Gemini Omni Explained: A Major Breakthrough in Multimodal Understanding and Video Editing
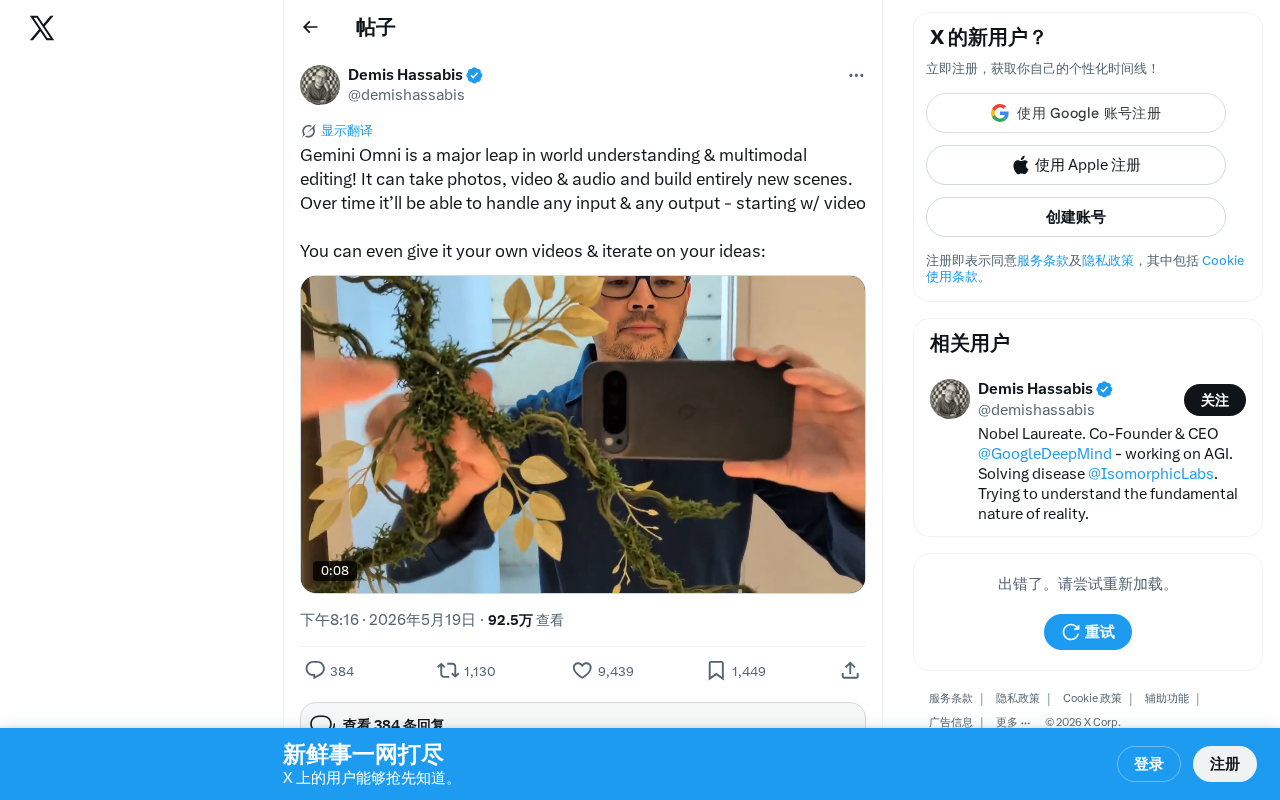
Google's Gemini Omni enables multimodal understanding and interactive video creation from any input type.
Google's Gemini Omni represents a major breakthrough in multimodal AI, capable of processing images, video, and audio inputs to generate new visual scenes. Built on a native multimodal architecture, it offers an iterative video editing workflow that democratizes content creation, lowering barriers for both professionals and everyday users while consolidating Google's lead in the multimodal AI space.
Core Breakthrough: Full-Modal AI from Understanding to Creation
Google's latest release, Gemini Omni, marks a significant leap in AI's world understanding and multimodal editing capabilities. This model can receive various inputs including photos, videos, and audio, and build entirely new scene content based on these materials.
The development of multimodal AI has undergone a long evolution from single-modal to cross-modal to full-modal systems. Early AI systems could only process a single type of data—text models handled text, image models handled pictures, and speech models handled audio. Around 2020, cross-modal models like CLIP and DALL-E began to emerge, achieving mapping between text and images. However, these models were essentially "bridging" different modalities rather than achieving true unified understanding. The Gemini series adopted a native multimodal design at the architectural level, meaning the model receives multiple types of data simultaneously during training, allowing it to learn the intrinsic correlations between different modalities within a unified representation space. It is precisely this technical foundation that enables Gemini Omni to achieve the leap from "perception" to "creation."
Gemini Omni's Multimodal Fusion Capabilities
The Design Philosophy of Any Input, Any Output
Gemini Omni's core capability lies in its truly multimodal processing. Unlike previous AI systems that needed to handle different types of data separately, Gemini Omni can simultaneously understand and process:
- Image input: Understanding scenes, objects, and contextual relationships in photos
- Video input: Analyzing temporal information and motion patterns in dynamic footage
- Audio input: Processing speech, ambient sounds, and other auditory information
More critically, it can not only understand these inputs but also generate entirely new visual scenes based on its understanding, achieving the leap from "perception" to "creation." Google's concept of "world understanding" is closely related to the "World Model" research that has attracted significant attention in the AI field in recent years. The core idea of world models is to have AI not only learn the surface statistical patterns of data but also build internal representations of how the physical world operates—including understanding three-dimensional spatial relationships of objects, occlusion and perspective, lighting variation patterns, and basic physical intuitions such as gravity, collision, and fluid behavior. Meta's Chief AI Scientist Yann LeCun has repeatedly emphasized that world models are the key path to true intelligence. The scene construction capabilities demonstrated by Gemini Omni in video generation are precisely the manifestation of this world understanding in practical applications.
Video Generation as the First Landing Scenario
Google has explicitly stated that Gemini Omni's goal is to ultimately handle any type of input and produce any type of output. Currently, this capability is first being deployed in video generation. Users can provide their own video materials and then continuously optimize and develop their creative ideas through iterative interaction with the AI.
A New Paradigm for Interactive Video Creation
Iterative Video Editing Workflow
One of Gemini Omni's most exciting features is its interactive creation workflow. Users no longer need to provide perfect instructions all at once; instead, they can follow these steps:
- Provide original video or image materials
- Describe the desired effect in natural language
- Review the AI-generated results
- Make further adjustments and iterations based on the results
This workflow more closely mirrors the natural thinking process of human creators—starting with a rough idea and then continuously refining it through practice.
Traditional video production follows a strict linear process: pre-production planning, scriptwriting, shooting, post-production editing, and visual effects compositing, with each stage requiring specialized personnel and professional tools. Post-production visual effects alone require months or even years of learning to master software like After Effects or Nuke. The iterative creation paradigm proposed by Gemini Omni essentially borrows from the "agile development" philosophy in software engineering—rapid prototyping, continuous iteration, and instant feedback. This model frees creators from the burden of technical execution, allowing them to focus more energy on creativity itself.
Profound Impact on the Video Creation Industry
The emergence of this capability means that the barrier to video creation will be significantly lowered. Whether professional filmmakers or everyday users, anyone can leverage Gemini Omni to quickly transform creative ideas into visual content. From proof of concept to final product, the entire process can be efficiently completed with AI assistance. The industry refers to such tools as important drivers of "creative democratization," as they ensure that high-quality content creation is no longer monopolized by a few teams with specialized technical skills.
Technical Significance and Industry Outlook
The release of Gemini Omni reflects Google's deep technical expertise in the multimodal AI field. The term "world understanding" suggests that this model is not merely performing pattern matching but is building a deep understanding of the physical world—including spatial relationships, physical laws, and semantic logic.
From a competitive landscape perspective, Gemini Omni's release further consolidates Google's leading position in the multimodal AI track. The main participants in this space currently include OpenAI (GPT-4o series and Sora video model), Meta (Emu series multimodal models), and startups focused on video generation such as Runway and Pika. Google's differentiating advantage lies in its "native multimodal" architectural design philosophy—the Gemini series was designed from the beginning to handle multiple modalities in a unified manner, rather than achieving this by stitching together different modules as some competitors do. Additionally, Google possesses YouTube, the world's largest video data resource, providing an unparalleled data advantage for model training.
As model capabilities continue to evolve, we can foresee that future AI will truly achieve universal creative capabilities of "any input, any output," which will fundamentally transform workflows across multiple industries including content creation, education, and entertainment.
Related articles

Claude Code for Test Development in Practice: An AI Programming Workflow That Doubles Your Efficiency
A practical guide to Claude Code for test development: auto-generating test scripts, Plan Mode workflows, MCP + Playwright integration, and Subagent parallel tasks to build systematic AI-assisted workflows.

Hermes Agent Hands-On Review: An AI Efficiency Revolution for Indie Game Developers
Indie game developer reviews Hermes Agent vs OpenClaude: intelligent context compression, real-time Memory, remote control via Telegram, and practical use cases in game dev, social media, and email.

Vibe Coding Beginner's Guide: Tool Selection Across Three Categories with Practical Examples
A comprehensive guide to Vibe Coding's three tool categories: Agent frameworks, CLI Coding, and IDE tools, with practical examples including Snake game and data analysis workbench.