GML 5.2 Multimodal Upgrade Hands-On: Full Validation with DeepSeek V4
Validating multimodal upgrades for GML 5.2 and DeepSeek V4 via workflow orchestration on OneBlockBase.
This article documents a hands-on test using the OneBlockBase platform to upgrade GML 5.2 and DeepSeek V4 text models with multimodal capabilities through workflow orchestration. It covers the vision-text pipeline design, pre-execution safety mechanisms, interface generation results, model performance comparisons, and deployment configuration best practices.
Overview: A Critical Step from Text Models to Multimodal
With the rapid iteration of large model technology, upgrading pure text models to multimodal capabilities has become a major trend in AI application development. Multimodal refers to an AI system's ability to simultaneously process and understand multiple types of data input, including text, images, audio, video, and more. Traditional large language models (LLMs) can only handle pure text input and output, but the introduction of multimodal capabilities breaks through this limitation. There are two main technical paths to achieving multimodal capabilities: one is training native multimodal models from the ground up (such as GPT-4o and Gemini), which requires massive amounts of paired multimodal data and enormous computational resources; the other is orchestrating external workflows that chain together vision encoders, speech recognition modules, and other components with text models to form a pipeline-based multimodal processing system. The latter approach offers the advantages of high flexibility, controllable costs, and the ability to quickly adapt to different underlying text models.
Recently, a developer shared hands-on experience on Bilibili demonstrating how they successfully integrated models like GML 5.2 and DeepSeek V4 into a multimodal workflow using the OneBlockBase platform. This article summarizes the core findings from this test, including model integration methods, multimodal workflow construction, and actual runtime performance.
Test Environment: Model Integration on OneBlockBase
The core platform for this test was OneBlockBase, a development framework that supports multi-model integration and orchestration. Platforms like OneBlockBase fall under the category of AI application middleware. In the current AI technology stack, the bottom layer consists of foundation models, the top layer comprises user-facing applications, and the middleware layer is responsible for combining, orchestrating, and managing model capabilities. Similar platforms include LangChain, Dify, Coze, and others. Their core value lies in: providing visual workflow designers that allow developers to build complex AI processing pipelines by dragging and dropping nodes; unifying API interfaces across different models to enable rapid model switching and comparative testing; and including commonly used intermediate processing modules such as text splitting, vector retrieval, and format conversion.
The developer built a web project on this platform, configuring different model nodes to implement a multimodal task processing pipeline.
Specifically, the models integrated in this test included:
- GML 5.2: Serving as the primary text understanding and generation model
- DeepSeek V4: Also fully validated through the complete pipeline
- Claude: Also tested internally with integration
The developer noted that all these models can be called directly from OneBlockBase's plugin library, and the platform automatically detects and displays the currently active model type, making it convenient for developers to debug and switch between models.
Implementation Logic of the Multimodal Workflow
Visual Recognition and Text Collaboration
The core of the multimodal upgrade lies in enabling text models to process visual information. In this test, the workflow was designed as follows: first, a vision module recognizes images and generates structured scene descriptions, then these descriptions are passed to text models like GML or DeepSeek, which use the visual descriptions to further generate software interfaces, adjust color schemes, or perform other complex tasks.
From a technical perspective, the key component in this pipeline is the Vision Encoder. Vision encoders are typically based on the ViT (Vision Transformer) architecture, which divides input images into fixed-size patches and then converts each patch into high-dimensional vector representations through a Transformer encoder. These vectors are subsequently mapped through a Projection Layer into a semantic space that the text model can understand. In native multimodal models, this process is trained end-to-end; in workflow orchestration approaches, the vision encoder's output is usually first converted into natural language descriptions (i.e., image captions or scene descriptions), which are then fed as text input to the downstream language model. While this approach may lose some fine-grained visual information, its strength lies in its universality — it can work with virtually any text model.
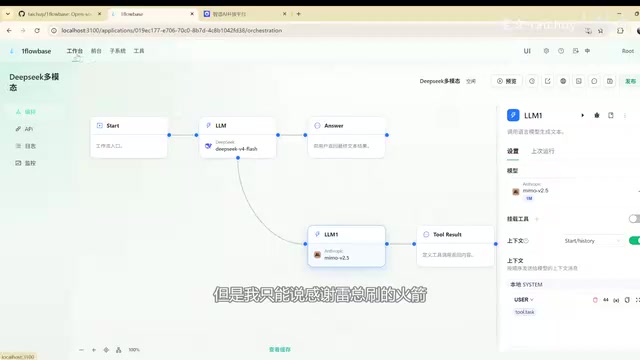
This "visual recognition → structured description → text model reasoning" pipeline architecture effectively extends the capabilities of pure text models into the multimodal domain without requiring any modifications to the underlying models themselves.
Pre-execution Interception and Safety Mechanisms
One noteworthy detail: the developer incorporated a pre-execution interception mechanism into the workflow. When the model first attempts to directly execute certain operations, the system performs safety checks and applies restrictions to ensure the output meets expectations. Only after passing the interception validation does the model formally execute the task.
Pre-execution Interception is an important practice in AI safety engineering and falls under the category of "Guardrails" technology. As AI model capabilities grow stronger — especially when they gain "agency" through code execution, API calls, file operations, and other action capabilities — output safety becomes critically important. Common guardrail strategies include: input filtering (detecting and blocking malicious prompt injection), output review (checking generated content for harmful information), behavioral sandboxing (limiting the range of operations a model can perform), and human approval steps (requiring manual confirmation for critical operations). In multimodal scenarios, security risks expand further — for example, a model might extract sensitive information from images or generate inappropriate content based on visual input — so the design of pre-execution interception needs to cover additional risk dimensions.
This design is extremely important in real-world applications — once multimodal models gain stronger execution capabilities, establishing proper safety boundaries becomes especially critical.
Test Results and Model Performance
Interface Generation and Content Monitoring
In actual testing, when a user requested "I need an interface," the model was able to generate a fairly complete interface design. When moving into specific business scenarios, the model could also identify relevant content and automatically generate monitoring dashboards.
Additionally, the system's summarization feature went through a complete node flow — the model could produce structured summaries of conversation content and store them in a summary repository, achieving a complete closed loop from input to output.
Multi-Model Comparison: Differences Between GML 5.2 and DeepSeek V4
The developer candidly noted that different models currently show varying performance across complex projects. In some scenarios, a particular model "really excels," while in others, adjustments and optimizations are needed. DeepSeek V4 demonstrated faster response times in this test, which may be related to the current number of users and server load.
There are multiple technical reasons behind why different models perform differently across scenarios. First, there are differences in training data distribution: each model's pre-training corpus has different emphases — some are stronger in code generation, while others excel in natural language understanding. Second, there are architectural differences: DeepSeek V4 employs a MoE (Mixture of Experts) architecture that activates only a subset of parameters during inference, enabling faster response times while maintaining high-quality output. Response speed is also affected by inference infrastructure, including GPU type, quantization strategy, KV Cache optimization, and batch scheduling algorithms. Furthermore, the number of concurrent users on the server side directly impacts queue times and computational resource allocation for each request, which explains why "user count and server load" can significantly affect the actual experience.
Deployment Configuration Key Points
From a deployment perspective, the current version (0.2) already provides the following key configuration options:
- Default option values: The platform provides preset model parameter configurations, lowering the barrier to entry
- Admin account management: Supports independent permission controls
- Encryption keys: Sensitive information such as API keys is encrypted
- Layered architecture: Supports layered security strategies when exposing external interfaces
In AI application deployment, API key management is a critical security concern. Large model APIs are typically billed by usage, and a leaked key can lead to serious financial losses and data security risks. Common key protection measures include: using environment variables instead of hardcoded key storage, encrypting keys with algorithms like AES-256, and implementing key rotation policies. A layered security architecture refers to using multiple layers of protection — such as API gateways, rate limiting, authentication (e.g., OAuth 2.0), and IP whitelisting — when the system exposes external interfaces, ensuring that only authorized users can access the underlying model capabilities. This layered design follows the "Defense in Depth" security principle.
Additionally, since some features depend on downloading additional plugins, there may be some loading delays. The developer specifically implemented preloading acceleration optimizations to improve the overall user experience.
Summary and Outlook
This hands-on test validated an important technical approach: through workflow orchestration, pure text large language models can be effectively upgraded into systems with multimodal processing capabilities. Both GML 5.2 and DeepSeek V4 successfully completed the full pipeline on the OneBlockBase platform, proving the feasibility of this approach.
For developers, this means they don't have to wait for native multimodal models to be released — through thoughtful architectural design, existing text models can be made to "see" and "understand" visual information. As more models are integrated and workflows are refined, this modular multimodal approach is expected to be deployed in an increasing number of real-world projects.
Key Takeaways
Related articles
DeepSeek + Cline Setup Guide: A $1.50 Alternative to $20/Month AI Coding Subscriptions
Step-by-step guide to configuring DeepSeek API with VS Code plugin Cline, including API Key setup, Plan/Act dual-model strategy, and project management files for a $1.50 AI coding alternative.
5 Steps to Connect Codex with DeepSeek — No GPT Account Required
Step-by-step tutorial: Connect Codex to DeepSeek API via CC Switch in 5 steps. No GPT account needed — use AI coding features like code completion and Skill plugins at lower cost.

A Systematic Guide to Claude Code: From Deployment to Architectural Analysis of 510K Lines of Source Code
A systematic guide to Claude Code covering environment deployment, domestic model integration, six core systems (memory, multi-Agent, etc.), a full-stack ChatBot project, and eight design patterns from 510K lines of open-source code.