Getting Started with LLM Application Development from Scratch: A Complete Guide to Learning Paths and Career Directions
Beginners can break into the LLM industry through the application development path — no algorithm background required.
The LLM industry has shifted from algorithm research to application development, making it accessible without an algorithms background. Core directions include API calling, RAG knowledge base construction, and Agent development. Getting started requires Python programming, API calling skills, and frameworks like LangChain. A recommended learning path progresses from RAG to Agent to fine-tuning, and now is the ideal time to jump in.
With the explosive growth of large language models like ChatGPT and Qwen, virtually every company is exploring how to integrate LLMs into their business. But for many developers without an AI background, one core question lingers: Can I break into the LLM industry without a foundation in algorithms?
The answer is: absolutely yes. And now is the best time to get started.
The Paradigm Shift in the LLM Industry: From Algorithm Research to Application Development
In the early days, AI work was primarily driven by algorithm engineers — researching deep learning, training neural networks, and tuning model parameters. These tasks genuinely required a solid foundation in mathematics and algorithms. But the LLM industry has entered an entirely new phase: the application development phase.
What does this mean? Most companies don't need to train a large model from scratch. What they really need are people who can take existing LLM capabilities and deploy them in real business scenarios. Intelligent customer service, enterprise document assistants, automated task AI — these are all typical application development needs.
As a result, a new role has emerged in the industry: LLM Application Development Engineer. The core of this role isn't training models — it's building applications with LLMs.
What Is a Large Language Model? Explained in One Sentence
Many people find "large language model" intimidating, but it can actually be explained in one sentence:
A large language model is an AI system trained on massive amounts of data that can understand and generate human language.
It can answer questions, write articles, write code, summarize content, translate, and perform data analysis — as long as the task involves language, an LLM can participate. This is why the industry refers to large language models as "general-purpose capability platforms": unlike traditional software that does only one thing, they can be applied across numerous scenarios.
From a technical perspective, the core architecture of large language models is the Transformer, proposed by Google in the 2017 paper Attention Is All You Need. Its key mechanism is "Self-Attention," which enables the model to understand the relationships between every word in a sentence, capturing long-range semantic dependencies. Mainstream LLMs like the GPT series, LLaMA, and Qwen all evolved from this architecture. The "large" in large language models refers to parameter scale — GPT-4 is estimated to have over a trillion parameters, with training data covering hundreds of billions of Tokens. It's this scale effect that gives rise to "emergent abilities" such as reasoning, code generation, and multilingual understanding, far exceeding the boundaries of earlier small models. Application developers don't need to deeply understand these underlying principles, but knowing why LLMs can do what they do helps make better technical decisions during actual development.
Three Major Directions in LLM Application Development
Once you enter this field, your work will generally revolve around three directions:
Direction 1: Calling LLM APIs
This is the most fundamental and direct direction. Major model providers (OpenAI, Baidu, Alibaba, etc.) all offer API interfaces that allow developers to call models programmatically for tasks like article generation, intelligent customer service, and AI assistants. Essentially, it's about learning how to "converse" with an LLM through code.
In API calling, there are two core concepts you must master. Token is the basic unit by which LLMs process text, and it's not simply equivalent to a "character" or "word" — in English, one Token is roughly 0.75 words, while in Chinese, one character typically corresponds to 1-2 Tokens. Token count directly determines API call costs and the model's context window limit. GPT-4 Turbo supports a 128K Token context, roughly equivalent to a novella in length. Prompt Engineering involves systematically designing input instructions to guide the model toward producing expected outputs. Core techniques include: Few-shot Prompting, which provides examples to standardize output format; Chain-of-Thought prompting, which has the model reason step by step to improve accuracy on complex tasks; and System Prompt, which sets the model's role and behavioral boundaries. Prompt Engineering may seem simple, but it's actually the most direct factor affecting product quality in LLM application development.
Direction 2: Building RAG Knowledge Base Systems
Every enterprise has its own private data — product documentation, technical manuals, company materials, etc. LLMs don't inherently know this content, so RAG (Retrieval-Augmented Generation) technology is needed to connect enterprise data with the LLM.
RAG was proposed by Meta AI in 2020 to address two core LLM deficiencies: knowledge cutoff dates and hallucination problems. Its workflow consists of three steps: First, enterprise documents are split into small chunks, converted into high-dimensional vectors via an Embedding model, and stored in a vector database (such as Faiss, Chroma, or Milvus). When a user asks a question, the system vectorizes the query as well, performs similarity search in the database, and retrieves the most relevant document fragments. Finally, the retrieved results are concatenated into the Prompt as context, and the LLM generates the final answer. This "retrieve first, generate second" paradigm enables LLMs to answer based on real-time, private enterprise data, significantly improving accuracy and trustworthiness. It's one of the most common technical approaches in enterprise-level applications today.
Direction 3: Agent Development
When application scenarios become more complex, simple Q&A from AI is no longer sufficient. We want AI to autonomously complete tasks — calling tools on its own, making decisions, and executing multi-step operations.
Agent implementation relies on the ReAct (Reasoning + Acting) framework — the model completes complex tasks through iterative cycles of "think → act → observe." A complete Agent system typically includes four core components: the LLM serves as the "brain" responsible for reasoning and decision-making; a Tool set (such as search engines, code executors, and database query interfaces); a Memory module for storing conversation history and intermediate results; and a Planning module responsible for breaking down complex goals into executable sub-task sequences.
For example: a user asks the AI to generate an industry report, and the AI can independently search for information, organize the data, and produce a complete report. This kind of system with autonomous action capability is an Agent, which truly transforms LLMs from "able to talk" to "able to act." Frameworks like LangGraph further introduce directed graph structures, making multi-Agent collaboration and complex workflow orchestration possible.
What Prerequisites Do Beginners Need?
The good news is that the entry barrier isn't as high as you might think. You only need three foundations:
-
Python Programming Basics: Currently, the vast majority of AI development frameworks (LangChain, LlamaIndex, etc.) are Python-based, and Python is the core language of the AI ecosystem. This is an essential first step.
-
LLM API Calling Skills: Understanding basic concepts like Prompt design, Tokens, and model parameters. Essentially, it's about learning how to communicate correctly with an LLM.
-
Application Development Frameworks: Writing everything from scratch is extremely costly, which is why frameworks like LangChain, LangGraph, and LlamaIndex have emerged. They help developers efficiently manage model calls, tool integration, knowledge base construction, and Agent system building.
Among these, LangChain was released by Harrison Chase in October 2022 and became one of the fastest-growing open-source projects on GitHub within months, currently with over 90,000 stars. Its core value lies in providing a standardized abstraction layer that encapsulates the most common patterns in LLM development — Chain calls, Tool integration, Memory management, and Document Loaders — into reusable components. Developers don't need to implement complex scheduling logic from scratch; they simply combine these components to rapidly build applications. LangSmith, which pairs with LangChain, provides observability and debugging capabilities, while LangGraph focuses on stateful multi-step Agent workflows. The entire LangChain ecosystem has become the de facto standard toolchain in LLM application development — mastering it means mastering the industry's common language.
Recommended Learning Path: A Step-by-Step Approach
For beginners starting from scratch, the following progressive learning path is recommended:
Phase 1 (L1): Building Foundational Skills (approximately 1 month)
- AI fundamental concepts
- Python programming and API calling
- RAG knowledge base construction
- Agent basics
Phase 2 (L2): Advanced Skill Development
- Fine-tuning
- Advanced Prompt Engineering
- Complex Agent system design
Phase 3: Hands-on Projects
- Enterprise-level project practice
- Complete end-to-end application development
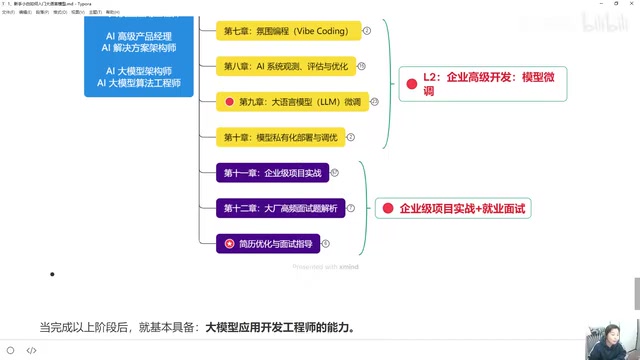
Currently, there are over a dozen enterprise-level project cases available for hands-on practice, covering scenarios from basic to advanced. After completing the entire learning path, you'll have the fundamental skills of an LLM Application Development Engineer.
Why Now Is the Perfect Time to Get Started
In the AI era, technology iterates rapidly, and new roles are constantly emerging. Beyond LLM Application Development Engineers, new positions like Agent Development Engineers, AI Product Managers, and LangChain Engineers have appeared.
For those looking to transition into the AI industry, what matters most isn't what you've learned in the past, but whether you're willing to get started early. In the tech industry, those who enter earliest tend to accumulate experience and build advantages most easily. The LLM field is still in a very early stage of development — it's absolutely not too late to start learning now.
The key is to take action: learn RAG first, then Agent, then fine-tuning — step by step, methodically. You absolutely have the opportunity to enter this industry and participate in the wave of AI technological advancement.
Key Takeaways
- The LLM industry has shifted from algorithm research to application development — beginners with no prior experience can absolutely get started
- Three major directions in LLM application development: API calling, RAG knowledge base construction, and Agent development
- Only three foundations needed to get started: Python programming, LLM API calling, and application development frameworks (such as LangChain)
- Recommended learning path: start with RAG knowledge bases, then Agent development, and finally fine-tuning
- The LLM field is still in its early stages — now is the best time to get in and start building experience
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.