Enterprise RAG Project in Practice: A Complete Guide from Principles to Deployment

Complete knowledge framework for enterprise RAG from principles to deployment
This article systematically covers enterprise RAG (Retrieval-Augmented Generation) technology. RAG retrieves from external knowledge bases before LLM generation, solving hallucination, timeliness, and domain expertise challenges. It covers RAG architecture evolution (Naive→Advanced→Modular), LangChain's six core modules, full enterprise development workflow (text splitting, retrieval optimization, evaluation, deployment), and frontier directions like GraphRAG and multimodal RAG.
Introduction: Why RAG Is the Most Valuable AI Technology to Learn Right Now
In the wave of large model applications going into production, RAG (Retrieval-Augmented Generation) has become the core technical approach for enterprise AI applications. It solves the LLM "hallucination" problem, enabling AI to provide accurate answers based on private knowledge bases. Recently, multiple content creators on Bilibili (such as "Juran," "Code Guide," and "Coder Group") have released enterprise-level RAG tutorials, reflecting the growing interest in this technology.
This article systematically organizes the complete knowledge framework for enterprise RAG projects—from principles to practice—based on multiple tutorial sources, helping readers establish a clear learning path.
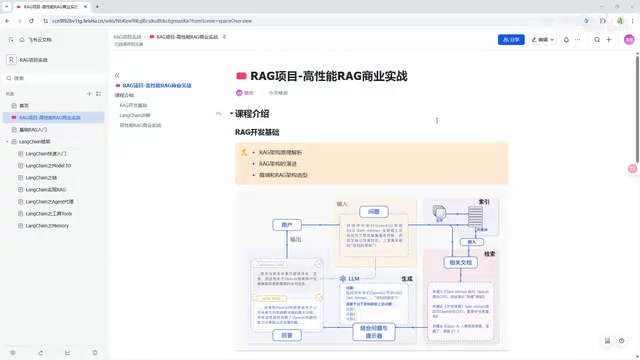
RAG Technical Principles and Architecture Evolution
What Is RAG
The core idea of RAG is simple: before the LLM generates an answer, it first retrieves relevant information from an external knowledge base, provides the retrieved content as context to the model, and then generates a more accurate, evidence-based response.
This technology addresses three core pain points of LLMs:
- Knowledge timeliness: Model training data has a cutoff date; RAG can connect to real-time updated knowledge bases
- Hallucination: Models may "fabricate" information; RAG makes answers verifiable
- Domain expertise: By connecting to enterprise private data, general-purpose models gain domain expert capabilities
To understand why RAG is so important, we need to look deeper at the nature of LLM hallucinations. Hallucination refers to models outputting factually incorrect or entirely fabricated information with high confidence. The root cause is that LLMs are fundamentally probabilistic language models—they generate text by predicting the most likely next token rather than retrieving facts from structured knowledge bases. When training data lacks sufficient information in a domain, the model still "completes" answers based on statistical patterns, producing plausible but incorrect outputs. RAG transforms the generation process from "pure memory recall" to an "open-book exam" by introducing an external retrieval step during inference, fundamentally mitigating this problem.
RAG Architecture Evolution
According to the tutorials, RAG architecture has evolved from simple to complex:
Naive RAG: The most basic "retrieve-generate" two-step process, using user queries directly for retrieval and concatenating results into the prompt.
Advanced RAG: Builds on Naive RAG with query rewriting, reranking, multi-path recall, and other optimization strategies to significantly improve retrieval quality.
Query Rewriting and Reranking are the two most critical optimization techniques in Advanced RAG. Users' original questions often suffer from vague phrasing, lack of context, or overly colloquial language, leading to poor retrieval results. Common rewriting strategies include: HyDE (Hypothetical Document Embeddings), where the LLM first generates a hypothetical answer document and uses it for retrieval; Multi-Query, which splits one question into multiple sub-questions for separate retrieval and merged results; and Step-back Prompting, which abstracts specific questions to higher-level ones for more comprehensive background information. Reranking uses Cross-Encoder models to perform fine-grained scoring and reordering of candidate documents against the query, significantly improving the quality of context sent to the LLM.
Modular RAG: Decomposes the RAG system into pluggable modules supporting flexible composition and iterative optimization, better suited for complex enterprise scenarios.
RAG vs. Fine-tuning
A common technical decision is: when to use RAG vs. fine-tuning? The tutorials provide clear guidance—RAG suits knowledge-intensive scenarios requiring frequent updates; fine-tuning suits scenarios requiring changes to model behavior patterns and style adaptation. In practice, the two are often combined.
Technical Implementation with LangChain
LangChain's Six Core Modules
The tutorial projects are built on LangChain, currently the most popular framework for LLM application development. Open-sourced by Harrison Chase in October 2022, LangChain rapidly became the most influential framework in this space. Its core value lies in providing a standardized abstraction layer that encapsulates LLM calls, prompt management, external tool integration, and memory management into unified interfaces, greatly lowering the development barrier. Competing and complementary frameworks include LlamaIndex (focused on data indexing and retrieval), Semantic Kernel (from Microsoft, deeply integrated with Azure), and Haystack (by deepset, focused on search and QA). In 2023, LangChain launched LangSmith (for debugging and monitoring) and LangServe (for rapid API deployment), further completing the development-to-production toolchain.
Its core modules include:
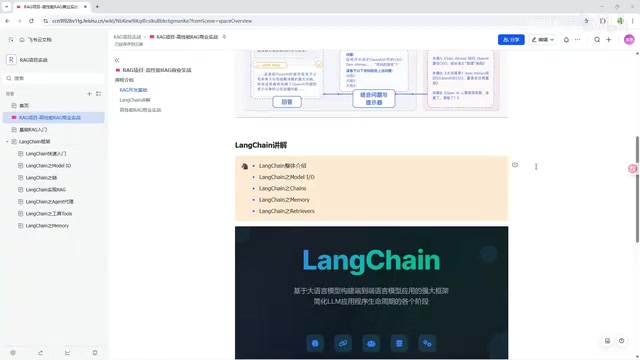
- Model I/O: Handles interaction with LLMs, including prompt template management, model invocation, and output parsing
- Chain: Links multiple processing steps into chain calls for complex business logic
- Memory: Manages conversation history and context for multi-turn dialogue scenarios
- Retrieval: Core retrieval module covering document loading, text splitting, vectorization, and retrieval strategies
- Agent: Enables models to use tools and make autonomous decisions
- Callbacks: Callback mechanisms for logging, monitoring, and debugging
According to Bilibili creators "Code Guide" and "Coder Group," the combination of Agent and RAG (i.e., RAG + knowledge base + Embeddings agent architecture) is the mainstream enterprise architecture, aligning closely with LangChain's design philosophy.
Enterprise Commercial Practice: Complete Development Workflow
Requirements Analysis and Architecture Design
A complete enterprise RAG project goes far beyond getting a demo working. The tutorials cover the full workflow from requirements to launch:
- Requirements analysis: Define business scenarios, user groups, and performance requirements
- Architecture design: Determine overall system architecture including data flow, service decomposition, and API design
- Technology selection: Choose appropriate LLMs, vector databases, embedding models, and other tech stack components
Data Processing and Retrieval Optimization
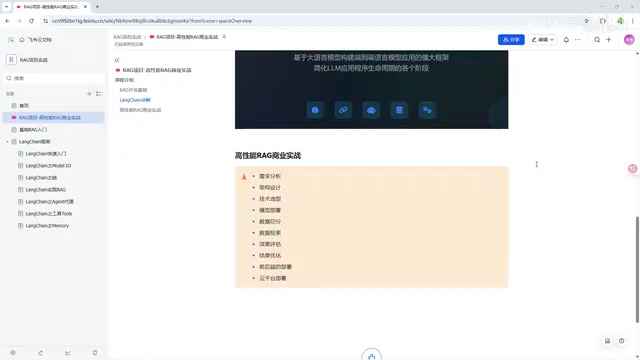
Data-related work often accounts for over 60% of project effort:
Model deployment: Select and deploy LLMs and embedding models suited to business scenarios, balancing cost, latency, and performance.
Understanding embedding model fundamentals is essential. Embedding is the foundational technology of RAG systems—it maps text (words, sentences, or paragraphs) into dense vectors in high-dimensional space, so semantically similar texts are closer in vector space. Common embedding models include OpenAI's text-embedding-ada-002, the open-source BGE series, and M3E (optimized for Chinese). Vector retrieval uses Approximate Nearest Neighbor (ANN) algorithms to quickly find the most similar vectors among massive datasets. Mainstream vector databases like Milvus, Pinecone, Weaviate, and Chroma typically use HNSW (Hierarchical Navigable Small World) or IVF (Inverted File Index) indexing structures, balancing retrieval accuracy and speed.
Text splitting: This is a critical factor in RAG system performance. Chunks that are too large introduce noise; too small and they lose context. Different splitting strategies are needed for different document types (PDF, Word, web pages, etc.).
Text chunking may seem simple but is one of the most impactful factors on final RAG performance. Common strategies include: fixed-length splitting (by character or token count—simple but may break semantic integrity), recursive character splitting (LangChain's default, attempting paragraph, sentence, then character-level splits), semantic splitting (using embedding similarity to detect semantic boundaries), and document structure-aware splitting (leveraging Markdown headings, PDF sections, etc.). Overlap should typically be set at 10%-20% of chunk size to prevent critical information from being cut off. For tables, charts, and other non-continuous text, specialized parsing tools (such as Unstructured, LlamaParse, etc.) are often needed for preprocessing.
Retrieval: Includes vector search, keyword search, hybrid search, and post-processing techniques like reranking.
Evaluation and Continuous Optimization
Enterprise projects must establish quantitative evaluation frameworks:
- Retrieval accuracy (Recall/Precision)
- Relevance and accuracy of generated answers
- End-to-end user satisfaction
Targeted optimization based on evaluation results creates an "evaluate-optimize-re-evaluate" iterative loop.
Frontend/Backend Deployment and Cloud Launch
The final phase covers production engineering: frontend UI development, backend API services, and complete cloud platform deployment, ensuring learners can deliver a fully functional system.
Frontier Directions: GraphRAG and Multimodal RAG
As mentioned earlier, RAG technology is evolving rapidly. Two frontier directions deserve deeper discussion.
GraphRAG is a new paradigm proposed by Microsoft Research in 2024 that replaces flat document indexing with knowledge graph structures. The system first uses LLMs to extract entities and relationships from documents to build a knowledge graph, then applies community detection algorithms (such as the Leiden algorithm) for hierarchical clustering, generating community summaries at different granularities. During retrieval, the system can leverage both local search (precise queries targeting specific entities) and global search (comprehensive QA based on community summaries), excelling at complex questions requiring cross-document reasoning and global summarization.
Multimodal RAG extends retrieval from pure text to images, audio, video, and other modalities, using multimodal models like CLIP and GPT-4V for cross-modal semantic retrieval and understanding, applicable to product catalog QA, medical image analysis, and similar scenarios. These two directions represent RAG's evolution from "text retrieval augmentation" toward "structured knowledge reasoning" and "full-modal information fusion."
Learning Recommendations and Summary
Based on multiple tutorial sources, the recommended learning path for enterprise RAG development is:
- Build foundations: Understand RAG principles, embedding technology, and vector retrieval fundamentals
- Master frameworks: Become proficient with LangChain and similar frameworks, understanding each module's role and composition
- Hands-on practice: Start with simple demos, gradually increase complexity, and complete a full project
- Focus on optimization: Text splitting strategies, retrieval optimization, and prompt engineering are the three key factors determining performance
RAG technology continues to evolve rapidly, with new directions like GraphRAG and multimodal RAG constantly emerging. Mastering core principles and engineering practices enables you to quickly adapt to technological evolution and gain an edge in enterprise AI application development.
Key Takeaways
- RAG addresses three major LLM pain points: hallucination, knowledge timeliness, and domain expertise through retrieval-augmented generation
- RAG architecture has evolved from Naive RAG to Advanced RAG to Modular RAG
- Complete RAG systems are built on LangChain's six core modules: Model I/O, Chain, Memory, Retrieval, Agent, and Callbacks
- Enterprise RAG projects must cover the full workflow from requirements analysis and architecture design to text splitting, retrieval optimization, evaluation, and cloud deployment
- Text splitting and retrieval strategies are critical to RAG system performance, requiring differentiated approaches based on document types
- GraphRAG and multimodal RAG represent frontier evolution from text retrieval augmentation toward structured knowledge reasoning and full-modal information fusion
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.