GPT-5.5 Replaces OCR Pipelines: 23,000+ ChinaRxiv Papers Fully Translated to English
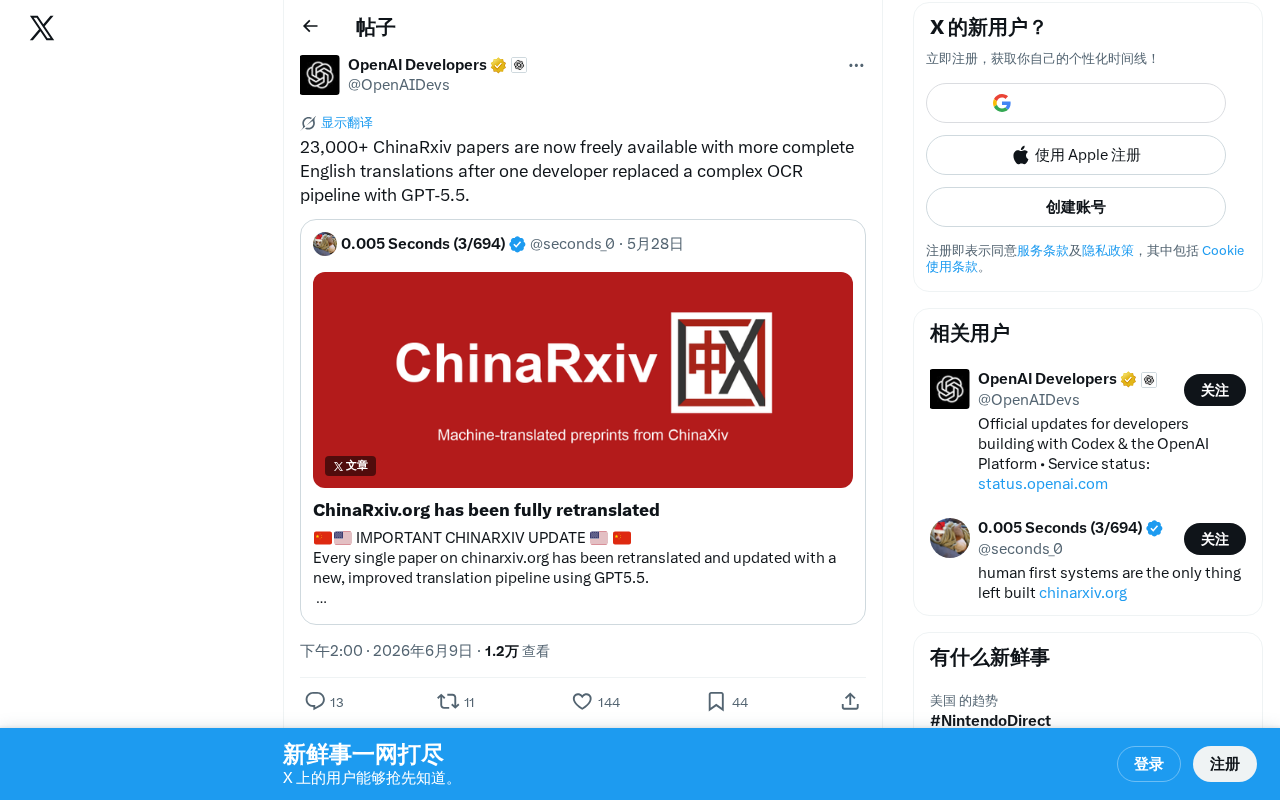
GPT-5.5 replaces OCR pipelines to translate 23,000+ Chinese academic papers into English for free.
A solo developer used GPT-5.5 to replace a complex OCR pipeline and translate over 23,000 ChinaRxiv Chinese academic papers into English, releasing them for free. The approach dramatically simplified the workflow, improved translation quality, and showcased how LLMs are reshaping document processing and individual productivity in academia.
Overview
Recently, a developer completed a remarkable engineering feat: fully translating over 23,000 academic papers from ChinaRxiv (China's preprint platform) into English and making them freely available to the global community. What makes this even more noteworthy is that the developer replaced a complex OCR (Optical Character Recognition) processing pipeline with GPT-5.5, dramatically simplifying the entire workflow while significantly improving translation quality.
ChinaRxiv is a preprint service platform hosted by the Chinese Academy of Sciences, housing a vast collection of cutting-edge research from Chinese scientists. However, the language barrier has long been a major obstacle preventing these papers from reaching the international academic community. This project offers a highly instructive case study in breaking down the barriers between Chinese and English academic communication.
From Complex OCR to GPT-5.5: A Fundamental Shift in Technical Approach
The Limitations of Traditional OCR Pipelines
Previously, translating Chinese academic papers typically required a complex OCR pipeline. This pipeline generally involved multiple stages: PDF parsing, layout analysis, text region detection, OCR text recognition, post-processing error correction, and machine translation. Each stage could introduce errors, especially when processing academic papers containing mathematical formulas, charts, and special symbols — errors would cascade through the pipeline, ultimately resulting in poor translation quality.
The layout complexity of Chinese academic papers made this problem even worse — two-column layouts, mixed Chinese-English text, and diverse reference formats all pushed traditional OCR solutions to their limits.
How GPT-5.5 Achieved a Paradigm Shift
The developer's approach can only be described as a paradigm shift — directly replacing the entire OCR pipeline with GPT-5.5. As OpenAI's latest large language model, GPT-5.5 possesses powerful multimodal understanding capabilities, enabling it to directly "read" content from PDF documents without going through traditional OCR recognition steps.
This means:
- Dramatically simplified workflow: From a multi-step pipeline reduced to a single model call, slashing development and maintenance costs
- Improved translation quality: GPT-5.5 can understand the contextual semantics of academic papers rather than translating mechanically word by word
- Significantly reduced error rates: Eliminating OCR recognition errors prevents error cascading through the pipeline
Far-Reaching Implications for Open Access in Academia
Breaking Language Barriers to Promote International Academic Exchange
China produces a massive volume of high-quality research papers every year, but a significant portion are published in Chinese, making them largely inaccessible to the international academic community. The free English translation of over 23,000 papers effectively opens a window for global researchers to access China's cutting-edge research.
This benefits not only international academic exchange but also helps Chinese research gain broader citations and recognition. For international scholars studying China-specific topics — such as traditional Chinese medicine, Chinese geology, or China's socioeconomic landscape — this translated corpus is especially valuable.
Individual Developers Redefining Productivity with AI
It's worth highlighting that this entire project was completed by a single developer working independently. In the era of large language models, individual developers armed with powerful AI tools can accomplish tasks that previously required entire teams or institutions. This once again confirms AI's role as a "capability multiplier" — it doesn't just lower technical barriers; it fundamentally redefines the upper limits of individual productivity.
Questions Worth Considering
While this project is exciting, several questions deserve attention:
- Translation accuracy: Academic papers demand extremely precise terminology. Whether GPT-5.5's translations can meet professional peer-review-level accuracy still requires systematic evaluation by the academic community
- Cost sustainability: The API costs of running GPT-5.5 on over 23,000 papers are substantial. Whether this model is sustainable in the long term remains an open question
- Copyright and compliance: Whether large-scale translation and redistribution of preprint papers raises copyright issues requires careful attention to ChinaRxiv's terms of use
- Replicability: Whether this approach can be extended to preprint platforms in other languages, such as Japan's J-STAGE or Korea's KCI
Conclusion
This case vividly demonstrates the transformative power of large language models in real-world applications. GPT-5.5 isn't merely a "better translation tool" — it fundamentally changes the technical paradigm for processing unstructured documents, shifting from complex multi-step engineering pipelines to end-to-end processing with a single model. When AI capabilities become powerful enough, much of the traditional engineering complexity simply becomes unnecessary.
For the academic world, the open translation of these 23,000+ papers is just the beginning. As large model capabilities continue to improve and costs continue to decline, we have every reason to look forward to an academic future with lower language barriers and freer knowledge flow.
Related articles

Codex VS Claude Code: The Token Economics Behind a 10x Price Gap
Same coding task: Codex costs $15, Claude Code costs $155. Deep dive into the real reasons behind the 10x gap — it's not pricing, it's token volume, output style, and context strategy.
Gemma 4 Open-Source Model Local Deployment Guide: Ollama Installation & Mobile Setup
Step-by-step guide to deploying Google's Gemma 4 open-source model locally with Ollama and running the lightweight version on mobile with tool calling support.
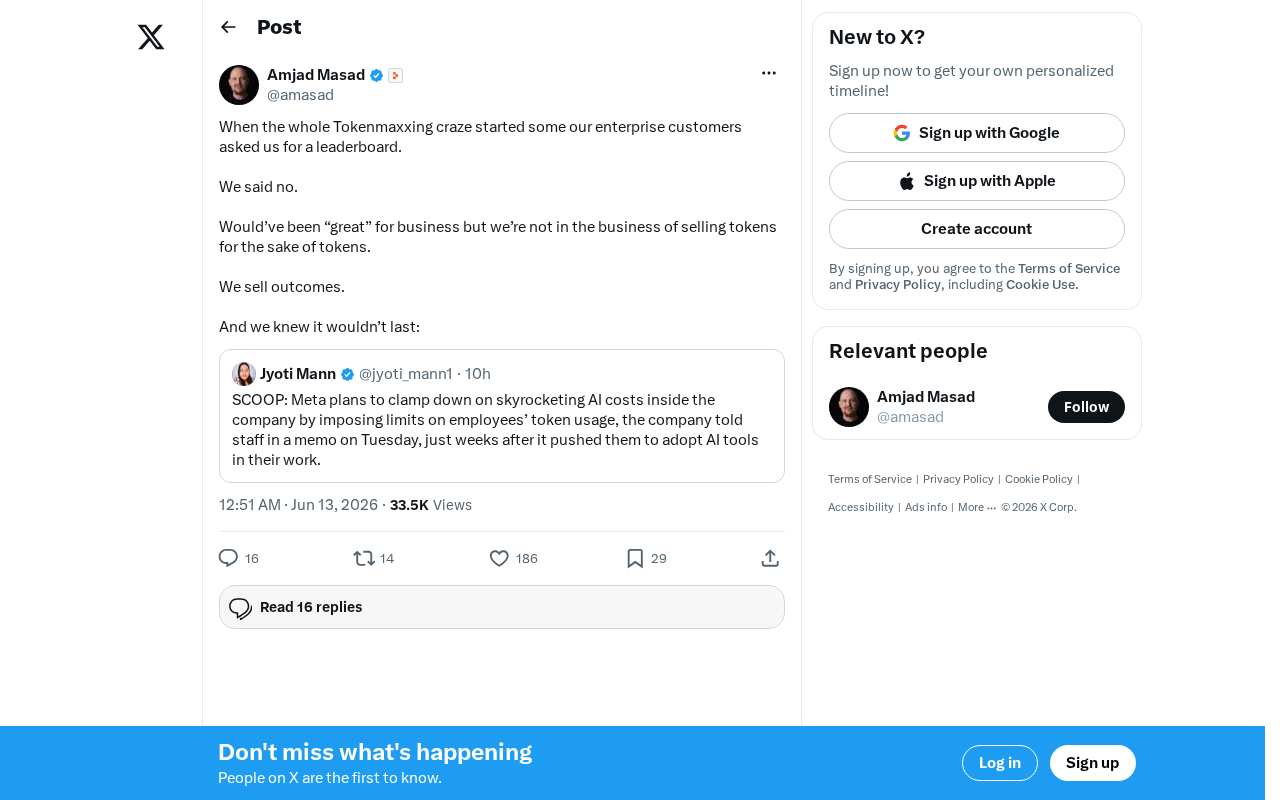
The Decline of Tokenmaxxing: Why Selling Outcomes Matters More Than Selling Tokens
The Tokenmaxxing craze is fading as enterprise AI procurement shifts from chasing Token counts to focusing on actual business outcomes. Learn why outcome-based AI evaluation is the right approach.