#Fireworks AI
5 related articles
·2 min
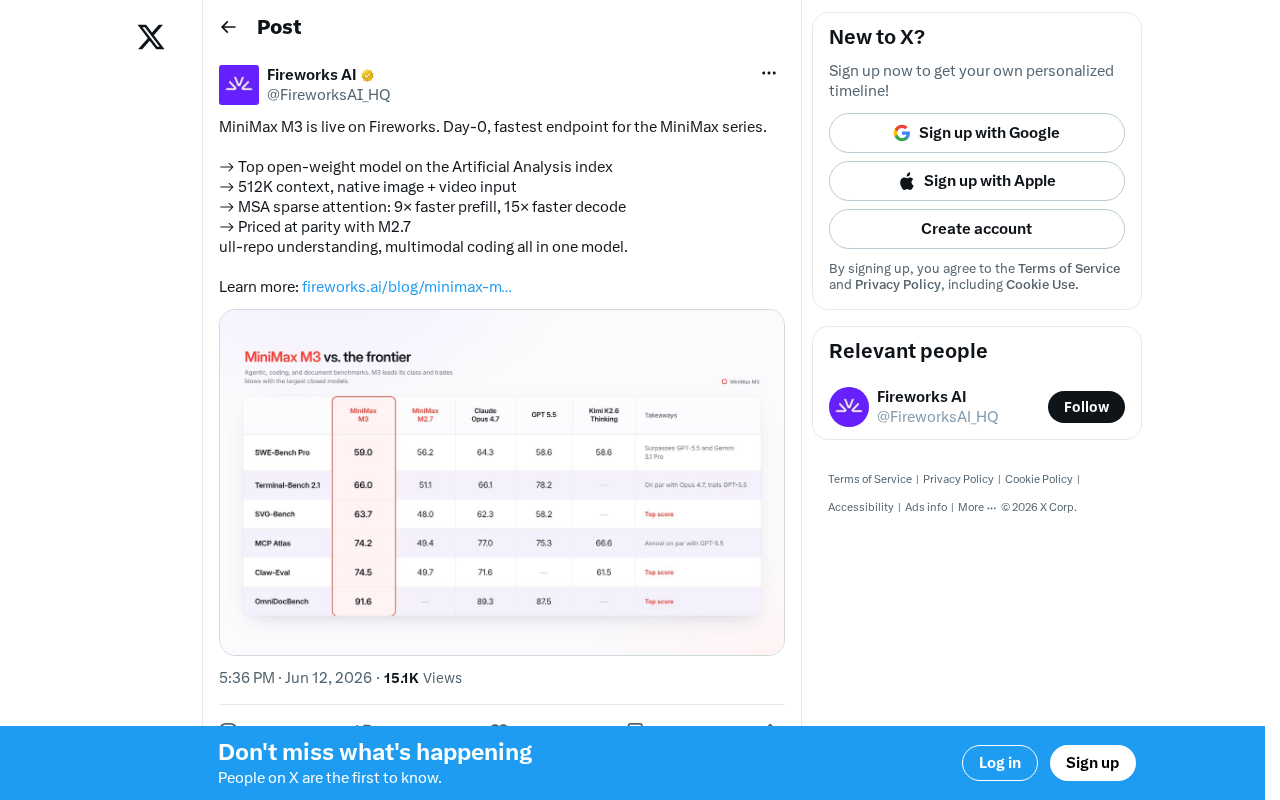
MiniMax M3 Launches on Fireworks: 512K Context and MSA Sparse Attention Explained
MiniMax M3 launches on Fireworks with 512K context and multimodal input. MSA sparse attention delivers 9x prefill and 15x decode speedups. Deep dive into architecture, pricing, and open-model competition.
Read more →
·3 min
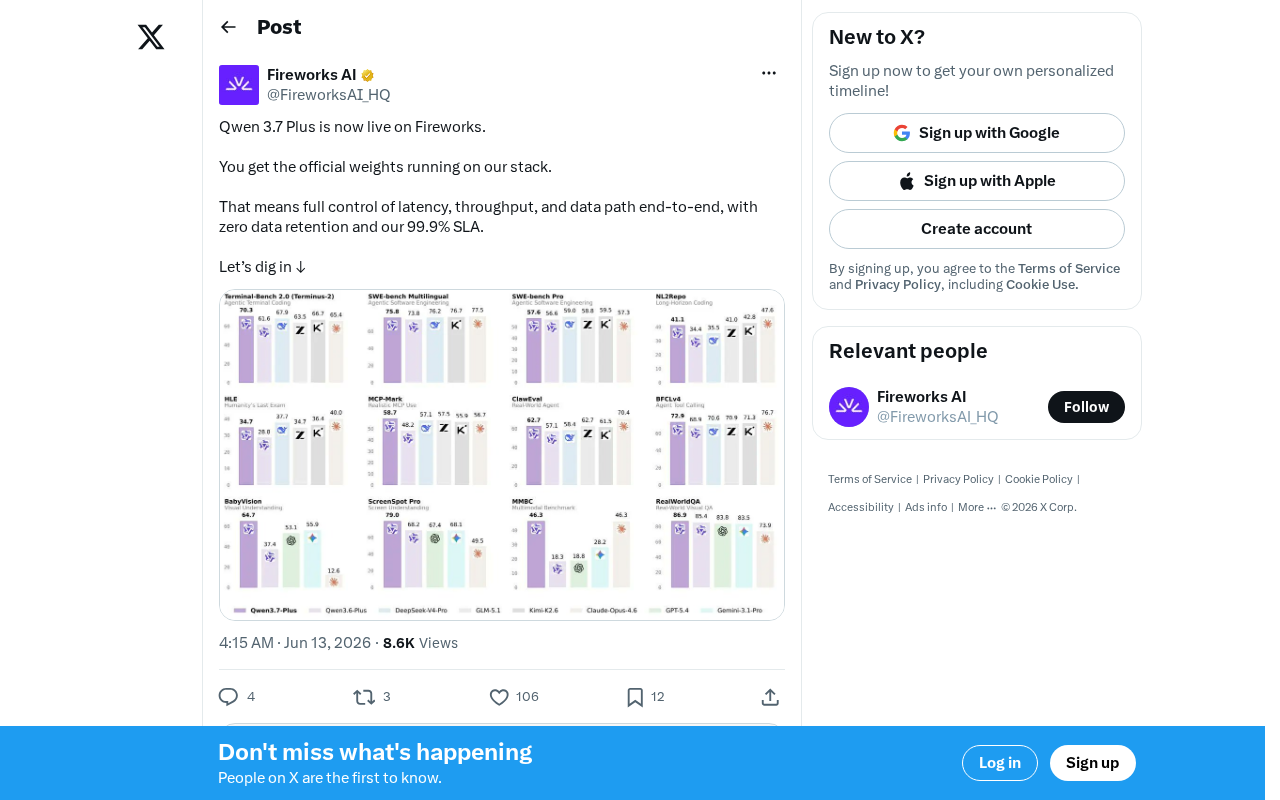
Fireworks AI Launches Qwen 3.7 Plus: Zero Data Retention and 99.9% SLA for Enterprise Deployment
Fireworks AI launches Qwen 3.7 Plus with latency/throughput optimization, zero data retention, and 99.9% SLA enterprise guarantees. Explore the full-stack deployment solution for commercial open-source model inference.
Read more →
·2 min
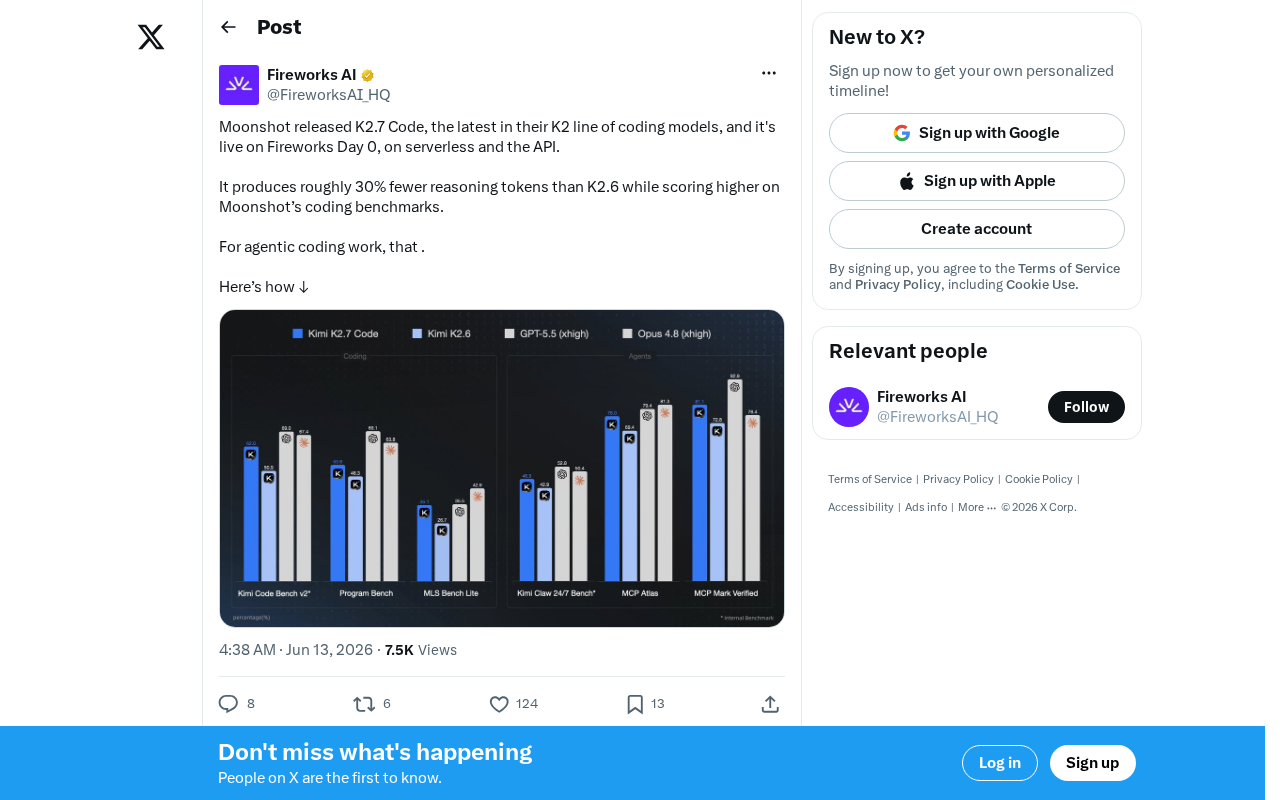
Moonshot K2.7 Code Released: 30% Fewer Reasoning Tokens, Comprehensive Coding Performance Improvements
Moonshot releases K2.7 Code, cutting reasoning tokens by 30% vs K2.6 while boosting coding benchmarks. Now live on Fireworks with serverless API access.
Read more →
·3 min
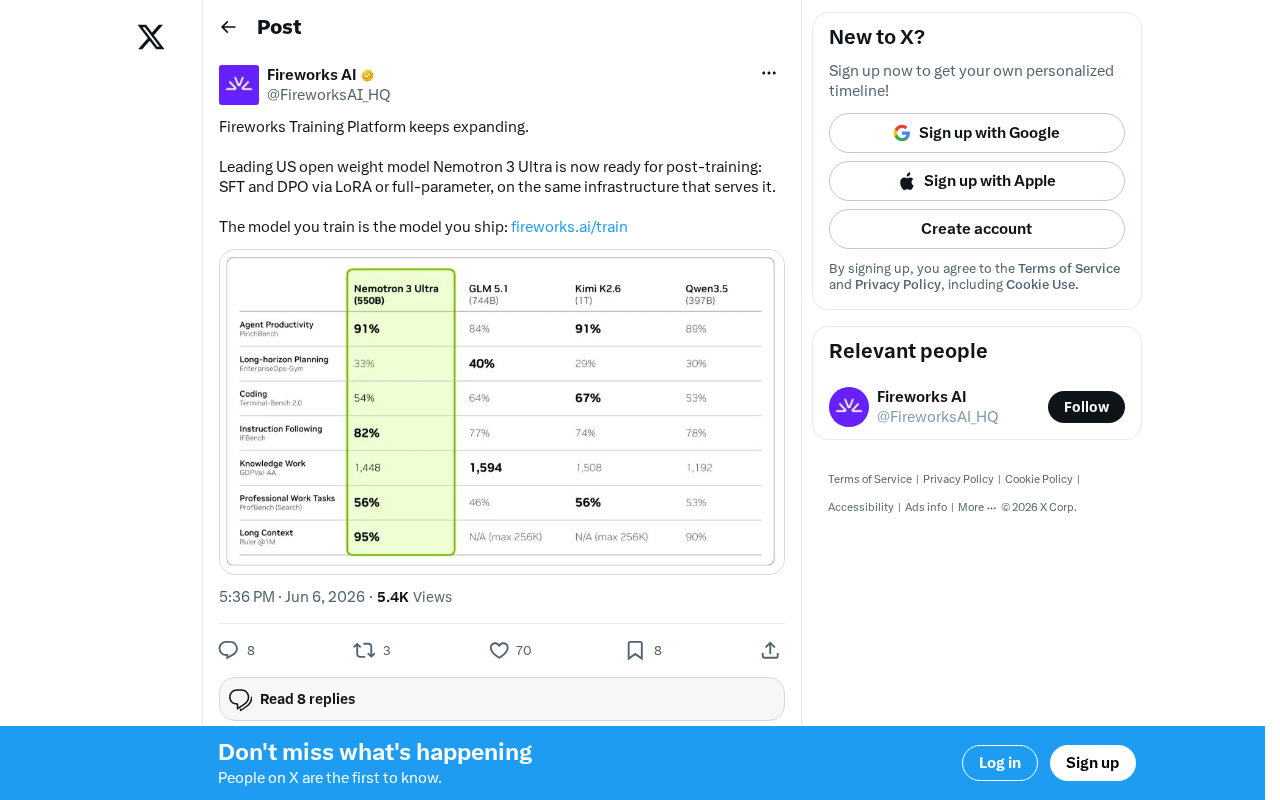
Fireworks Platform Adds Nemotron 3 Ultra Post-Training Support: End-to-End Fine-Tuning and Deployment
Fireworks AI adds NVIDIA Nemotron 3 Ultra post-training support with SFT, DPO, LoRA, and full fine-tuning, enabling seamless train-to-deploy workflows for open-weight LLM customization.
Read more →
 Tutorials
Tutorials·3 min
OpenRouter Free Models Tutorial: Accessing 28 Free AI Models & Deep Dive into the AI Market Landscape
Guide to OpenRouter's 28 free AI models with API setup, covering GPT-OSS 120B, DeepSeek V4 Flash, and leaderboard insights into the AI model market landscape.
Read more →