Fireworks Platform Adds Nemotron 3 Ultra Post-Training Support: End-to-End Fine-Tuning and Deployment
Fireworks AI now supports post-training for NVIDIA Nemotron 3 Ultra with seamless train-to-deploy workflows.
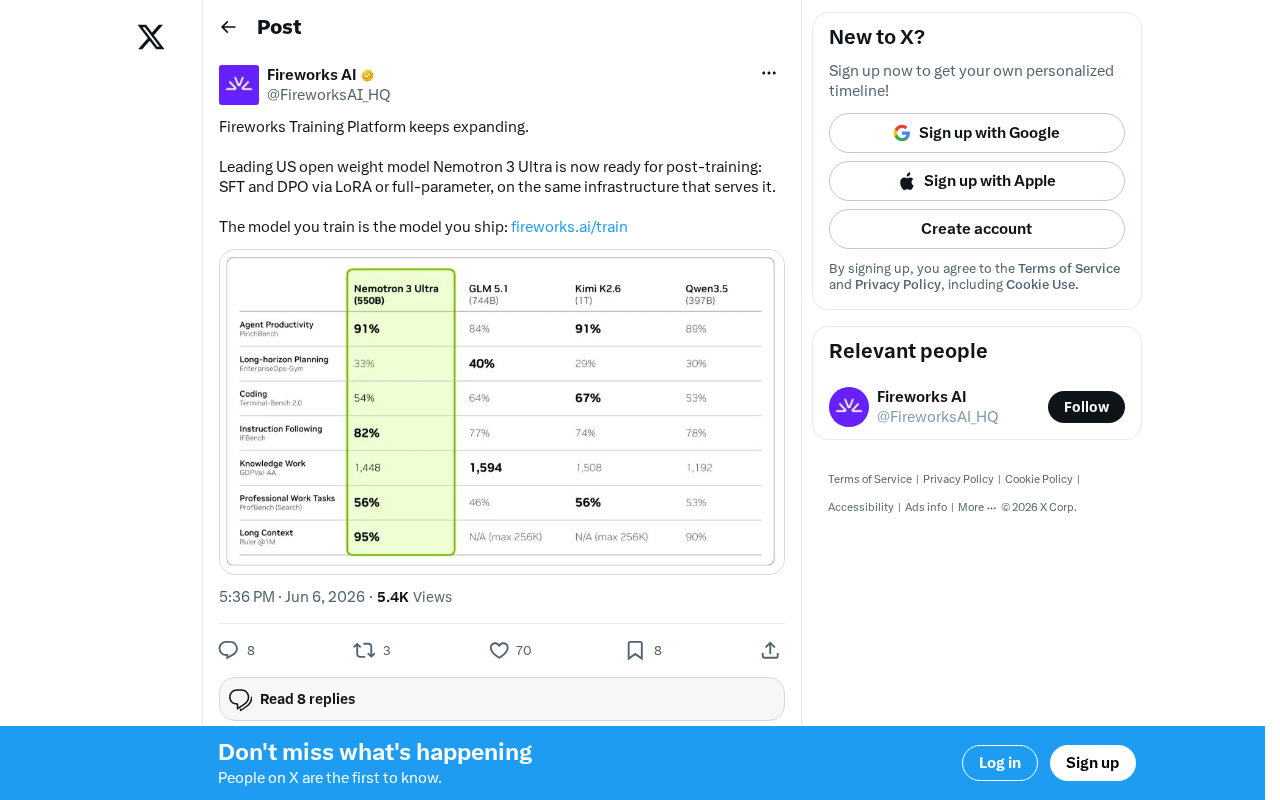
Fireworks AI has expanded its training platform to support post-training for NVIDIA's Nemotron 3 Ultra open-weight model. The platform offers SFT, DPO, LoRA, and full-parameter fine-tuning options, all unified under a "train and ship" philosophy where training and inference run on the same infrastructure. This eliminates training-serving skew and accelerates the path from experimentation to production deployment.
Fireworks Training Platform Expands: Nemotron 3 Ultra Now Supported for Post-Training
Fireworks AI recently announced that its training platform now supports post-training for NVIDIA's Nemotron 3 Ultra model. Users can complete both model fine-tuning and deployment on the same infrastructure, enabling a seamless "train and ship" workflow.
Nemotron 3 Ultra: A Leading U.S. Open-Weight Model
Nemotron 3 Ultra is an open-weight large language model from NVIDIA, described by Fireworks as "the leading U.S. open-weight model." The Nemotron series is a key product line in NVIDIA's LLM portfolio, continuing the company's tradition of naming products after astronomical and sci-fi elements. As the flagship of the series, Nemotron 3 Ultra has demonstrated capabilities on par with top closed-source models across multiple benchmarks. NVIDIA's strategic intent behind releasing open-weight models is clear — by providing high-quality foundation models, the company drives adoption of its GPU hardware and CUDA ecosystem, creating a positive flywheel: "open models attract developers → developers need GPUs for training and inference → GPU sales grow."
As an open-weight model, it allows developers to perform customized training on top of it, making post-training capabilities especially important. It's worth distinguishing between "open-weight" and "open-source": open-weight means the model's parameter weight files are publicly available — developers can download, deploy, and fine-tune them — but the training data, training code, and full technical details aren't necessarily fully disclosed. This differs from true open-source (like Linux, where code and documentation are entirely open), but for the vast majority of use cases, open weights are sufficient for customization needs.
The core value of open-weight models lies in their customizability. Enterprises and developers can optimize models for their specific business scenarios without training a large model from scratch. Nemotron 3 Ultra's open nature, combined with Fireworks' training capabilities, provides developers with a complete path from foundation model to production deployment.
Post-Training Methods Supported on the Fireworks Platform
Fireworks offers multiple post-training options for Nemotron 3 Ultra, covering a range of customization needs. Before diving into these methods, it helps to understand the full LLM development pipeline: first comes the pre-training phase, where the model learns fundamental language patterns and world knowledge from massive text datasets — this stage typically requires thousands of GPUs running for weeks or even months, costing millions or even hundreds of millions of dollars; then comes the post-training phase, where the pre-trained model is behaviorally adjusted and enhanced using relatively small but high-quality datasets. Post-training has become a critical step in deploying AI applications because, while pre-trained models possess broad knowledge, their outputs are often imprecise, misaligned with specific business needs, or may even generate unsafe content. Post-training bridges the gap between "general capability" and "specialized application."
SFT (Supervised Fine-Tuning)
Supervised Fine-Tuning (SFT) is the most common model customization method. It uses high-quality instruction-response pair data to adjust model behavior, making it better suited for specific tasks or domains. The mechanism works by showing the model numerous "input–expected output" examples and updating model parameters through backpropagation so the model learns to produce desired outputs for similar inputs. For example, a healthcare company could use thousands of medical Q&A pairs to perform SFT, making the model's medical responses more professional and accurate. SFT effectiveness is highly dependent on training data quality — a small amount of high-quality data often outperforms a large volume of low-quality data, embodying the industry principle that "data quality trumps data quantity."
DPO (Direct Preference Optimization)
DPO (Direct Preference Optimization) is an alignment technique that directly optimizes model outputs using human preference data, without the need to train a separate reward model. Compared to traditional RLHF (Reinforcement Learning from Human Feedback), DPO is more streamlined and efficient.
To appreciate DPO's value, it helps to understand the RLHF pipeline it replaces. Traditional RLHF involves three steps: first, SFT is performed; then a separate reward model is trained using human preference data; finally, reinforcement learning algorithms like PPO (Proximal Policy Optimization) are used to optimize the language model using the reward model's scores as signals. While this pipeline is effective — ChatGPT's success is largely attributed to RLHF — it's extremely complex to engineer, reward model training is unstable, and PPO hyperparameter tuning is notoriously challenging.
The DPO method, proposed by a Stanford research team in 2023, elegantly sidesteps these issues. DPO's core insight is that reward model training and reinforcement learning optimization can be merged into a single supervised learning objective. Specifically, DPO directly uses "preference pair" data (two different outputs for the same input, with annotations indicating which is better) and updates the language model parameters through a concise loss function. This not only dramatically simplifies the training pipeline but also avoids the "reward hacking" problem that reward models can introduce — where the model learns to game the reward model rather than genuinely improving output quality. For these reasons, DPO is rapidly becoming the mainstream choice for model alignment.
LoRA and Full-Parameter Training
In terms of training strategies, the platform supports both LoRA (Low-Rank Adaptation) and full-parameter fine-tuning.
LoRA's technical principle stems from a key observation: during fine-tuning of large language models, the change in parameters (i.e., the difference matrix between pre- and post-fine-tuning parameters) typically has very low "intrinsic rank." In plain terms, although a model may have billions or even hundreds of billions of parameters, fine-tuning really only requires adjustments within a low-dimensional subspace. Based on this insight, LoRA doesn't directly modify the original weight matrix W. Instead, it decomposes the parameter update into the product of two small matrices: ΔW = A × B, where A and B have dimensions far smaller than the original matrix. For example, for a 4096×4096 weight matrix, LoRA might use two 4096×16 matrices to represent the update, reducing trainable parameters from roughly 16 million to about 130,000 — a reduction of two orders of magnitude. This means fine-tuning tasks that would otherwise require multiple high-end GPUs can be completed on a single GPU, dramatically lowering training costs and barriers to entry.
Through this low-rank matrix decomposition, LoRA significantly reduces training costs, making it ideal for resource-constrained scenarios or rapid experimental iteration. Full-parameter training, on the other hand, unfreezes all model parameters for updating, providing maximum flexibility for model adjustment — suitable for applications requiring deep customization, such as teaching the model entirely new domain knowledge or significantly altering its behavior patterns. In practice, many teams first use LoRA to quickly validate feasibility, then consider full-parameter training to further boost performance once results are confirmed.
The Core Philosophy: "Train and Ship"
The most noteworthy design philosophy behind this Fireworks update is: "The model you train is the model you ship."
This means training and inference services run on the same infrastructure, eliminating compatibility issues, performance discrepancies, or additional engineering overhead that can arise when migrating models from training to production environments. In traditional model development workflows, training and deployment are often disconnected: teams complete training in one environment, then need to export the model, convert formats, and load and test it in a new environment. This process can encounter a host of issues — framework version mismatches, quantization precision loss, inference engine compatibility problems, and more. The industry collectively refers to these as "training-serving skew," which not only increases engineering costs but can also cause model performance in production to diverge from training evaluation results.
Fireworks AI, an infrastructure company focused on AI inference and model serving, was founded by core members of the former Meta (Facebook) PyTorch team and has deep technical expertise in model optimization and efficient inference. Previously known primarily for high-performance inference services offering industry-leading speed and cost efficiency, the company's integration of training capabilities into its platform marks a strategic transformation from a pure inference provider to a full-lifecycle model platform. The competitive advantage of this integrated approach is clear: users don't need to switch between different vendors, and once training is complete, models can enter inference serving with optimal configurations, dramatically shortening the cycle from experimentation to production.
For teams focused on rapid iteration, this integrated platform can significantly compress the journey from experiment to production — reducing what might have been a multi-day deployment process to just minutes.
Industry Implications for Developers and Enterprises
This development reflects several important trends in AI infrastructure:
-
Training-Inference Integration: An increasing number of platforms are offering end-to-end model lifecycle management rather than focusing solely on inference. This trend is driven by real enterprise needs — as model customization becomes the norm rather than the exception, splitting training and inference across different platforms creates enormous management complexity and efficiency losses. A similar trend occurred in the early days of cloud computing: compute, storage, and networking were initially separate services, and it was only when they were unified into integrated cloud platforms that true productivity gains were realized.
-
Maturing Open Model Ecosystem: As high-quality open-weight models proliferate, demand for post-training and customization toolchains is growing rapidly. From Meta's Llama series to Mistral to NVIDIA's Nemotron, open-weight models have reached a level of capability that can replace closed-source APIs in many real-world business scenarios. This has spawned a massive "model customization" market — estimated to reach billions of dollars in the coming years.
-
Lowering the Customization Barrier: Through platform-as-a-service offerings, even teams without large-scale GPU clusters can perform custom training on top-tier open models. The significance of this cannot be overstated: high-end AI GPUs (such as NVIDIA H100/H200) are in short supply, with individual units costing tens of thousands of dollars, and building a GPU cluster capable of training large models easily requires millions of dollars in investment. Platform services, through resource sharing and elastic scheduling, enable small and mid-sized teams to use these expensive compute resources on demand, truly democratizing AI capabilities.
For developers and enterprises evaluating LLM customization options, Fireworks' post-training support for Nemotron 3 Ultra represents a noteworthy option — especially for teams looking to rapidly build differentiated AI capabilities on top of open models. When choosing a solution, teams need to weigh multiple dimensions including model performance, training cost, deployment latency, and data privacy compliance. Fireworks' integrated approach offers a clear advantage in simplifying engineering complexity.
Related articles
Mistral Le Chat Image Generation Review: Can It Replace Fable?
Mistral AI launches image generation in Le Chat, dubbed Le Chaton Fat. We analyze its capabilities, compare it with Fable, and explore the trend of AI chat platforms integrating image generation.
Testing DeepSeek's Safety Mechanisms: Multiple Jailbreak Attempts Successfully Blocked
An overseas security blogger systematically tested DeepSeek's jailbreak resistance using direct requests, rephrased prompts, and varied strategies. Results show robust intent recognition, consistent blocking, and context-aware safety mechanisms.
A Middle Schooler with Zero Coding Skills Built a Story-Driven Game with AI: Creativity Unshackled from Technical Barriers
A middle schooler with no coding experience used AI to build an interactive story game with branching choices and surreal alien adventures. We explore what this means for creative democratization.