispensable core infrastructure in RAG architecture.
Query Retrieval Phase: From User Question to Intelligent Answer
Once the knowledge base is built, users can obtain precise answers through natural language queries. The process involves five steps:
- User inputs a question: The user asks a business-related question in natural language
- Question vectorization: The user's question is converted into a vector using the same Embedding model
- Similarity retrieval: Similarity matching is performed in the vector database to find the most relevant document chunks
- Context augmentation: The retrieved relevant documents are sent to the LLM as context along with the user's question
- Answer generation: The LLM generates a precise answer based on the retrieved enterprise-specific knowledge
The key here is that the LLM no longer answers "from thin air" based solely on its training data, but generates content grounded in actual enterprise data.
Three Core Challenges in Enterprise RAG Deployment
While the above pipeline appears straightforward, real-world enterprise deployments encounter numerous thorny issues. This is precisely what distinguishes a "demo-level RAG" from a "production-grade RAG."
Challenge 1: Index Optimization—Data Quality Determines the System's Upper Bound
Index optimization is the first problem encountered in practice. Enterprise data varies widely in quality and format. How accurately and completely this data is extracted and indexed directly determines the ceiling of the entire RAG system.
Common optimization directions include:
- Intelligent chunking strategies: Selecting different chunking methods based on document type (e.g., recursive chunking, semantic chunking) to avoid truncating critical semantics
- Metadata enrichment: Attaching structured metadata tags (such as source, timestamp, category) to each document chunk to improve filtering precision during retrieval
- Multimodal processing: Employing specialized solutions like OCR and table parsing for non-text content such as images and tables, ensuring no information is lost
Challenge 2: Retrieval Quality—The Core Bottleneck of RAG Systems
The retrieval component directly determines what "reference materials" the LLM receives, making it the most impactful link in the entire RAG chain. Common issues include:
- Semantic drift: The user's phrasing doesn't match the wording in the knowledge base, causing relevant content to be missed. For example, a user asks "how to return an item" but the knowledge base contains "product return and exchange procedures"
- Balancing recall and precision: Too much recall introduces noise that confuses the LLM's judgment; too little recall may miss critical information
- Hybrid retrieval strategies: Combining the strengths of keyword retrieval (BM25) and semantic vector retrieval through weighted fusion to improve overall retrieval effectiveness
Among these, BM25 (Best Match 25) is a classic information retrieval algorithm based on term frequency statistics, introduced in 1994 and still an important benchmark in full-text search. BM25 excels at exact keyword matching and performs particularly well for professional terminology, product model numbers, contract IDs, and similar scenarios—precisely complementing the weaknesses of pure semantic vector retrieval in exact matching. Hybrid retrieval typically uses the RRF (Reciprocal Rank Fusion) algorithm to merge results from both retrieval paths with weighted scoring. In multiple real-world business scenarios, hybrid retrieval has been shown to improve recall accuracy by 15% to 30% compared to single-method retrieval.
Challenge 3: Generation Quality Control—Eliminating Hallucinations and Irrelevant Answers
Even when the correct documents are retrieved, the LLM may still produce hallucinations or irrelevant answers during generation.
The technical root cause of LLM hallucinations lies in the fact that models learn probability distributions of language patterns during training, not facts themselves. When retrieved content doesn't sufficiently match the question, or when prompts are poorly designed, the model tends to fill gaps with "plausible guesses" from its training data, generating content that sounds fluent but is actually incorrect. RAG constrains the model's generation boundaries by providing explicit context, making it one of the most effective engineering approaches for hallucination suppression—but this effectiveness is highly dependent on retrieval quality, and the "garbage in, garbage out" principle applies equally here.
Common quality control measures include:
- Prompt engineering optimization: Using carefully designed prompts to constrain the LLM's answer scope and format
- Answer verification mechanisms: Performing factual validation on generated results to ensure answers are consistent with retrieved content
- Citation tracing: Annotating information sources in answers for user verification while enhancing credibility
RAG Industry Applications and Suitability Criteria
RAG technology has extremely broad applicability, suitable for virtually any industry with established business data:
| Industry | Typical Application Scenarios |
|---|---|
| Finance | Compliance Q&A, research report analysis, intelligent customer service |
| Insurance | Policy interpretation, claims guidance, product recommendations |
| Manufacturing | Equipment maintenance manual lookup, quality standard retrieval |
| Logistics | Shipping rule queries, exception handling guidance |
| Healthcare | Clinical guideline retrieval, drug information queries |
The key criterion for determining whether your business is suitable for RAG: As long as your enterprise has established, repetitive business data, you can combine it with LLMs through a RAG solution to achieve intelligent upgrades.
Summary: RAG Implementation Path and Practical Recommendations
RAG is one of the most mature and practical technical approaches for enterprise-grade LLM deployment today. Understanding its core architecture is just the first step—the real value lies in deeply understanding the optimization potential at each stage and performing targeted tuning based on specific business scenarios.
For technical professionals looking to enter LLM application development, the following progressive path is recommended:
- Understand the basic architecture: Start by running the simplest RAG demo to build intuitive understanding of the full pipeline
- Deep-dive into optimization: Tackle the optimization challenges of indexing, retrieval, and generation one by one
- Align with business scenarios: Connect technical solutions with specific industry requirements to solve real business problems
- Follow cutting-edge developments: Continuously track emerging directions such as RAG combined with Agents, GraphRAG, and other innovations
On the frontier, GraphRAG (proposed by Microsoft Research in 2024) combines knowledge graphs with RAG, enhancing multi-hop reasoning capabilities through entity relationship networks. It's particularly suited for complex business scenarios requiring cross-document correlation analysis, such as queries like "find all product lines that have partnerships with Supplier A and have had quality complaints in the past three years"—queries that require multi-step relational reasoning. Meanwhile, the combination of RAG and Agents gives systems the ability to actively plan retrieval strategies, dynamically determining the number of retrieval iterations and strategies based on question complexity. This represents an important evolution of RAG technology from "passive retrieval" to "active reasoning."
Enterprise-grade LLM deployment is not something that happens overnight, but RAG undoubtedly provides us with a clear and viable implementation path. From architectural understanding to production optimization, every step of deeper engagement delivers tangible business value improvements.
Key Takeaways
- RAG (Retrieval-Augmented Generation) is the core technical solution for combining enterprise private data with LLMs, applicable to virtually all industries with established business data including finance, insurance, and manufacturing
- The complete RAG pipeline includes six critical steps: data extraction, document chunking, vectorization (Embedding), vector database storage, similarity retrieval, and LLM answer generation
- Enterprise RAG deployment faces three core challenges: index optimization (data extraction and chunking strategies), retrieval quality optimization (semantic drift and hybrid retrieval), and generation quality control (hallucination suppression and answer verification)
- Vector databases are the core infrastructure of RAG architecture, using ANN algorithms like HNSW and IVF to perform semantic similarity retrieval across billions of vectors in milliseconds, replacing traditional relational databases for unstructured data processing
- Hybrid retrieval (BM25 keyword search + semantic vector search) combined with RRF reranking is a critical engineering practice for improving retrieval quality, demonstrating significant recall accuracy improvements in real-world scenarios
- The key to moving from demo to production-grade RAG lies in fine-grained optimization at every stage, requiring targeted tuning for specific business scenarios; GraphRAG and Agent integration represent important frontier directions in RAG technology evolution
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.