MiniMax M3 Launches on Fireworks: 512K Context and MSA Sparse Attention Explained
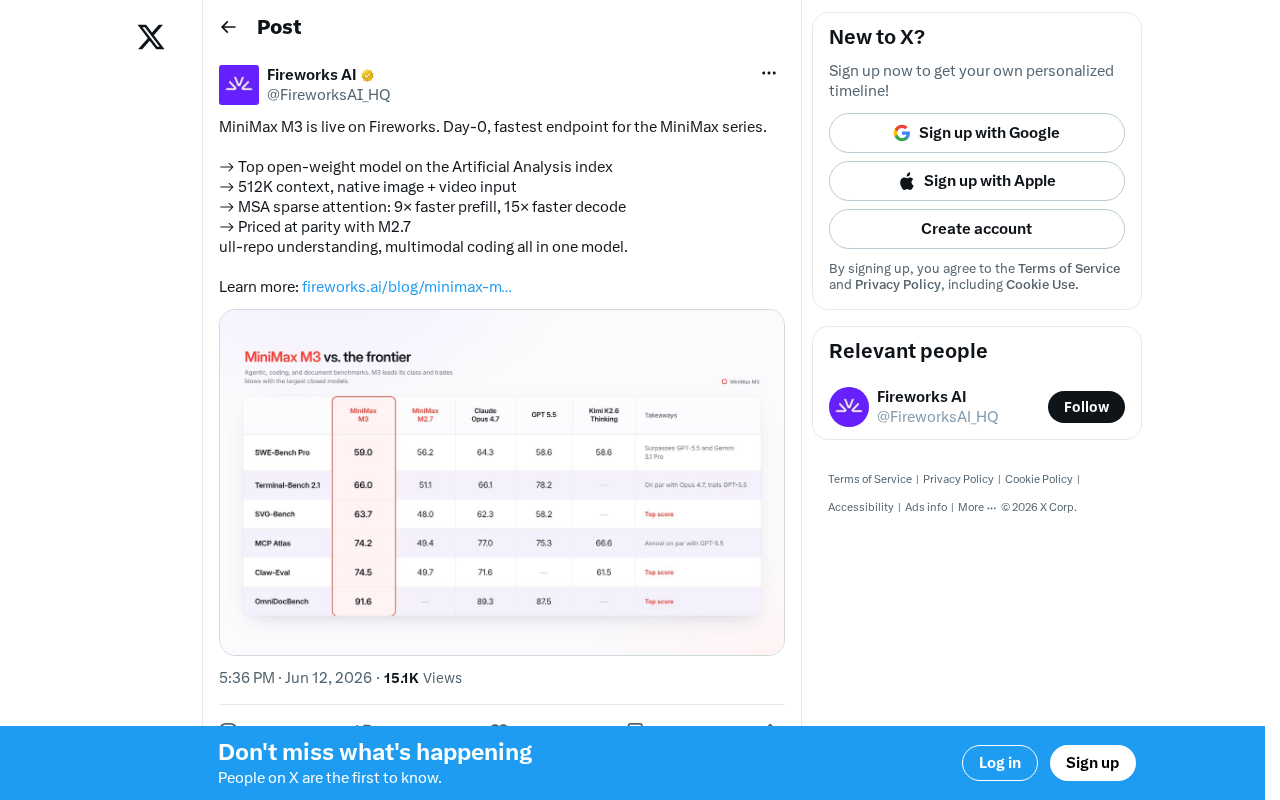
MiniMax M3 tops open-weight rankings with 512K context and MSA sparse attention on Fireworks.
MiniMax M3 launched Day-0 on Fireworks, topping Artificial Analysis's open-weight model index. Featuring a 512K context window, native multimodal input, and MSA (Mixed Sparse Attention) delivering 9x prefill and 15x decode speedups, M3 targets long-horizon agents, full-repo code analysis, and multimodal programming — all at the same price as its predecessor M2.7.
MiniMax M3 Officially Launches on Fireworks Platform
The MiniMax M3 model went live on the Fireworks platform on Day-0 of its release, becoming the fastest inference endpoint in the MiniMax lineup. The model topped the Artificial Analysis benchmark index for open-weight models, signaling a new phase in the open-source LLM competition.
Fireworks AI is a cloud platform specializing in LLM inference services, founded by former members of Meta's AI infrastructure team. Its core competitive advantage lies in providing developers with low-latency, high-throughput model API services through deep-level optimizations such as its proprietary inference engine, FireAttention. Day-0 availability means the model was callable via Fireworks' API on the very day of release — something uncommon among inference providers, as new models typically require adaptation, optimization, and stress testing before going live. Day-0 support indicates that Fireworks and MiniMax collaborated deeply before the model's release to complete inference stack integration, which also reflects strong mutual confidence in M3's commercial prospects.
Artificial Analysis is an independent AI model evaluation and benchmarking platform whose index comprehensively assesses model performance across multiple dimensions, including reasoning quality (benchmarks like MMLU and HumanEval), inference speed (time-to-first-token latency and throughput), and cost-effectiveness. M3 topping the open-weight model leaderboard means it didn't just excel in a single category — it achieved the best overall balance across quality, speed, and cost.
Core Technical Highlights
512K Ultra-Long Context and Multimodal Capabilities
MiniMax M3 supports a context window of up to 512K tokens and natively accepts image and video inputs. Developers can handle ultra-long document comprehension, full-repository code analysis, and multimodal programming tasks within a single model — no need to switch between multiple specialized models.
The context window refers to the maximum number of tokens a large language model can process in a single inference call. 512K tokens is roughly equivalent to 700,000–800,000 English words, or about 400,000–500,000 Chinese characters. For reference, GPT-4 Turbo has a 128K context window, and Claude 3.5 Sonnet supports 200K. A 512K context length means the model can ingest an entire full-length novel, the complete source code of a mid-to-large software project, or hundreds of pages of legal contracts in one pass. However, the core challenge of ultra-long context lies in the computational complexity of the attention mechanism — standard Transformer self-attention scales quadratically with sequence length, meaning the computational cost at 512K is 16 times that of 128K. This is precisely the problem that the MSA sparse attention mechanism is designed to solve.
A 512K context length is top-tier among open-source models, sufficient to accommodate complete large codebases or hundreds of pages of technical documentation, providing a solid infrastructure foundation for long-horizon agent applications.
MSA Sparse Attention: A Leap in Inference Performance
M3's most significant technical innovation is its MSA (Mixed Sparse Attention) mechanism. According to official figures:
- 9x faster prefill: Dramatically reduces time-to-first-token latency
- 15x faster decoding: Significantly boosts token generation throughput
Full attention in standard Transformers requires every token to compute attention scores with all other tokens in the sequence, resulting in O(n²) complexity. The core idea behind sparse attention is that not all token-pair attention scores are equally important — complexity can be reduced by selectively skipping unimportant attention computations. The industry has already seen various sparse attention approaches, such as Longformer's sliding window attention and BigBird's random + local + global hybrid pattern. MiniMax's MSA employs a mixed strategy, likely combining local attention (focusing on nearby tokens), global attention (focusing on key anchor tokens), and content-based dynamic sparse selection, among other patterns — maintaining model expressiveness while dramatically reducing computation.
To understand what these speedup numbers mean, it's important to understand the two phases of LLM inference. The prefill phase is when the model processes the entire user prompt at once, computing attention across all input tokens and generating the KV Cache. This phase is compute-intensive and determines how long the user waits to see the first output character (i.e., Time-to-First-Token / TTFT). The decode phase is when the model generates output tokens one by one, with each new token requiring attention computation against the KV Cache of all preceding tokens. This phase is memory-bandwidth-intensive and determines the text generation speed (i.e., throughput / TPS). Under 512K ultra-long context scenarios, performance bottlenecks in both phases are dramatically amplified, making MSA's 9x and 15x speedups in these respective phases extremely valuable in practice.
This sparse attention design dramatically reduces inference cost and latency while preserving model quality. For applications requiring ultra-long context processing, this optimization is especially critical — the computational overhead of traditional full attention at 512K length is nearly prohibitive, and MSA makes large-scale long-text inference practically viable.
Pricing Strategy and Market Positioning
MiniMax M3's pricing remains the same as its predecessor M2.7 — a highly competitive strategy. Maintaining the same price while delivering significantly improved performance essentially gives developers a free capability upgrade.
From an application perspective, M3 targets three high-value use cases:
- Long-horizon agents: 512K context enables agents to maintain longer task memory and reasoning chains
- Full-repository code comprehension: Loading an entire codebase at once for analysis and modification
- Multimodal programming: Combining image and video inputs for UI reproduction, visual debugging, and similar tasks
AI Agents are one of the core application directions for LLMs today, referring to AI systems capable of autonomously planning and executing multi-step tasks. The key challenge for long-horizon agents is the "memory" problem — as task steps accumulate, the agent needs to remember previous action results, intermediate reasoning processes, and environment states. Traditional short-context models force developers to adopt external memory mechanisms (such as vector database retrieval), which not only increase system complexity but may also cause the agent to "forget" critical information due to incomplete retrieval. A 512K context window combined with extremely fast inference speed allows agents to keep their complete task history within the context, enabling more coherent long-chain reasoning — particularly important for complex application scenarios like software development agents, data analysis agents, and research assistants.
Open-Source Model Competitive Landscape
MiniMax M3 topping the Artificial Analysis open-model index is a noteworthy achievement. The current open-source LLM space is fiercely competitive, with the Llama, Qwen, and DeepSeek series continuously iterating. MiniMax's ability to stand out demonstrates genuine innovation in model architecture and training strategy.
The open-source LLM landscape has evolved into a multi-player competition. Meta's Llama series holds a significant position thanks to its first-mover advantage and massive community ecosystem — Llama 3.1 405B was one of the largest open-source models. Alibaba's Qwen series excels in bilingual Chinese-English capabilities, with Qwen2.5 covering a full parameter range from 0.5B to 72B. DeepSeek has attracted industry attention with its MoE (Mixture of Experts) architecture and highly competitive cost-performance ratio, with DeepSeek-V3 approaching closed-source model performance on multiple benchmarks. MiniMax previously gained recognition with its M2.7 model, and the release of M3 marks its transition from challenger to leader. It's worth noting the distinction between "open weight" and "open source" — the former typically only makes model weights publicly available for download and use, while training data, training code, and other components may not be fully disclosed.
Sparse attention is not a new concept, but MSA's ability to achieve 9x to 15x speedups in actual deployment without sacrificing benchmark performance demonstrates deep engineering expertise. Fireworks' decision to provide Day-0 support for M3 also signals inference providers' confidence in its commercial viability.
Practical Implications for Developers
For developers building AI applications, M3's combined advantages — ultra-long context, multimodal input, extremely fast inference, and open weights — present a highly attractive option. Especially in the agent and code intelligence domains, 512K context paired with 15x decode acceleration means end-to-end completion times for complex tasks can be dramatically reduced.
It will be worth watching whether M3's real-world production performance lives up to its benchmark promises, and what kind of fine-tuning and application ecosystem the community will build around its open weights.
Key Takeaways
Related articles
Frontend to AI Agent Architect: A Complete 3-Month Learning Roadmap
How can frontend engineers transition to AI Agent development? A systematic 3-month roadmap covering AI concepts, model selection, team productivity, and Agent architecture.

Replit CEO on the Rise of AI-Native Developers: Future Companies Will Have Only Builders and Sellers
Replit closes $400M Series D at $9B valuation. CEO Amjad shares insights on vibe coding, Agent 4 parallel agents, cross-platform deployment, and how AI is reshaping companies and software development.
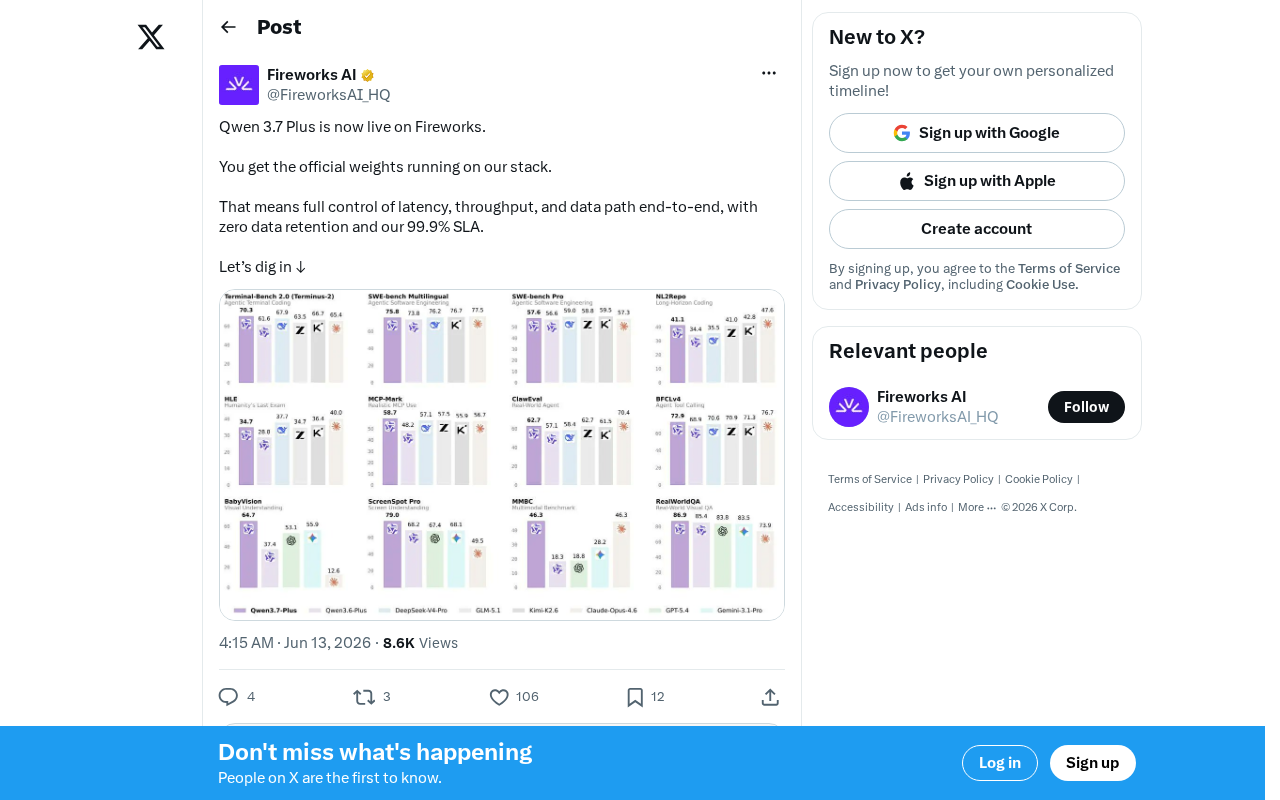
Fireworks AI Launches Qwen 3.7 Plus: Zero Data Retention and 99.9% SLA for Enterprise Deployment
Fireworks AI launches Qwen 3.7 Plus with latency/throughput optimization, zero data retention, and 99.9% SLA enterprise guarantees. Explore the full-stack deployment solution for commercial open-source model inference.