GPT-5.5 Instant's Medical Q&A Capabilities Now Match Frontier Reasoning Models
GPT-5.5 Instant's Medical Q&A Capabili…
GPT-5.5 Instant matches frontier reasoning models in medical Q&A, now free for all ChatGPT users.
OpenAI announced that GPT-5.5 Instant now matches its frontier Thinking models in health Q&A, serving over 230 million weekly consultations. Key improvements span emergency recognition, proactive follow-up questioning, honest uncertainty expression, and plain-language explanations. Backed by physician-led evaluation, these capabilities are available to all free users, offering significant public health value while raising important questions about AI safety boundaries in healthcare.
230 Million Health Consultations Per Week — How Is OpenAI Responding?
OpenAI recently announced that GPT-5.5 Instant has caught up with its frontier Thinking models on health-related questions. This is significant — ChatGPT handles over 230 million health and wellness consultations per week, a number roughly equivalent to the population of a mid-sized country.
To clarify the terminology: GPT-5.5 Instant is a lightweight, fast-response model in OpenAI's product lineup, while Thinking models (such as the o1 and o3 series) are frontier models with deep reasoning capabilities that perform multi-step Chain of Thought reasoning before generating a response. Thinking models typically excel at complex reasoning tasks but are slower and more computationally expensive. The fact that GPT-5.5 Instant can match Thinking models in health Q&A means that through targeted training and optimization, a lightweight model can achieve performance close to deep reasoning models in specific vertical domains — while maintaining faster response times and lower operational costs.
When AI becomes the "first health advisor" for hundreds of millions of people, model accuracy and reliability in medical scenarios are no longer just technical metrics — they become a major public health concern.
Four Key Medical Capability Improvements in GPT-5.5 Instant
According to information disclosed by OpenAI, GPT-5.5 Instant has achieved significant progress across four key dimensions in health Q&A:
Enhanced Emergency Situation Recognition
The model can now better identify signals in user descriptions that may require urgent medical attention. When users describe critical symptoms like chest pain or difficulty breathing, the model can more accurately assess severity and promptly recommend seeking professional medical help, rather than simply offering generic health advice.
From a technical perspective, emergency recognition is essentially a medical triage problem. In traditional healthcare systems, triage is performed by specially trained nurses or emergency physicians who use standardized triage scales (such as the Manchester Triage System or the Emergency Severity Index, ESI) to determine patient urgency. For AI to achieve similar capabilities, it needs to understand the clinical significance of symptom combinations — for example, chest pain alone might be a muscle strain, but chest pain accompanied by radiating left arm pain, sweating, and shortness of breath is highly suggestive of acute myocardial infarction. The model needs to learn to recognize these "Red Flag Symptoms" combination patterns to make appropriate urgency assessments.
Proactive Follow-Up for Relevant Context
In medical consultations, completeness of information is critical. GPT-5.5 Instant has learned to proactively ask about background information related to symptoms — like an experienced physician would — including symptom duration, medical history, current medications, and more. This "follow-up" capability significantly improves the relevance and accuracy of responses.
In clinical medicine, physicians typically follow structured history-taking frameworks to collect information. The most commonly used is the OLDCARTS framework: Onset, Location, Duration, Character, Aggravating/Alleviating factors, Related symptoms, Timing, and Severity. Additionally, past medical history, family history, medication history, and allergy history are key diagnostic clues. When an AI model learns to proactively ask about this information, it is essentially simulating a physician's clinical reasoning process — filling in fragmented user descriptions to build a complete clinical picture, thereby providing more targeted health advice.
Honest Expression of Uncertainty
Medicine is full of uncertainty, and one of the most dangerous behaviors an AI can exhibit is appearing overly confident when it shouldn't be. GPT-5.5 Instant has shown notable improvement in this area, better communicating to users which judgments are well-supported and which carry uncertainty, helping users make more rational decisions.
In machine learning, whether a model's confidence in its predictions matches its actual accuracy is known as the "calibration" problem. A well-calibrated model, when expressing 80% confidence, should indeed be correct about 80% of the time. Early large language models were widely plagued by "overconfidence" — appearing highly certain even in incorrect answers. This is especially dangerous in medical scenarios, potentially causing users to dismiss serious symptoms or take inappropriate actions. Improving uncertainty expression involves specialized training during RLHF (Reinforcement Learning from Human Feedback), teaching the model to distinguish between "judgments supported by sufficient evidence" and "speculations that require further examination to confirm," and to communicate this distinction appropriately to users.
Plain-Language Explanation of Complex Information
Medical terminology is often opaque to ordinary users. The new model performs better at translating complex medical concepts into easily understandable language, lowering the barrier to comprehending health information.
Physician-Led Evaluation Is the Key
OpenAI specifically emphasized that behind these medical capability improvements, physician-led evaluation played a crucial role.
Advances in AI for healthcare cannot rely solely on algorithm engineers working in isolation — professional medical practitioners must be deeply involved in model evaluation and optimization. Physicians can assess the accuracy, safety, and practicality of model responses from the perspective of clinical practice. This interdisciplinary collaboration model may become the standard paradigm for AI medical applications.
Specifically, physician-led AI evaluation systems typically encompass multiple layers: first, clinical accuracy assessment, where specialists across disciplines judge whether AI responses align with current medical evidence and clinical guidelines; second, safety assessment, identifying responses that could lead patients to delay treatment or take harmful actions; third, communication quality assessment, evaluating whether information is conveyed clearly and whether the patient's health literacy level has been considered. This evaluation model draws on the principles of Evidence-Based Medicine, combining clinical expertise with AI technology development. In practice, this typically requires establishing multidisciplinary physician review teams, developing standardized scoring rubrics, and conducting large-scale blinded evaluation experiments to ensure objectivity and reproducibility of results.
The Inclusive Value of Free Access
Interestingly, GPT-5.5 Instant is available to all free ChatGPT users. This means these medical Q&A improvements benefit not just paying subscribers but can reach a much broader population — including those who may struggle to access quality medical consultation due to financial constraints.
In a world where healthcare resources are extremely unevenly distributed, the potential social value of a free, high-quality AI health assistant is immeasurable. According to World Health Organization data, roughly half the global population lacks access to basic healthcare services. Low-income countries average fewer than 10 physicians per 10,000 people, while high-income countries exceed 30. In many developing regions, patients may need to travel hours to see a doctor and face language barriers and prohibitive costs. In this context, a free AI health assistant can serve as a supplementary channel for primary health information, helping users with preliminary symptom assessment and health education.
Of course, this also raises the bar for model safety, since users include a large number of ordinary people who may lack medical knowledge and could over-rely on AI advice. How to provide useful information while preventing users from treating AI suggestions as medical orders is an issue that demands ongoing attention in product design.
A Clear-Eyed View of AI Healthcare's Boundaries
Despite GPT-5.5 Instant's impressive progress, we must remain clear-headed: AI health assistants are supplementary tools for information access, not replacements for professional medical diagnosis. The claim of "matching frontier Thinking models" itself warrants more details for verification — the specific evaluation benchmarks, test scope, and comparison methodologies all deserve closer scrutiny.
Looking at the broader trend, OpenAI is positioning healthcare as one of the key focus areas for AI capability improvement. The 230 million weekly health consultations represent both an enormous responsibility and a powerful driver for continuous model evolution. This data itself creates a unique flywheel effect: massive real-user interactions provide rich training signals for model optimization, while improved model capabilities attract more users, further expanding the data scale. How to leverage this data for model improvement while protecting user privacy will be a core challenge that OpenAI must continuously balance.
Key Takeaways
Related articles
Deep Dive into the 198-Page Codex Chinese Manual: A Complete Guide from Beginner to Advanced
Deep breakdown of ByteDance's internal 198-page Codex Chinese manual covering installation, Commands, MCP workflows, Skills templates, multi-Agent collaboration, and background task scheduling.
Trae AI Coding Tool: Complete Guide to Download, Installation, and Getting Started
Complete guide to ByteDance's Trae AI editor: core features, download & installation, Python setup, and AI chat coding. Free, Chinese-native, no VPN needed.
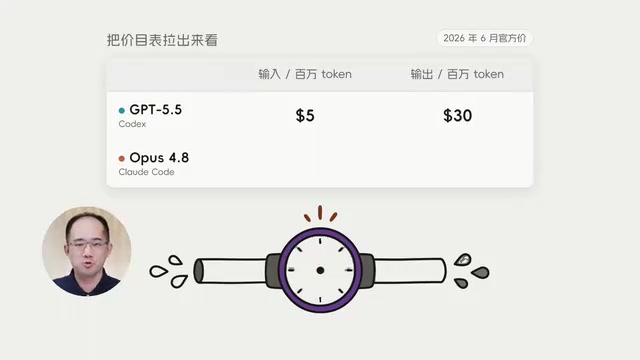
Codex vs Claude Code Cost Comparison: Breaking Down the Real Reasons Behind the 10x Price Gap
Codex costs $15 vs Claude Code's $155 for the same task. We break down the 10x price gap across Token pricing, consumption, and work patterns with practical tips.