Fireworks AI Launches Qwen 3.7 Plus: Zero Data Retention and 99.9% SLA for Enterprise Deployment
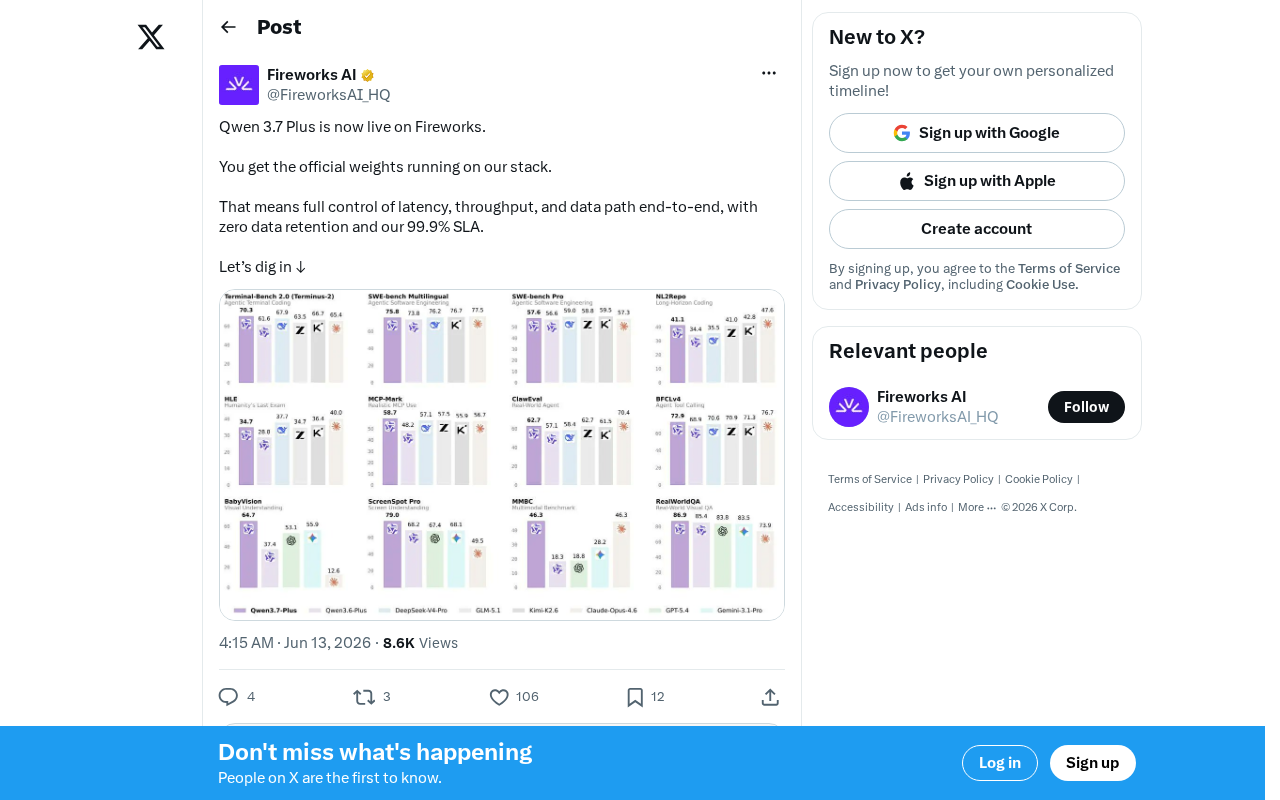
Fireworks AI deploys Qwen 3.7 Plus with enterprise-grade SLA, zero data retention, and optimized MoE inference.
Fireworks AI has launched Qwen 3.7 Plus on its platform, offering enterprise-grade features including fine-grained latency and throughput tuning, zero data retention for compliance, and a 99.9% SLA. The deployment highlights intensifying competition among inference platforms like Together AI, Groq, and Cerebras as open-source model commercialization shifts value toward the inference infrastructure layer.
Qwen 3.7 Plus Arrives on the Fireworks Platform
Fireworks AI recently announced that the Qwen 3.7 Plus model is now officially available on its platform. Users can run this latest model directly using official weights on Fireworks' infrastructure stack.
Qwen 3.7 Plus is the latest-generation large language model from Alibaba's Qwen team. It features a Mixture of Experts (MoE) architecture with approximately 309 billion total parameters, but only about 45 billion parameters are activated during inference. This architectural design allows the model to maintain an extremely high capability ceiling while keeping inference compute costs far below those of a dense model with comparable total parameters. In multiple public benchmarks, Qwen 3.7 Plus has performed on par with or even surpassed some closed-source commercial models, particularly excelling in code generation, mathematical reasoning, and multilingual understanding tasks.
Fireworks AI is an infrastructure company focused on AI model inference services, founded in 2022 by Lin Qiao, a former core member of Meta's PyTorch team. The company's core technical advantage lies in its proprietary inference engine, FireAttention, which is deeply optimized for the Transformer architecture and can significantly boost inference efficiency while preserving model accuracy. Fireworks positions itself not as a training platform but as a service dedicated to delivering open-source models to enterprise users at optimal performance — carving out a distinct niche in the Inference-as-a-Service space.
Core Highlights: End-to-End Full-Stack Control
With this launch of Qwen 3.7 Plus, Fireworks emphasizes end-to-end full-stack control as its core value proposition, covering the following key areas:
Fine-Grained Latency and Throughput Tuning
For AI applications in production environments, latency and throughput are two critically important performance metrics. The Fireworks platform allows users to fine-tune both parameters, enabling developers to flexibly adjust inference configurations based on specific business scenarios — whether real-time conversations or batch processing — to achieve optimal cost-performance ratios.
In LLM inference scenarios, latency is typically broken down into two key metrics: Time to First Token (TTFT) and generation speed (Tokens Per Second, TPS). TTFT measures the wait time between when a user sends a request and when the first output token is received, directly affecting the user's perceived response speed. TPS measures the rate at which the model continuously generates text, determining the user experience in long-text output scenarios. Throughput measures the total number of requests or tokens the platform can process per unit of time at the system level. In practice, there is often a trade-off between latency and throughput — more aggressive batching strategies can improve throughput but may increase latency for individual requests. Fireworks allows users to fine-tune between these two dimensions based on business priorities. For example, real-time chat scenarios can prioritize low latency, while offline data processing scenarios can sacrifice some latency in exchange for higher throughput and lower unit costs.
For MoE architecture models like Qwen 3.7 Plus, inference optimization faces unique technical challenges. During inference, MoE models need to dynamically select which expert modules to activate through a Gating Network, and this routing process itself introduces additional computational overhead and uncertainty in memory access patterns. Additionally, although only about 45 billion parameters are activated per inference pass, all 309 billion parameters still need to be loaded into GPU memory or distributed across multiple GPUs via high-speed interconnects, placing high demands on GPU memory management and inter-card communication bandwidth. Fireworks' proprietary inference engine FireAttention has been specifically optimized for such sparse activation architectures, including Expert Parallelism strategies and intelligent KV Cache management, enabling MoE models to achieve near-theoretically-optimal inference efficiency on its platform.
Zero Data Retention: Data Security and Privacy Assurance
Fireworks explicitly commits to a Zero Data Retention policy. In an era of increasingly stringent enterprise requirements for data privacy and compliance, this feature is particularly critical. User input data and model outputs are not retained by the platform, and the data path is controllable end-to-end. For industries with extremely high data sensitivity — such as finance, healthcare, and legal — this is a core consideration when selecting an AI inference provider.
The technical implementation of a zero data retention policy typically involves multiple layers: at the transport layer, all API requests and responses are transmitted via TLS encryption; at the compute layer, intermediate states during inference (including temporary data such as KV Cache) are immediately cleared from GPU memory and system memory upon request completion; at the storage layer, the platform does not write any user prompts or model outputs to persistent storage. This policy directly addresses the most fundamental concern enterprises have when using third-party AI services — whether their data will be used for model retraining or accessed by third parties. Globally, regulations such as the EU's General Data Protection Regulation (GDPR), the U.S. Health Insurance Portability and Accountability Act (HIPAA), and China's Data Security Law all impose strict requirements on data processing and retention. The zero data retention policy makes it easier for enterprises to meet these compliance frameworks when using Qwen 3.7 Plus hosted on Fireworks, reducing legal and regulatory risk.
99.9% Enterprise-Grade SLA Guarantee
Fireworks provides a 99.9% Service Level Agreement (SLA) for Qwen 3.7 Plus. This commitment means no more than approximately 8.76 hours of unplanned downtime per year — a highly reliable guarantee for production-grade applications requiring high availability.
It's worth noting that "99.9%" (commonly referred to as "three nines") is a standard enterprise-grade availability commitment in the cloud services industry. By comparison, "four nines" (99.99%) means no more than approximately 52.6 minutes of downtime per year, a level typically offered only by core cloud infrastructure services (such as AWS S3 or Google Cloud Spanner). For the relatively nascent field of AI inference services, a 99.9% SLA indicates that Fireworks positions its offering as a production-grade service suitable for critical business processes, not merely a tool for experimentation and prototyping. SLAs typically also include Service Credit provisions — when the platform fails to meet its promised availability level, users can receive corresponding fee reductions, providing enterprises with additional financial protection.
Industry Trend: Intensifying Competition in Commercial Inference for Open-Source Models
Fireworks' launch of Qwen 3.7 Plus reflects an important trend in the AI infrastructure space: competition around commercial inference services for open-source models is intensifying.
As open-source models like Qwen, Llama, and DeepSeek continue to improve in capability, the models themselves are no longer the sole competitive moat. True differentiation is shifting to the inference layer — whoever can deliver lower latency, higher throughput, stronger security guarantees, and more flexible deployment options will hold the advantage in this competition.
Inference platforms such as Fireworks, Together AI, and Groq are engaged in fierce competition along these dimensions. Fireworks' decision to support Qwen 3.7 Plus immediately upon release, with official weights and full-stack control as its selling points, is clearly aimed at capturing first-mover advantage in the enterprise deployment market for open-source models.
These competitors have each adopted different differentiation strategies. Together AI focuses on providing a complete workflow from fine-tuning to inference, allowing users to customize open-source models on its platform and deploy them directly, creating a closed-loop "training-inference integrated" experience. Groq has taken a distinctly different hardware-centric approach — its proprietary LPU (Language Processing Unit) chip is purpose-built for LLM inference, achieving extremely low inference latency through a deterministic compute architecture and frequently setting new records in speed benchmarks, though the scalability of its hardware supply remains a market focus. Additionally, Cerebras, with its wafer-scale chip WSE (Wafer Scale Engine), has also demonstrated remarkable inference speed performance. Traditional cloud providers such as AWS (via Bedrock), Google Cloud (via Vertex AI), and Azure are also actively incorporating open-source models into their managed service ecosystems, leveraging existing enterprise customer relationships and global infrastructure networks to compete.
The essence of this competition is a redistribution of value across the AI industry value chain. As the model layer trends toward open-source and commoditization, value is migrating toward both ends — the inference infrastructure layer and the application layer. By building differentiated advantages in performance optimization, security compliance, and developer experience, inference platforms are becoming an indispensable middle layer connecting open-source models to enterprise applications.
Practical Implications for Developers and Enterprises
For developers and enterprises looking to use Qwen 3.7 Plus in production environments, Fireworks offers a turnkey managed solution. Compared to building inference infrastructure in-house, using a managed service can significantly reduce operational costs and engineering complexity while providing enterprise-grade reliability guarantees.
The barrier to self-hosting a Qwen 3.7 Plus inference service is substantial. Taking its 309 billion total parameter MoE architecture as an example, even with FP8 quantization, fully loading the model weights requires hundreds of gigabytes of GPU memory, typically necessitating multiple servers equipped with high-end GPUs (such as NVIDIA H100 or A100) interconnected via high-speed NVLink or InfiniBand to form an inference cluster. Beyond hardware costs, teams also need to master a series of complex engineering techniques including model parallelism (Tensor Parallelism, Pipeline Parallelism, Expert Parallelism), dynamic batching, KV Cache optimization, and quantized deployment, along with ongoing investment in system monitoring, fault recovery, and performance tuning. For most enterprises, the total cost of ownership (TCO) of these investments far exceeds the cost of using a managed inference service.
That said, developers should still consider factors such as pricing strategies, regional coverage, and compatibility with existing tech stacks when choosing an AI inference platform to make the best decision for their business needs. Pricing deserves particular attention — different platforms have varying billing approaches for MoE models. Some charge based on activated parameters (closer to actual compute costs), while others charge based on total parameters, which can significantly impact final usage costs. Additionally, whether the platform supports advanced features like Function Calling, Structured Output, and long context windows, as well as API compatibility details (such as OpenAI API format compatibility), are all important factors to carefully evaluate during technical selection.
Related articles
Frontend to AI Agent Architect: A Complete 3-Month Learning Roadmap
How can frontend engineers transition to AI Agent development? A systematic 3-month roadmap covering AI concepts, model selection, team productivity, and Agent architecture.

Replit CEO on the Rise of AI-Native Developers: Future Companies Will Have Only Builders and Sellers
Replit closes $400M Series D at $9B valuation. CEO Amjad shares insights on vibe coding, Agent 4 parallel agents, cross-platform deployment, and how AI is reshaping companies and software development.
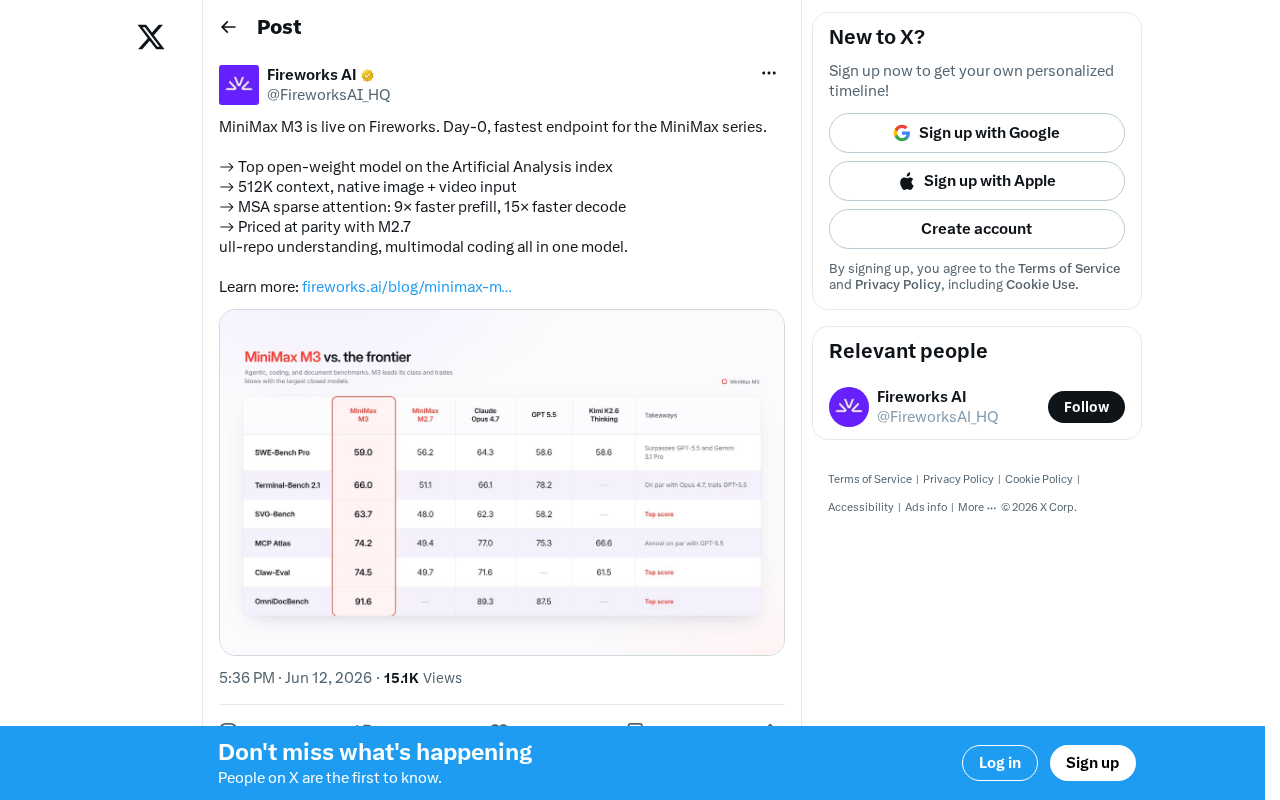
MiniMax M3 Launches on Fireworks: 512K Context and MSA Sparse Attention Explained
MiniMax M3 launches on Fireworks with 512K context and multimodal input. MSA sparse attention delivers 9x prefill and 15x decode speedups. Deep dive into architecture, pricing, and open-model competition.